基于Transformer和数据增强的网络媒体多模态信息抽取方法与流程
本发明属于视觉语言信息抽取,具体涉及一种基于transformer和数据增强的网络媒体多模态信息抽取方法。
背景技术:
1、对于非结构化的文本的处理,命名实体识别和关系提取是信息提取和知识库构建前提的主要任务,这些任务主要目的是抽取知识三元组来构建图数据结构进而完成知识图谱创建。但随着社交媒体帖子呈现多模式化的趋势,由于一些文本成分只有结合视觉信息才能被理解,针对文本及其伴随图像的多模态命名实体识别(mner)以及多模态关系抽取(mre)受到越来越多的关注,它通过将图像作为额外的输入,极大地扩展了基于文本的模型,因为视觉上下文有助于解决模糊的多义单词。同时,研究表明对象级视觉融合对于mner和mre任务也是十分重要,能更好地对齐文本和图像的objects,从而实现多模态对齐。
2、目前针对多模态信息抽取领域,transformers正在成为最有未来的技术路线,其受益于自注意模块,最初是为nlp提出的特定序列表示学习的突破性模型,在各种nlp任务中实现了最先进的技术。同时,视觉上的基于transformer的vision transformer(vit)也取得了巨大的成果,将transformers技术扩展到除了文本的其他领域上,从而在多模态的各个模态上去应用该技术,能更好的对齐模态之间的信息以及模态融合。
3、但目前,多模态信息抽取任务严重依赖于对大量对应领域的图像-文本数据,对于社交媒体帖子数据就存在严重的不足,尤其是多模态关系抽取领域的数据。因此,如何进一步提高数据效率成了多模态信息抽取相关子任务亟待解决的技术问题。
4、多模态信息抽取是一种较新的技术领域,对于数据处理方法、各个模态架构的设计以及模态融合等都大不一样,在对应领域上的数据不足也成为了该领域的一大问题;选择一条最优的技术路线以及数据高效处理、充分利用成了此领域最主要的问题。到目前为止,多模态信息抽取的普遍技术缺点如下:
5、1.多模态信息抽取之前的一般基线方法是cnn feature+standard transformerencoder,文本处理使用基于transformer的自注意力方法,而对于视觉领域的处理使用的是非cnn、rnn等特征抽取方法,这就造成了模态之间的技术裂痕,也就是深度网络无法很好地去对齐文本视觉等模态。
6、2.视觉上的处理方式上,大多数直接用基于预训练的整个图像特征输入的方式,然而其严重依赖于对大量额外注释的图像-文本相关性语料库的预训练,只关注整个图像,而忽略了相关对象级视觉融合的偏差;同时,对于多模态预训练的数据集和领域级的数据存在大量的偏差,这就导致抽取的效率以及准确率难以提升。
7、3.基于特定领域的数据规模不足的问题,直接影响到模型无法得到充分的训练,虽然多模态的预训练能初始化数据特征,也就是扩充数据,但其数据领域存在严重的不匹配,特定领域上所需要的大量数据会花费大量的人力物力,那么从技术方面入手对数据的增强成了当下最为重要的技术需求。
技术实现思路
1、鉴于上述,本发明提供了一种基于transformer和数据增强的网络媒体多模态信息抽取方法,其通过对比选择出多模态信息抽取的实体抽取和关系抽取最优基线,并用数据增强相关技术去解决特定领域上的数据不足等问题,充分利用已有标注好的数据,来使得模型得到充分的训练。
2、一种基于transformer和数据增强的网络媒体多模态信息抽取方法,包括如下步骤:
3、(1)获取包含大量文本及其对应原始图像内在的数据集;
4、(2)对数据集进行预处理;
5、(3)对数据集进行数据增强处理;
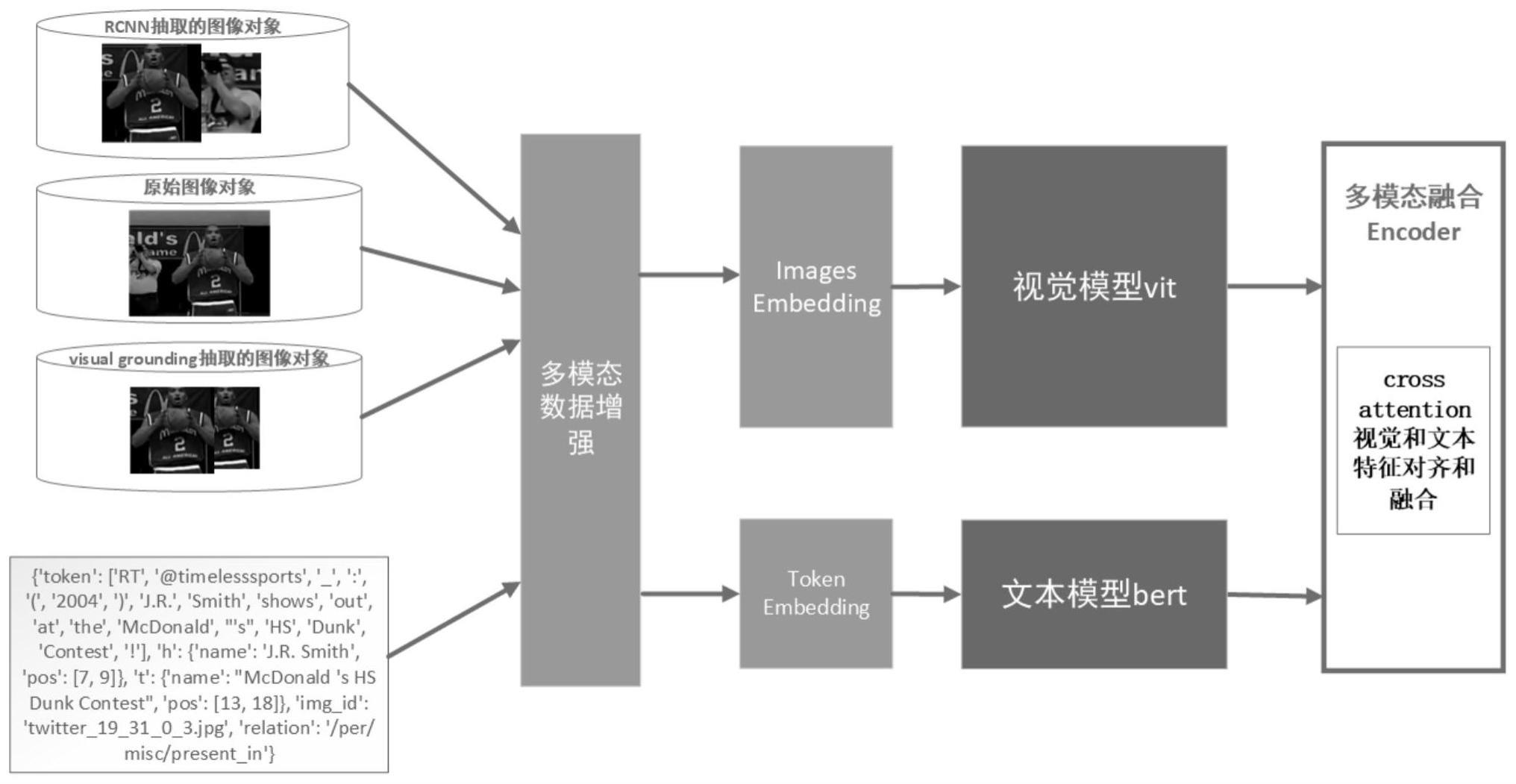
6、(4)构建基于完全transformer的多模态模型框架,其包括:
7、视觉端,通过对图像序列化以及transformer的自注意力机制后得到图像特征;
8、文本端,通过对文本序列化以及transformer的自注意力机制后得到文本特征;
9、多模态融合模块,对视觉端和文本端的transformer后三层采用cross attention方式将图像特征和文本特征进行对齐和融合;
10、信息抽取模块,根据对齐融合后的图像特征和文本特征进行信息抽取;
11、(5)利用数据集对上述多模态模型框架进行训练,进而将需要进行信息抽取的文本及其图像输入至训练好的模型中,从而直接抽取输出相应的信息。
12、进一步地,所述数据集中的文本包含所有token、文本中的实体头、实体尾和实体关系类型以及文本对应的图片id。
13、进一步地,所述步骤(2)对数据集进行预处理即采用基于对象的图像处理方法,对于数据集中的图像,使用基于r-cnn(region-convolutional neural networks)和visualgrounding的处理技术检测图像中的子对象,获取该特定对象对应截取出来的子图作为对象图片。
14、进一步地,所述步骤(3)对数据集进行数据增强处理,即对于训练的同一batch内的数据进行合并来生成新的数据,对于图像则采用重叠的方式来完成图像融合,对于文本则采用拼接的方式来实现增强处理;在具体数据增强处理过程中将batch内的一半数据与另一半数据进行图像融合及文本拼接,图像融合则使用对应融合的方式,即原图与原图融合,对象图片与对象图片融合。
15、进一步地,所述视觉端采用clip(cross-modal learning to rank)模型图像编码器中的vit(vision transformer),其首先将图像重塑为一个patches序列,然后通过对该patches序列添加一个可学习嵌入和一个位置嵌入后输入至transformer中进行处理,输出得到图像特征。
16、进一步地,所述文本端采用bert(bidirectional encoder representation fromtransformers)去迁移自然语言处理模型,模型的输入向量由三部分组成,分别为tokenembedding、segment embedding和position embedding,其中token embedding为文本的token序列对应的嵌入向量序列;segment embedding中只有0和1两个值,用于区分文本中两个句子,句子a编码为0,句子b编码为1;position embedding用于表示每个token在句子中的位置,同一个token在不同位置中它的embedding是不同的;最后将这三组embedding按元素值相加后输入至transformer中进行处理,输出得到文本特征。
17、进一步地,所述transformer由多层编码结构级联组成,每一层编码结构由多头自注意力机制层和前馈神经网络组成,其中多头自注意力机制层的输出与输入通过残差连接和层归一化处理后作为前馈神经网络的输入,前馈神经网络组的输出与输入通过残差连接和层归一化处理后作为编码结构的输出;所述多头自注意力机制层由多个self-attention组成,每个self-attention将多头自注意力机制层的输入分别与线性变换矩阵wq、wk和wv相乘对应得到查询向量矩阵q、键向量矩阵k、值向量矩阵v,然后通过以下公式计算出self-attention的输出结果,最后将多个self-attention的输出结果拼接后经过线性层即得到多头自注意力机制层的输出;
18、
19、其中:attention(q,k,v)为self-attention的输出结果,s为查询向量矩阵q的列数,t表示转置。
20、进一步地,所述多模态融合模块在视觉端和文本端的transformer最后三层编码结构的多头自注意力机制层中,将文本信息对应的键向量矩阵与视觉信息对应的键向量矩阵相叠加,将文本信息对应的值向量矩阵与视觉信息对应的值向量矩阵相叠加;同时在视觉端transformer最后三层编码结构的前馈神经网络中将相似性感知的聚合文本隐藏状态合并到视觉隐藏状态中,在文本端transformer最后三层编码结构的前馈神经网络中将相似性感知的聚合视觉隐藏状态合并到文本隐藏状态中,从而使图像特征与文本特征实现对齐融合。
21、进一步地,所述信息抽取模块采用关系抽取,抽取的信息包括实体以及实体之间的关系类别。
22、进一步地,所述步骤(5)中对多模态模型框架进行训练的过程如下:
23、5.1初始化模型参数,包括每一层的偏置向量和权值矩阵、学习率以及优化器;
24、5.2将数据集中的文本及其图像输入至模型,模型正向传播输出得到对应的信息抽取结果,计算该结果与标签之间的损失函数;
25、5.3根据损失函数利用优化器通过梯度下降法对模型参数不断迭代更新,直至损失函数收敛,训练完成。
26、基于上述技术方案,本发明具有以下有益技术效果:
27、1.本发明是完全基于transformer的多模态信息抽取模型框架。现有技术大部分的视觉模态模型都是基于卷积神经网络的处理方式,如使用resnet50等cnn技术,虽然可以很好地抽取视觉特征信息,但无法很好地处理多模态融合。本发明在视觉端使用基于transformer的视觉处理,类似clip的视觉部分处理模型,通过对视觉特征的序列处理来更好地完成视觉注意力模块的需求;文本模态模型使用的是目前最为广泛的transformer进行自然语言处理,这样文本和视觉都统一了数据处理框架,都是使用序列化的数据处理操作以及注意力机制,使得模型能够天然的融合不同模态的数据结构。
28、2.本发明是针对特定领域的多模态信息抽取的数据增强。虽然从单个模态出发的数据增强方法已存在很多且都很完善,但现有的多模态处理会规避或者使用简单的多模态数据增强技术,这是因为多模态的数据增强需要在统一各个对应模态情况下去更有效地处理数据。本发明通过对图像的融合以及文本的拼接方式,在不破坏原本的图像局部特征、位置特征和属性特征情况下以及在不破坏文本的逻辑结构下去完成多模态信息抽取的数据增强,从而使得模型能更好地、更有效地处理和学习具体场景的数据。
- 还没有人留言评论。精彩留言会获得点赞!