基于贪婪值表征的多无人搬运车调度方法及系统
本发明属于agv调度领域,具体涉及一种基于贪婪值表征的多无人搬运车调度方法及系统。
背景技术:
1、许多现实场景中的决策问题,如交通调度、多传感器协同、机器人集群协作等,都可以被建模为多智能体协同决策问题。在此类问题中,多个决策主体(即智能体)以团队形式与环境进行交互,并从环境中获取反馈信息(包括环境给与智能体团队的奖惩信息与环境的状态变化)。在多智能体强化学习中,算法根据该反馈信息计算每个动作的目标值函数,以便对团队决策进行评价。与此同时,算法为智能体团队构造一个联合值函数,对该目标值函数进行近似。智能体团队需要根据联合值函数推断每个智能体的团队贡献,从而对每个智能体的策略进行单独更新,该问题被称为效用分配。
2、值分解是一种最简单高效的效用分配方法,在此类方法中,联合动作值函数通过一个混合器模块被分解为每个智能体的效用函数。然而,当前的值分解方法通常借助线性分解或单调分解来分解联合值函数,这两种分解方式在联合值函数与效用函数的关系中引入了线性或单调性约束,导致联合值函数无法表征任意的目标值函数。联合值函数的表征缺陷引入了相对过度泛化问题,即联合策略存在多种收敛结果,可能会收敛到非最优策略上,从而导致非最优协作问题。由于线性值分解和单调值分解被广泛应用于各种多智能体协同决策问题方法,在线性值分解和单调值分解的基础上解决相对过度泛化具有重要意义。
3、如何实现多无人搬运车(automated guided vehicle,agv)的最优协同调度在实际中具有重要的意义,现有技术没有给出相关的技术方案。
技术实现思路
1、本发明的目的在于解决线性值分解算法中存在的相对过度泛化问题,提供一种基于贪婪值表征的多无人搬运车调度方法,能够消除多智能体调度算法的非最优收敛点,在环境得到充分探索的前提下实现多agv的最优协同调度。
2、为实现上述目的,本发明采用如下技术方案:
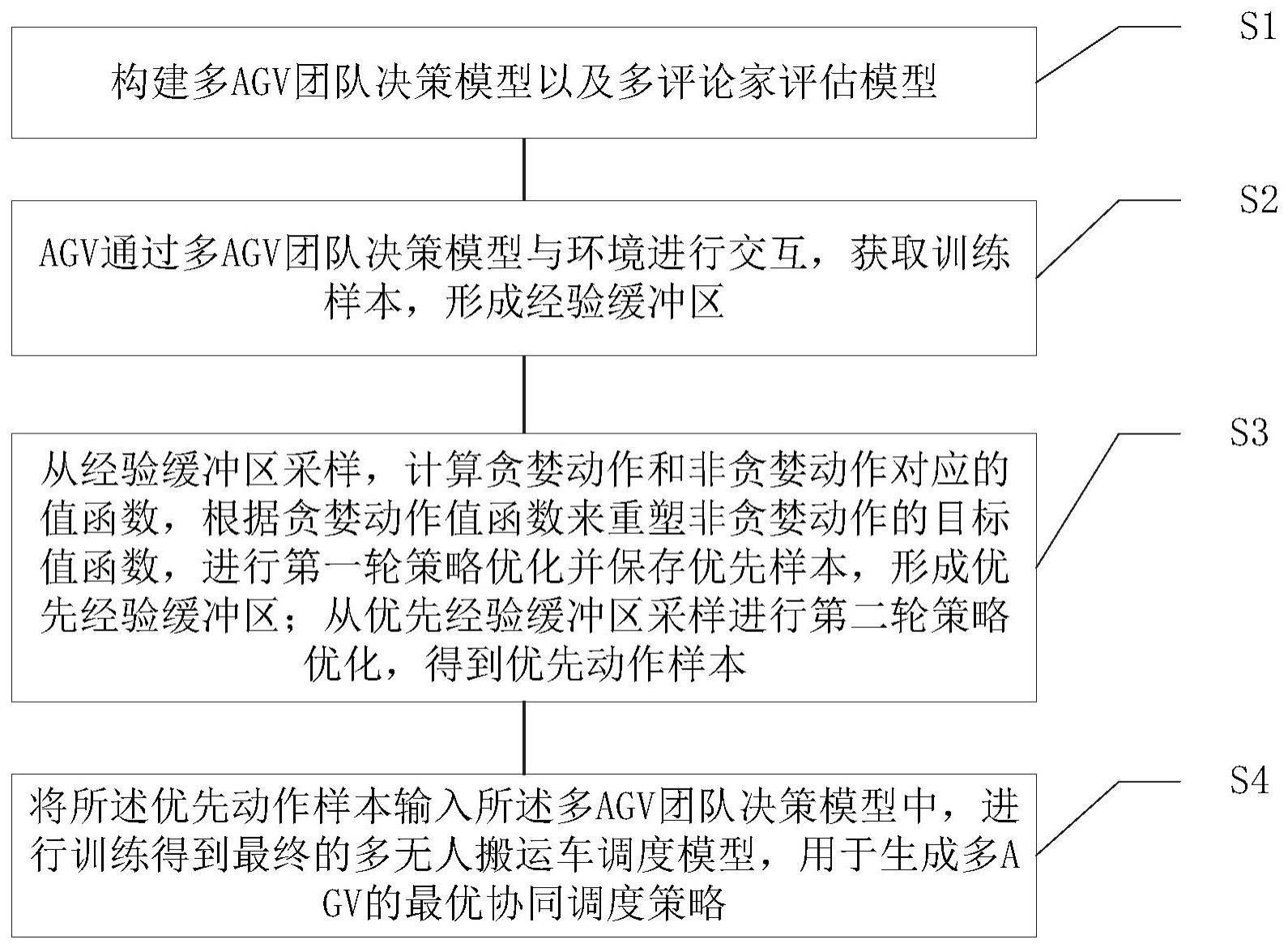
3、本发明第一方面是提供一种基于贪婪值表征的多无人搬运车调度方法,包括:
4、构建多agv团队决策模型以及多评论家评估模型;
5、agv通过多agv团队决策模型与环境进行交互,获取训练样本,形成经验缓冲区;
6、从经验缓冲区采样,计算贪婪动作和非贪婪动作对应的值函数,根据贪婪动作值函数来重塑非贪婪动作的目标值函数,进行第一轮策略优化并保存优先样本,形成优先经验缓冲区;从优先经验缓冲区采样进行第二轮策略优化,得到优先动作样本;
7、将所述优先动作样本输入所述多agv团队决策模型中,进行训练得到最终的多无人搬运车调度模型,用于生成多agv的最优协同调度策略。
8、作为本发明进一步改进,所述构建多agv团队决策模型以及多评论家评估模型,包括:
9、利用循环神经网络为每一个决策主体构建一个独立的效用函数模型,所述效用函数模型以当前时间步的局部观测信息、agv的动作、以及历史隐变量作为输入,以相应动作的效用值和新的历史隐变量作为输出;
10、利用线性/单调混合器将不同agv的效用值混合,得到联合动作值,进而构建多agv团队决策模型;
11、利用多个多层感知机构建多个评论家模型,每个评论家模型以环境状态和全体agv的联合动作为输入,输出该状态下的agv团队行为评估值。
12、作为本发明进一步改进,所述agv通过多agv团队决策模型与环境进行交互,获取训练样本,形成经验缓冲区;包括:
13、agv从环境中获取观测信息,将所述观测信息与上一个时间步的历史隐变量、以及所有可行动作输入多agv团队决策模型,更新历史隐变量,并得到可行动作的联合动作值;
14、从联合动作值中根据探索-利用策略选取合适的动作,与环境进行交互;
15、收集环境反馈,将环境状态、观测信息、所采取的动作、获得的团队奖励存入经验缓冲区;
16、agv根据新收集到的观测信息,重复上述步骤进行下一轮的交互,直至获得所有训练样本,形成经验缓冲区。
17、作为本发明进一步改进,所述与环境进行交互中,对于每次交互的第一个时间步,历史隐变量通过全0向量来表示,在经验缓冲区中保存一次与环境交互产生的完整轨迹信息,并根据初始的全0向量推导出每一个时间步的历史隐变量。
18、作为本发明进一步改进,所述从经验缓冲区采样,计算贪婪动作和非贪婪动作对应的值函数,根据贪婪动作值函数来重塑非贪婪动作的目标值函数,进行第一轮策略优化并保存优先样本,形成优先经验缓冲区,包括:
19、从经验缓冲区以轨迹为单位随机采样一批训练样本,计算该批样本对应的目标值函数;
20、对于非贪婪动作对应的样本,若该动作的目标值函数比贪婪动作的联合值函数q低,则将该动作的目标值函数替换为q-b,其中b为预先设定的偏置值;
21、计算多agv团队决策模型输出的联合动作值与修改后目标动作值的误差,更新多agv团队决策模型;
22、通过多评论家模型计算贪婪动作评估值的均值和方差,对于非贪婪动作对应的样本,根据该均值和方差计算其评估值高于贪婪动作评估值的置信度,将置信度超过一定阈值的样本记为优先样本;
23、将优先样本所在的轨迹存入优先经验缓冲区,并将轨迹中所含优先样本的数量记为该轨迹的优先级。
24、作为本发明进一步改进,所述从优先经验缓冲区采样进行第二轮策略优化,得到优先动作样本,包括:
25、从优先经验缓冲区以轨迹为单位无放回取出优先级最高的一批训练样本,参照第一轮策略优化进行第二轮策略优化;
26、通过混合第一轮的随机样本训练和第二轮的优先样本训练,得到优先样本。
27、作为本发明进一步改进,所述训练得到最终的多无人搬运车调度模型之后还包括:
28、根据多agv的最优协同调度策略更新多评论家网络模型,其包括:
29、在每几轮策略优化迭代结束后,进行多轮测试;
30、测试过程中,agv采用贪婪策略与环境进行交互,将交互得到的轨迹存入经验缓冲区;
31、从经验缓冲区采样多批样本,每批样本送入不同的评论家网络;对于每个评论家网络,计算目标评估值和网络输出值之间的误差,对多评论家网络模型进行更新模型;
32、其中,每个评论家网络通过不同的样本进行训练。
33、本发明第二方面是提供一种基于贪婪值表征的多无人搬运车调度系统,包括:
34、构建模块,用于构建多agv团队决策模型以及多评论家评估模型;
35、交互模块,用于agv通过多agv团队决策模型与环境进行交互,获取训练样本,形成经验缓冲区;
36、样本优化模块,用于从经验缓冲区采样,计算贪婪动作和非贪婪动作对应的值函数,根据贪婪动作值函数来重塑非贪婪动作的目标值函数,进行第一轮策略优化并保存优先样本,形成优先经验缓冲区;从优先经验缓冲区采样进行第二轮策略优化,得到优先动作样本;
37、模型训练模块,用于将所述优先动作样本输入所述多agv团队决策模型中,进行训练得到最终的多无人搬运车调度模型,用于生成多agv的最优协同调度策略。
38、本发明第三方面是提供一种电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述基于贪婪值表征的多无人搬运车调度方法。
39、本发明第四方面是提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述基于贪婪值表征的多无人搬运车调度方法。
40、与现有技术相比,本发明具有如下技术效果:
41、本发明基于贪婪值表征的多无人搬运车调度方法,解决了共享奖励函数设定下的多agv非最优协作困境。提出的替换非贪婪动作目标值函数的方法通过放弃对目标值函数的完整表征,消除了最优动作与贪婪动作联合值函数的差值对非最优动作目标值函数的依赖;与此同时,通过混合随机样本与优先样本的两轮训练方式,提高了优先样本在训练中的比重,消除了非最优收敛点,解决了表征缺陷带来的相对过度泛化问题。此外,本发明引入了多评论家网络,能够根据值估计的可靠性筛选优先样本,实现最优性与稳定性的自适应权衡。能够消除多智能体调度算法的非最优收敛点,在环境得到充分探索的前提下实现多agv的最优协同调度。
- 还没有人留言评论。精彩留言会获得点赞!