基于全文检索的贸易数据疑似命中检索方法及系统与流程
本发明涉及全文检索,更具体地,涉及一种基于全文检索的贸易数据疑似命中检索方法及系统。
背景技术:
1、在金融领域中,金单业务和供票业务的运营和风险岗位人员需要审核贸易背景资料。为了提高审核效率,通常使用基于ocr(光学字符识别)的工具来快速识别各种票据信息。然而,ocr工具在实际使用中存在一些问题。
2、首先,影像件样本格式多种多样,可能是不同的文件类型(如pdf、图片等),这给识别过程带来了挑战。此外,影像清晰度参差不齐,有些影像件可能模糊不清或者有噪点,这导致ocr工具无法准确地提取关键信息。
3、由于上述问题,ocr工具对于关键信息的识别准确率无法保证百分之百。当ocr无法正确识别影像件中的关键信息时,就需要专业审批人员进行人工审核和逐一对比。他们需要利用ocr识别得到的候选关键字与影像件文本进行对照,这需要消耗大量的人力资源,而且人工对比的遗漏和错误率较高。
4、此外,这种人工审核过程是耗时的,无法快速有效地进行业务请求的决策判断。业务流程也会受到阻塞,无法满足实时业务的需求。因此需要寻求解决方案来克服ocr识别准确性的限制,提高审核效率并实现快速、准确的业务决策。
5、全文检索是一种通过扫描整个文本内容来查找包含指定关键字的文档或记录的技术。但现有的全文检索需要关键字与原文所有的字符进行一一比对,检索速度相对较慢。
技术实现思路
1、本发明的首要目的是提供一种全文检索方法,解决现有全文检索中需要关键字与原文所有的字符进行一一比对,检索速度相对较慢的问题。
2、本发明的进一步目的是提供一种全文检索系统。
3、本发明的第三个目的是提供一种贸易数据疑似命中检索方法,解决现有人工审核过程时耗时长,无法快速有效地进行业务请求的决策判断的问题。
4、本发明的第四个目的是提供一种贸易数据疑似命中检索系统。
5、为解决上述技术问题,本发明的技术方案如下:
6、一种全文检索方法,包括以下步骤:
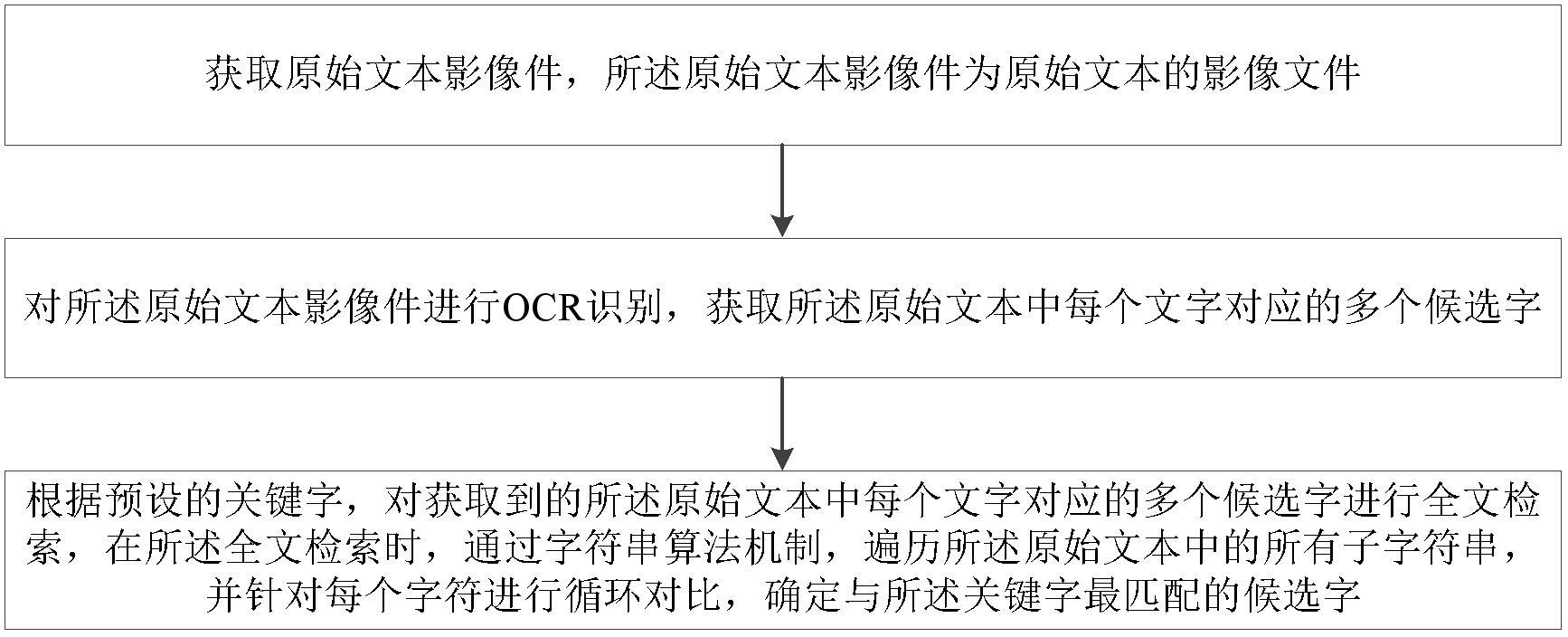
7、获取原始文本影像件,所述原始文本影像件为原始文本的影像文件;
8、对所述原始文本影像件进行ocr识别,获取所述原始文本中每个文字对应的多个候选字;
9、根据预设的关键字,对获取到的所述原始文本中每个文字对应的多个候选字进行全文检索,在所述全文检索时,通过字符串算法机制,遍历所述原始文本中的所有子字符串,并针对每个字符进行循环对比,确定与所述关键字最匹配的候选字。
10、优选地,所述根据预设的关键字,对获取到的所述原始文本中的每个文字对应的多个候选字进行全文检索,具体为:
11、1)初始化前缀匹配数数组next;
12、2)分别逐个字符遍历原始文本和关键字进行对比,关键字的每个字符与原始文本字符对比时需逐一与所有的候选字进行对比,任意匹配一个候选字皆为匹配;
13、3)若单个字符匹配成功,则返回步骤2)中,令关键字与原始文本进行下一个字符匹配,若关键字所有的字符均匹配成功则代表命中,流程结束,若关键字有字符匹配不成功,则进入步骤4);
14、4)若关键字第一个字符匹配不成功,则将对比位置从原始文本当前字符向后移动一位,返回步骤2)中进行匹配;
15、若关键字第一个字符匹配成功但其它字符匹配不成功,则根据所述前缀匹配数数组next,定位关键字下一轮比较的开始字符,返回步骤2)中进行匹配。
16、优选地,所述前缀匹配数数组next的计算方法具体为:
17、所述前缀匹配数数组next的数组长度与所述关键字长度相同,且next[0]=-1,next[n]为前缀匹配数数组next的第n位;
18、从所述关键字第2位往后逐步遍历计算所述前缀匹配数数组next,每次查找关键字字符key[0]到key[i]之间字符组成的字符串的前缀子串和后缀子串的最大公共字符串数,其中,key[0]为关键字的第一个字符,key[i]为关键字的第i个字符,i为当前遍历次数,每次遍历后,i加1;所述前缀子串为{“key[0]”,“key[0]key[1]”,…,“key[0]… key[i-1]”},所述后缀子串为{“key[i]”,“key[i-1] key[i]”,…,“key[1]… key[i]”};
19、将第i次遍历时获取到的最大公共字符串数减1后,设置到next[i]中。
20、优选地,所述根据所述前缀匹配数数组next,定位关键字下一轮比较的开始字符,具体为:
21、读取next[k]的值,k为当前关键字字符下标减1,next[k]的值为下一轮关键字开始与所述原始文本进行匹配的第一个字符所在的位置。
22、一种全文检索系统,其特征在于,包括:
23、影像件获取模块,所述影像件获取模块用于获取原始文本影像件,所述原始文本影像件为原始文本的影像文件;
24、ocr识别模块,所述ocr识别模块用于对所述原始文本影像件进行ocr识别,获取所述原始文本中每个文字对应的多个候选字;
25、匹配模块,所述匹配模块用于根据预设的关键字,对获取到的所述原始文本中每个文字对应的多个候选字进行全文检索,在所述全文检索时,通过字符串算法机制,遍历所述原始文本中的所有子字符串,并针对每个字符进行循环对比,确定与所述关键字最匹配的候选字。
26、优选地,所述匹配模块中根据预设的关键字,对获取到的所述原始文本中每个文字对应的多个候选字进行全文检索,具体为:
27、1)初始化前缀匹配数数组next;
28、2)分别逐个字符遍历原始文本和关键字进行对比,关键字的每个字符与原始文本字符对比时需逐一与所有的候选字进行对比,任意匹配一个候选字皆为匹配;
29、3)若单个字符匹配成功,则返回步骤2)中,令关键字与原始文本进行下一个字符匹配,若关键字所有的字符均匹配成功则代表命中,流程结束,若关键字有字符匹配不成功,则进入步骤4);
30、4)若关键字第一个字符匹配不成功,则将对比位置从原始文本当前字符向后移动一位,返回步骤2)中进行匹配;
31、若关键字第一个字符匹配成功但其它字符匹配不成功,则根据所述前缀匹配数数组next,定位关键字下一轮比较的开始字符,返回步骤2)中进行匹配。
32、优选地,所述前缀匹配数数组next的计算方法具体为:
33、所述前缀匹配数数组next的数组长度与所述关键字长度相同,且next[0]=-1,next[n]为前缀匹配数数组next的第n位;
34、从所述关键字第2位往后逐步遍历计算所述前缀匹配数数组next,每次查找关键字字符key[0]到key[i]之间字符组成的字符串的前缀子串和后缀子串的最大公共字符串数,其中,key[0]为关键字的第一个字符,key[i]为关键字的第i个字符,i为当前遍历次数,每次遍历后,i加1;所述前缀子串为{“key[0]”,“key[0]key[1]”,…,“key[0]… key[i-1]”},所述后缀子串为{“key[i]”,“key[i-1] key[i]”,…,“key[1]… key[i]”};
35、将第i次遍历时获取到的最大公共字符串数减1后,设置到next[i]中。
36、优选地,所述根据所述前缀匹配数数组next,定位关键字下一轮比较的开始字符,具体为:
37、读取next[k]的值,k为当前关键字字符下标减1,next[k]的值为下一轮关键字开始与所述原始文本进行匹配的第一个字符所在的位置。
38、一种贸易数据疑似命中检索方法,包括以下步骤:
39、根据融资业务审批请求,发起根据文件id下载影像件请求;
40、下载影像件,利用上述所述的全文检索方法进行字符串匹配;
41、返回疑似命中结果。
42、一种贸易数据疑似命中检索系统,包括:
43、请求模块,所述请求模块根据融资业务审批请求,发起根据文件id下载影像件请求;
44、全文检索模块,所述全文检索模块用于下载影像件,并利用上述所述的全文检索方法进行字符串匹配;
45、返回模块,所述返回模块用于返回疑似命中结果。
46、与现有技术相比,本发明技术方案的有益效果是:
47、本发明针对全文检索过程进行了优化,根据关键字自身文字重合度情况,优化与原文字符匹配时减少关键字与原文字符对比次数,能够有效减少检索对比的次数,提高检索的效率。同时还进一步支持了后续的处理与决策,提高了审核流程的效率与准确性。
- 还没有人留言评论。精彩留言会获得点赞!