面向SIMD指令的SM4细粒度切片优化方法及系统
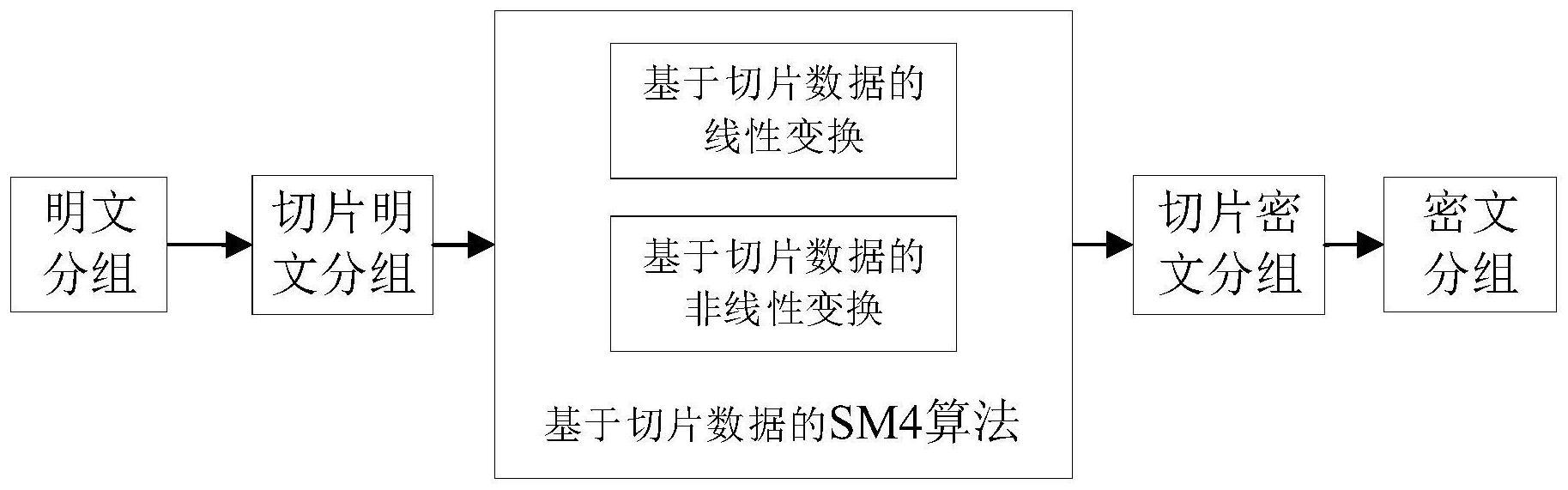
本发明涉及密码算法执行的加速优化,具体涉及一种面向simd指令的sm4细粒度切片优化方法及系统。
背景技术:
1、比特切片技术是以将多个明文分组相同粒度的数据切片存放在每个寄存器中,并通过操作寄存器实现并行处理多个明文数据为主要思路,高效实现软件层面上的分组密码算法的一项有效技术。应用比特切片技术的算法将密码算法加密过程分解为一系列使用xor、and、or和not等逻辑门的逻辑位运算,从而可以在单个n位处理器上进行n次并行加密,即同时执行n个逻辑位运算。
2、当把比特切片技术应用在分组密码算法上时,会在密码算法加密或解密前后引入2个额外的数据切片过程,包括明文数据切片和密文数据切片,如图1所示。数据切片算法的切片性能在一定程度上会影响切片分组密码算法的加解密计算性能,为了降低数据切片算法引入的计算开销,必须设计有效的数据切片算法。
3、数据切片算法由数据块阶数l和切片窗口宽度w两个参数确定。当在n位处理器上实现l阶w位宽数据切片算法时,有如下等式成立:
4、l×n/n=n/w, (1)
5、上式中,n为分组密码算法分组长度。在sm4算法中,n为128。
6、由此可知,当处理器平台确定时,数据切片算法的阶数l和切片窗口宽度w成反比例关系,两者乘积等于目标处理器字长。当以1比特为单位设置切片窗口宽度时,切片完成后每个存储字存储着来自不同明文分组的1位比特位,仅使用逻辑运算即可完成切片分组密码算法的加密或加密运算。因此通过将切片窗口宽度设置为1比特,即可设计通用的切片分组密码算法。在通用数据切片算法中,为了满足具有不同分组长度的分组密码算法的切片化,切片窗口宽度被设置为1,由于并未考虑分组密码算法的设计结构,因此存在并行粒度较大的问题,且算法需持续等待128个明文分组的到来,对其进行切片后才能正式进行加解密操作,导致数据转换开销占比较大,同时增加了密码算法的启动时间。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种面向simd指令的sm4细粒度切片优化方法及系统,本发明旨在针对sm4算法实现细粒度的并行切片,以减少sm4算法执行过程中的内存占用、减少sm4算法的启动时间。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种面向simd指令的sm4细粒度切片优化方法,包括:
4、s101,将长度为n位的明文分组分段为n/m个m位的基本操作单元,顺序排列所有的基本操作单元,针对顺序排列后形成顺序存储结构的基本操作单元,采用指定的切片方法利用simd指令将其转换为大于1的指定大小的切片窗口宽度的切片存储结构作为切片明文分组;
5、s102,对切片明文分组执行sm4算法的线性变换和非线性变换的迭代,且在执行线性变换和非线性变换的迭代时将不同基本操作单元中相同偏移位置需执行相同运算逻辑的比特集中存储在同一个寄存器字进行逻辑运算,以实现不同基本操作单元的并行逻辑运算,最终迭代32轮后得到128比特的切片密文分组;
6、s103,将切片密文分组采用指定的切片方法切片得到密文分组。
7、可选地,步骤s101中采用指定的切片方法利用simd指令将其转换为大于1的指定大小的切片窗口宽度的切片存储结构作为切片明文分组时,指定的切片窗口宽度小于或等于基本操作单元的个数n/m,且根据sm4算法的明文分组长度n为128位,基本操作单元位数为32位,切片窗口宽度最大为4,使得sm4算法可并行处理n/4个基本操作单元,其中n为处理器数据位宽。
8、可选地,步骤s101中采用指定的切片方法利用simd指令将其转换为大于1的指定大小的切片窗口宽度的切片存储结构作为切片明文分组包括:首先利用simd查表指令,将顺序存储结构中32个明文分组的基本操作单元的16个字节进行重排以实现不同基本操作单元的并行逻辑运算,且16个字节进行重排的位置映射为:
9、[f,b,7,3,e,a,6,2,d,9,5,1,c,8,4,0],
10、该位置映射中,每一个索引位置的符号为16进制字符,表示重排前的索引位置;索引位置为0的字节在重排前的索引位置为15,索引位置为1的字节在重排前的索引位置为11,依次类推,索引位置为15的字节在重排前的索引位置为0;接着利用simd逻辑移位运算、simd逻辑异或运算、simd逻辑与运算,结合5组掩码mask0~mask4采用simd逻辑运算指令完成32个基本操作单元的两两比特切片,且5组掩码mask0~mask4的16进制表示为:
11、mask0=5555555555555555555555555555555555555555555555555555555555555555,
12、mask1=3333333333333333333333333333333333333333333333333333333333333333,
13、mask2=0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f0f,mask3=00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff00ff,
14、mask4=0000ffff0000ffff0000ffff00 00ffff0000ffff0000ffff0000ffff0000ffff;
15、其中,结合5组掩码mask0~mask4采用simd逻辑运算指令完成32个基本操作单元的两两比特切片包括:
16、s201,将位置映射初始化赋值给索引数组index,将5组掩码mask0~mask4初始化赋值为掩码m0~m4,针对顺序存储结构中32个基本操作单元中每一个明文分组的重排后的索引位置;初始化循环变量j为0;
17、s202,利用simd逻辑运算指令并行针对循环变量j执行左移操作shl后赋值给变量k;
18、s203,初始化循环变量i为0;
19、s204,根据变量k以及循环变量i的值,通过r←shl(i-i%k,1)+i%k计算出变量r的值,其中shl为simd逻辑运算指令的左移操作,←表示计算;
20、s205,通过执行temp←ushr(a[r+k],k)计算出临时变量temp的值,其中ushr为simd逻辑运算指令的无符号右移操作,a[r+k]为第r+k个基本操作单元;
21、s206,通过执行temp←xor(temp,a[r])更新临时变量temp的值,其中xor为simd逻辑运算指令的异或操作,a[r]为第r个基本操作单元;
22、s207,通过执行temp←and(temp,mj)更新临时变量temp的值,其中and为simd逻辑运算指令的与操作,mj为第j个掩码;
23、s208,通过执行a[r]←xor(a[r],temp)更新第r个基本操作单元a[r];
24、s209,通过执行temp←shl(temp,k)更新临时变量temp的值;
25、s210,通过执行a[r+k]←xor(a[r+k],temp)更新第r+k个基本操作单元a[r+k]的值;
26、s211,将循环变量i加1,若循环变量i小于16,则跳转步骤s204;否则跳转步骤s212;
27、s212,将循环变量j加1,若循环变量j小于5,则跳转步骤s202;否则,判定32个基本操作单元的两两比特切片已经完成。
28、可选地,步骤s101中采用指定的切片方法将其转换为大于1的指定大小的切片窗口宽度的切片存储结构时,还包括利用simd指令将经由密钥扩展算法切片生成的子密钥表示成切片子密钥以用于将密文分组的解密:首先将大小为32比特的子密钥用simd扩展指令扩增为128比特的扩增子密钥ek,接着将扩增子密钥ek中的字节用simd查表指令进行指令重排,然后对扩增子密钥ek进行8次循环操作,且在任意第i次循环中,首先利用simd指令将扩增子密钥ek利用simd指令进行无符号左移i位,然后接着对无符号左移i位后的结果应用simd指令的有符号右移指令,并将所得结果存储在切片字节数组k的第i个元素k[i]中,最终在完成8次循环操作后,得到存储在切片字节数组k中的切片完成后的切片子密钥。
29、可选地,步骤s102中线性变换的函数表达式为:
30、
31、上式中,l(b)为线性变换结果,m为分块矩阵,y为非线性变换输出,为逻辑异或,<<<为循环左移,q0、q1和q2为中间变量,且有:
32、y=(y0,y1,y2,y3,y4,y5,y6,y7)t
33、
34、
35、
36、
37、
38、其中,b0~b7为非线性变换输出分量,且其中任意第i个元素bi大小为128比特。
39、可选地,步骤s102中非线性变换由4个并行的s盒组成,且s盒的函数表达式为:
40、s(x)=a×i(a×x+c)+c,
41、上式中,s(x)为非线性变换函数,a和c为固定参数向量,i为有限域gf(28)上的求逆运算,x为sm4算法的中间迭代数据,且针对s盒的计算将有限域gf(28)上的求逆运算转换到塔域gf(((22)2)2)完成以降低求逆运算的复杂度。
42、可选地,所述将有限域gf(28)上的求逆运算转换到塔域gf(((22)2)2)包括:
43、s301,借助同构映射矩阵gf(28)/gf(24),将有限域gf(28)中的元素表示为有限域gf(24)上的线性多项式;使用同构映射矩阵gf(24)/gf(22)将有限域gf(24)上的元素表示为有限域gf(22)上的线性多项式;使用同构映射矩阵gf(22)/gf(2)将有限域gf(22)上的元素表示为有限域gf(2)上的线性多项式;
44、s302,采用下式所示的塔域结构优化s盒的求逆运算从而将s盒中的求逆运算递归转换到有限域gf(2)上的乘法与加法运算:
45、
46、上式中,gf(28)/gf(24)、gf(24)/gf(22)、gf(22)/gf(2)为三个同构映射矩阵,r(y)s(z)和t(w)分别为对应有限域转换的函数表达式,y、z和w为多项式基下自变量,τ和v为有限域gf(24)上的参数,t和n为有限域gf(22)上的参数,y、z和w为正规基下的自变量。
47、可选地,步骤s103中采用的指定的切片方法与步骤s101中采用的指定的切片方法相同。
48、此外,本发明还提供一种面向simd指令的sm4细粒度切片优化系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述面向simd指令的sm4细粒度切片优化方法。
49、此外,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行所述面向simd指令的sm4细粒度切片优化方法。
50、和现有技术相比,本发明主要具有下述优点:sm4算法的在传统数据切片算法实现中,当利用128位simd指令实现数据切片算法时,切片窗口宽度被设置为1,需要切片处理的明文分组多达128组,不仅需要占用的内存大小多达1kb,并且在正式进行加解密操作之前,sm4算法需要不断等待128个明文分组的到来。当面对小规模短数据时,128个明文分组无法得到及时补充,此时sm4算法进入持续等待时间,无法及时对已有明文分组进行加解密,导致加密算法的启动时间较长。而本发明面向simd指令的sm4细粒度切片优化方法根据sm4算法结构特性,包括将长度为n位的明文分组分段为n/m个m位的基本操作单元,顺序排列所有的基本操作单元,针对顺序排列后形成顺序存储结构的基本操作单元,采用指定的切片方法利用simd指令将其转换为大于1的指定大小的切片窗口宽度的切片存储结构作为切片明文分组,对切片明文分组执行sm4算法的线性变换和非线性变换的迭代,且在执行线性变换和非线性变换的迭代时将不同基本操作单元中相同偏移位置需执行相同运算逻辑的比特集中存储在同一个寄存器字进行逻辑运算,以实现不同基本操作单元的并行逻辑运算,最终迭代32轮后得到128比特的切片密文分组,将切片密文分组采用指定的切片方法切片得到密文分组,不仅减小了内存占用,而且大大减少了加密算法的启动时间。
- 还没有人留言评论。精彩留言会获得点赞!