一种基于差分隐私的学习率自适应医疗图像识别方法
本发明涉及一种基于差分隐私的学习率自适应医疗图像识别方法,属于医疗图像识别。
背景技术:
1、在当今数字化时代,医疗物联网(internet ofmedical things,iomts)已经成为医疗领域的重要组成部分。医疗物联网在医疗图像识别中扮演着重要的角色,通过将传感器、设备和网络连接起来,实现医疗设备和系统之间的数据交换和协同工作。
2、在医疗物联网中应用联邦学习,可以及时发现患者的状况变化,从而支持决策制定和资源调配。具体来说,若是有一个癌症病人去一家医院治疗,通过已有的癌症数据,判断患者的状况变化,从而支持决策制定和资源调配。然而,一家医院的医疗数据可能不足以支持做出准确的判断,需要联合多家医院的医疗数据。
3、但是,这些医疗数据往往分布在各个医疗机构之间,形成了的数据孤岛。联邦学习可以利用多家医院的癌症数据来训练决策模型。由此,联邦学习提供更全面的信息支持和更准确的决策模型,从而提高应急决策的效率和准确性。
4、虽然联邦学习解决了数据孤岛问的问题,但是联邦学习在上传每个车载终端的模型会携带个人隐私。攻击者通过分析模型训练中的参数,如深度神经网络训练的权值,仍然可能泄露的隐私信息。
5、针对这一问题,一些学者提出了基于差分隐私的联邦学习算法,该算法在上传到服务器的模型参数中添加随机噪声,从而保证了数据的隐私性。因此,基于差分隐私的联邦学习算法具有明显的轻量级优势,具有更好的适用性和实用性。
6、但是,基于差分隐私的联邦学习算法是对每个客户端都是统一分配隐私预算。然而,在医疗应用场景中,医疗机构的地域分布不同,患者的人口分布也不同,各个机构对隐私的保密要求也不同。因此,统一分配隐私预算的假设是不切实际且无法生效。
技术实现思路
1、本发明的目的在于克服现有技术中的不足,提供一种基于差分隐私的学习率自适应医疗图像识别方法,可以实现多个医疗机构的数据融合,且能够起到个性化隐私保护的作用。
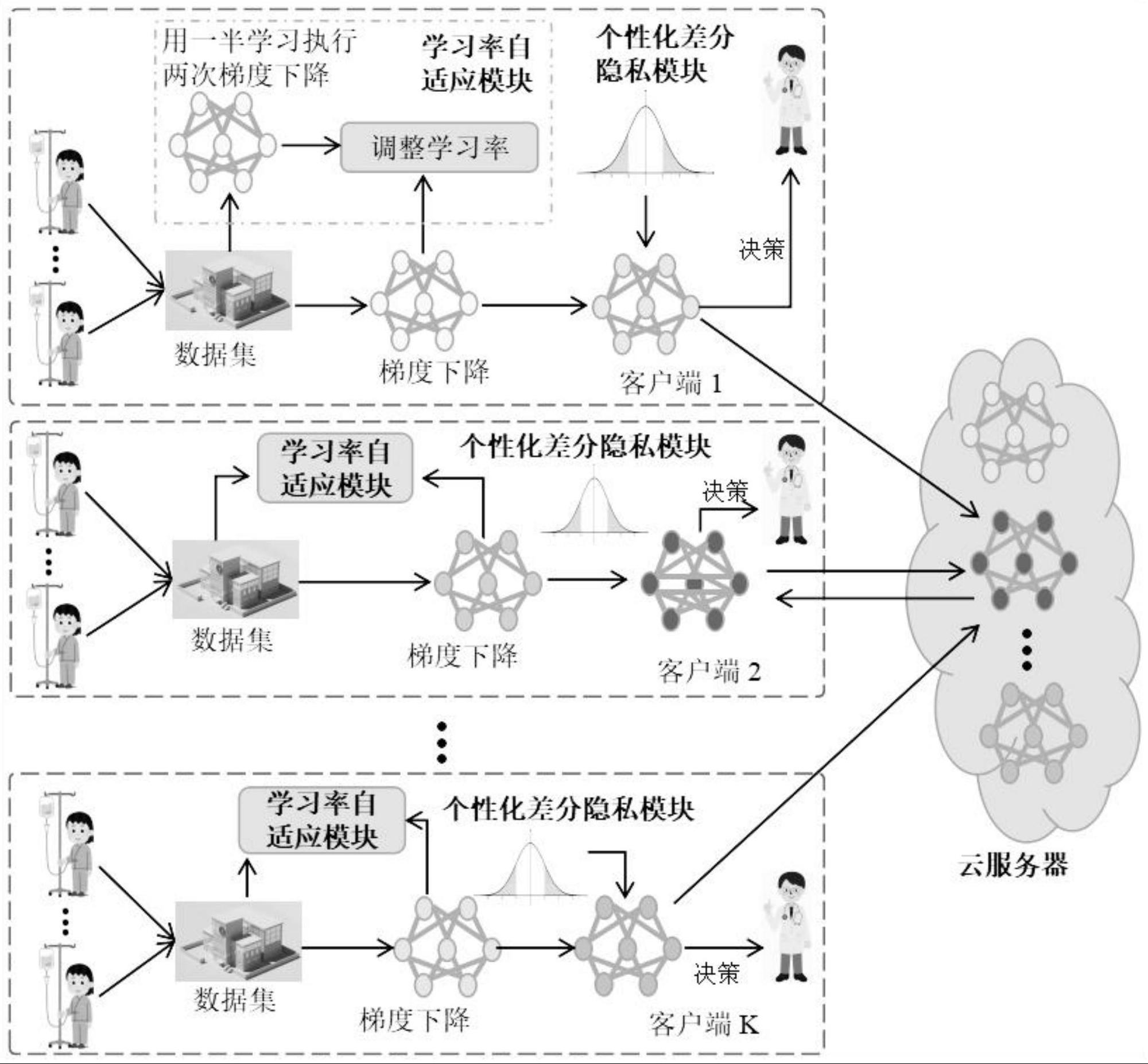
2、为达到上述目的,本发明是采用下述技术方案实现的:一种基于差分隐私的学习率自适应医疗图像识别方法,包括以下步骤,
3、采集患者病变部位的医疗图像;
4、将采集的医疗图像输入预置在本地客户端内的融合了多家医院的医疗数据的本地模型中,输出识别结果。
5、进一步的,融合了多家医院的医疗数据的本地模型的构建方法,包括:
6、a、多个客户端构建本地模型,设置本地模型的超参数和损失函数;
7、b、客户端将本地模型传输至服务器;
8、c、服务器获取各个客户端的本地模型,对各个客户端的本地模型进行聚合维护后为每个客户端生成个性化云模型;
9、d、服务器将个性化云模型传输至对应的各个客户端;
10、e、客户端获取本地数据及个性化云模型,将个性化云模型作为损失函数的近端项的邻近中心,利用损失函数及本地数据对本地模型进行训练,直至训练次数达到本地迭代次数,得训练好的本地模型;
11、f、重复步骤b~e,直至训练次数达到全局迭代次数,输出本地模型。
12、进一步的,所述本地模型采用深度卷积神经网络,所述深度卷积神经网络采用relu函数作为激活函数,其由2个卷积层、2个池化层、1个dropout层、3个批处理层和2个全连接层组成,所述卷积层的卷积核大小为5。
13、所述本地模型的超参数包括本地批量大小、本地迭代次数、全局迭代次数、客户端数量、每轮的客户端选择比例值、全局隐私预算、差分隐私的松弛度、梯度裁剪阈值以及算法学习率。
14、进一步的,所述损失函数采用最小损失函数,最小损失函数由交叉熵损失函数和注意力诱导函数组成;
15、交叉熵损失函数用于判定模型输出的结果与正确的输出值的接近程度;
16、注意力诱导函数用于反复鼓励相似的客户端进行更多协作来自适应地促进客户之间潜在的成对协作。
17、所述最小损失函数的表达式为:
18、
19、其中,表示最小损失函数,w=[w1,...,wk],λ为正则化参数,λ>0;
20、表示交叉熵损失函数,k表示第k个客户端,k为客户端数量,lk为第k个客户端的损失函数,wk为第k个客户端的本地模型参数;
21、表示注意力诱导函数,a表示负指数函数,j表示第j个客户端,wj为第j个客户端的本地模型参数。
22、进一步的,服务器获取各个客户端的本地模型,对各个客户端的本地模型进行聚合维护后为每个客户端生成个性化云模型,包括:
23、服务器获取各个客户端的本地模型;
24、在第t次迭代中,通过梯度下降对本地模型损失函数中的注意力诱导函数a(w)进行优化,得第t次迭代的个性化云模型参数,表达式如下:
25、
26、其中,ut为第t次迭代的个性化云模型参数,表示求导,wt-1为第t-1次迭代的本地模型参数,αt为第t次迭代的算法学习率;
27、对所有客户端的本地模型进行线性组合运算,生成各个客户端的个性化云模型,其表达式如下:
28、
29、其中,为第t次迭代中第k个客户端的个性化云模型参数,为第t-1次迭代中第k个客户端的本地模型参数,为第t-1次迭代中第j个客户端的本地模型参数,a′(||wk-wj||2)表示a(||wk-wj||2)的导数,为本地模型参数集,ξk,1,…,ξk,k为的线性组合权值;
30、对生成的个性化云模型进行初始化。
31、进一步的,客户端获取本地图像数据及个性化云模型,将个性化云模型作为损失函数的近端项的邻近中心,利用损失函数及本地图像数据对本地模型进行训练,直至训练次数达到本地迭代次数,得训练好的本地模型,包括:
32、客户端获取个性化云模型;
33、使用个性化云模型参数作为邻近中心,即用ut代替最小损失函数中的近端项wj,对本地模型进行训练,表达式如下:
34、
35、其中,ut为个性化云模型参数,wt为第t次迭代的本地模型参数,表示最小损失函数,表示最小交叉熵损失函数,λ为正则化参数,λ>0,αt为第t次迭代中算法学习率,w为本地模型参数;
36、重复上述训练过程,直至训练次数达到本地迭代次数,得训练好的本地模型。
37、进一步的,还包括客户端对算法学习率进行调整,具体为:
38、客户端先对本地图像数据样本进行随机采样,以获取当前算法学习率;
39、利用采样数据对本地模型连续执行两次步长为当前学习率一半的梯度裁剪和梯度下降,得到两个一半步长的梯度矩阵;
40、利用采样数据对本地模型进行当前的完整的学习率的梯度裁剪和梯度下降,得到完整步长的梯度矩阵,然后更新本地模型;
41、评估本地模型的梯度矩阵和两个一半步长的梯度矩阵之间的梯度误差;根据梯度误差调整算法学习率,表达式如下:
42、
43、其中,errt为梯度误差,ψ为梯度误差预值,αmin<1,αmax>1。
44、进一步的,所述本地图像数据需进行标准化处理,所述标准化处理包括:
45、将本地图像数据转化为图像矩阵;
46、逐通道地对图像矩阵进行标准化,图像矩阵平均值变为0,图像矩阵标准差变为1,使图像矩阵的元素均在[-1,1]范围内,表达式如下:
47、
48、其中,channel为图像矩阵通道数,input[channel]为输入的图像矩阵,mean[channel]为图像矩阵平均值,std[channel]为图像矩阵标准差,output[channel]为输出的图像矩阵。
49、进一步的,还包括根据客户端设置的隐私偏好对本地模型进行个性化隐私保护,具体为:
50、获取当前本地模型参数,客户端根据隐私保护等级εk,产生高斯噪声,并添加到本地模型参数中,表达式如下:
51、m=f(d)+n(0,cδf/ε)
52、其中,m为添加噪声后的本地模型参数,f(d)为添加噪声前的本地模型参数,δf为灵敏度,取值为f(d')为相邻数据集训练的未添加噪声的本地模型参数,c为常数,取值范围为
53、进一步的,所述隐私保护等级εk包括三个,其分别表示为ε(εlow,εmid,εhigh),隐私保护等级εk由客户端设置的隐私偏好决定。
54、与现有技术相比,本发明所达到的有益效果:
55、本发明可以通过反复鼓励相似的客户进行更多协作来自适应的促进客户之间潜在的成对协作。从而缓解不同医疗机构的数据不是独立同分布的问题;
56、传统的固定学习率可能无法很好地适应不同的数据分布、模型复杂度和训练阶段的需求。因此,传统的固定学习率对于不同的数据分布和噪声可能表现不佳。本发明通过学习率自适应算法可以根据实际数据的特点来动态地调整学习率,从而提高模型对于不同数据分布的鲁棒性;
57、在医疗应用场景中,不同医疗机构的地域分布、患者人口分布和隐私保密要求存在差异,而传统的基于差分隐私的联邦学习算法采用统一分配隐私预算的假设,无法切实满足各个机构的实际需求和隐私保护要求。此外,统一的隐私预算级别意味着一些客户会浪费大量的隐私预算。本发明通过个性化差分隐私可以根据用户设置的隐私偏好来保护信息,达到个性化隐私保护的目的。
- 还没有人留言评论。精彩留言会获得点赞!