一种电子公文处理方法及系统与流程
本发明涉及数据处理,具体涉及一种电子公文处理方法及系统。
背景技术:
1、随着信息技术的迅速发展,电子公文的处理和管理成为了现代办公环境中的重要问题。传统的纸质公文处理方式存在着许多问题,如信息传递效率低、存储和检索困难、易丢失等。因此,开发一种高效、安全、可靠的电子公文处理方法和系统成为了迫切需求。
2、现有技术通过算术编码对电子公文数据进行压缩,传统的算术编码在对数据进行编码前统计数据中任意一类字符的出现频率并根据字符频率为字符分配概率区间进行编码。然而电子公文有着明确的主题,有较多关键词在公文内容中都被较多提及,且在整篇公文内容中的提及频率相近。通过分段的方式使数据段中字符分布的均匀程度较低,对数据进行分段算术编码,由于对数据进行分段后的每个数据段都需要额外存储编码表造成额外的存储开销,分段过多会导致较低的压缩率甚至是负压缩,分段过少又难以使数据段内字符的分布不均匀。因此需要对电子公文数据的分段方法进行改进,对数据进行自适应分段。
技术实现思路
1、本发明提供一种电子公文处理方法及系统,以解决现有的问题。
2、本发明的一种电子公文处理方法及系统采用如下技术方案:
3、本发明一个实施例提供了一种电子公文处理方法,该方法包括以下步骤:
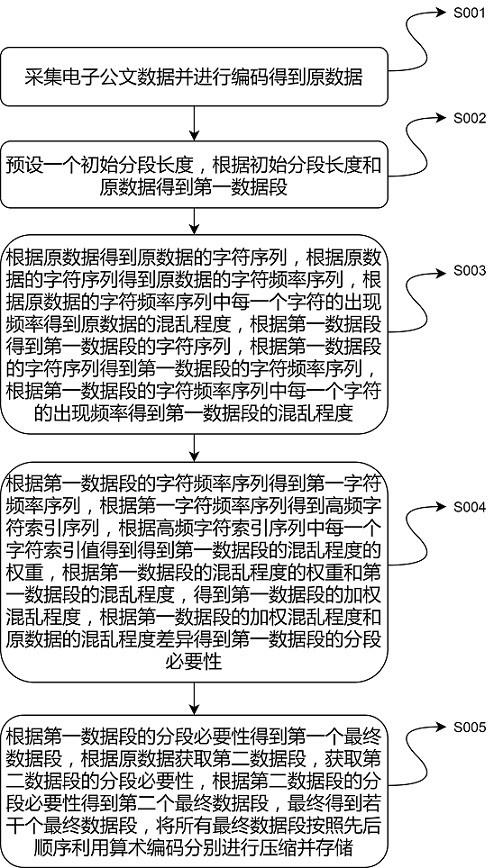
4、采集电子公文数据,根据电子公文数据得到原数据,预设初始分段长度l,从原数据最左侧开始在原数据上截取长度为l的数据段记为第一数据段;
5、根据原数据得到原数据的字符序列,根据原数据的字符序列得到原数据的字符频率序列,根据原数据的字符频率序列中每一个字符的出现频率得到原数据的混乱程度;
6、根据第一数据段得到第一数据段的字符序列,根据第一数据段的字符序列得到第一数据段的字符频率序列,根据第一数据段的字符频率序列中每一个字符的出现频率得到第一数据段的混乱程度;
7、根据第一数据段的字符频率序列得到第一字符频率序列,根据第一字符频率序列得到高频字符索引序列,根据高频字符索引序列中每一个字符索引值得到第一数据段的混乱程度的权重;
8、将第一数据段的混乱程度的权重与第一数据段的混乱程度的乘积作为第一数据段的加权混乱程度,根据第一数据段的加权混乱程度和原数据的混乱程度差异得到第一数据段的分段必要性;
9、根据第一数据段的分段必要性得到第一个最终数据段,从第一最终数据段的最右侧开始,在原数据上依次截取出若干个最终数据段;将所有最终数据段按照先后顺序利用算术编码分别进行压缩并存储。
10、进一步地,所述根据电子公文数据得到原数据,包括的具体步骤如下:
11、利用unicode编码将电子公文数据进行编码,将电子公文数据全部编码为unicode编码中存在的字符,得到电子公文数据的编码数据,记为原数据。
12、进一步地,所述根据原数据得到原数据的字符序列,根据原数据的字符序列得到原数据的字符频率序列,包括的具体步骤如下:
13、获取原数据中出现的字符种类,将原数据中出现的字符种类按照unicode字符数据库中字符顺序进行排序,得到原数据的字符序列;获取原数据的字符序列中每一个字符在原数据中的出现频率,将原数据的字符序列中每一个字符在原数据中的出现频率按照字符顺序进行排列,得到原数据的字符频率序列。
14、进一步地,所述根据第一数据段的字符频率序列中每一个字符的出现频率得到第一数据段的混乱程度,包括的具体步骤如下:
15、
16、式中,为原数据的字符频率序列中第i个字符的出现频率,为原数据的字符频率序列中字符总个数,为以为底的对数函数,为原数据的混乱程度。
17、进一步地,所述根据第一数据段得到第一数据段的字符序列,根据第一数据段的字符序列得到第一数据段的字符频率序列,包括的具体步骤如下:
18、获取第一数据段中出现的字符种类,将第一数据段中出现的字符种类按照unicode字符数据库中字符顺序进行排序,得到第一数据段的字符序列;获取第一数据段的字符序列中每一个字符在第一数据段中的出现频率,将第一数据段的字符序列中每一个字符在第一数据段中的出现频率按照字符顺序进行排列,得到第一数据段的字符频率序列。
19、进一步地,所述根据第一数据段的字符频率序列得到第一字符频率序列,根据第一字符频率序列得到高频字符索引序列,包括的具体步骤如下:
20、将第一数据段的字符频率序列中字符的出现频率按照从大到小的顺序进行排列,得到第一字符频率序列,预设数量阈值m,获取第一字符频率序列中前m个字符对应在第一数据段的字符序列中的字符索引值,得到高频字符索引序列。
21、进一步地,所述根据高频字符索引序列中每一个字符索引值得到第一数据段的混乱程度的权重,包括的具体步骤如下:
22、
23、式中,为第一数据段的字符频率序列中字符总个数,为高频字符索引序列中字符索引值的总个数,为高频字符索引序列中第j个字符索引值,为第一数据段的混乱程度的权重。
24、进一步地,所述根据第一数据段的加权混乱程度和原数据的混乱程度差异得到第一数据段的分段必要性,包括的具体步骤如下:
25、
26、式中,为第一数据段的字符频率序列中字符总个数,为反正切函数,为第一数据段的加权混乱程度,为原数据的混乱程度,表示第一数据段的加权混乱程度和原数据的混乱程度差异,为自然常数e为底的指数函数,为第一数据段的分段必要性。
27、进一步地,所述根据第一数据段的分段必要性得到第一个最终数据段,从第一最终数据段的最右侧开始,在原数据上依次截取出若干个最终数据段,包括的具体步骤如下:
28、预设一个分段必要性阈值,记为,将第一数据段的分段必要性与进行比较,若,为第一数据段的分段必要性,则从原数据中将第一数据段之后的第一个字符纳入到第一数据段中,得到新的第一数据段,记为目标数据段,获取目标数据段的分段必要性并与进行比较,若目标数据段的分段必要性仍小于等于,则继续从原数据中将目标数据段之后的第一个字符纳入到目标数据段中,以此类推,直至数据段的分段必要性大于,将分段必要性大于的数据段记为第一个最终数据段;
29、从第一个最终数据段的最右侧开始,在原数据上截取长度为l的数据段,记为第二数据段,并获取第二数据段的分段必要性与进行比较,最终获得第二个最终数据段,从第二个最终数据段的最右侧开始,在原数据上截取长度为l的数据段,记为第三数据段,并获取第三数据段的分段必要性与进行比较,最终获得第三个最终数据段,以此类推,直至无法再次截取时停止,最终得到原数据的若干个最终数据段。
30、本发明还提出了一种电子公文处理系统,包括存储器和处理器,所述处理器执行所述存储器存储的计算机程序,以实现前述所述方法的步骤。
31、本发明的技术方案的有益效果是:在电子公文不同部分的侧重点有所不同,故公文内容中的字符频率分布会有所不均。本发明通过对电子公文数据的分段方法进行改进,对数据进行自适应分段,根据数据段的混乱程度与原数据混乱程度的差异获取分段对压缩编码的优化效果,根据该优化效果获取数据段的分段必要性对数据进行分段并压缩。
32、通过对电子公文数据在压缩过程中由于多个关键词在公文内容中的出现频率相近导致对电子公文数据压缩信息熵较大的问题,本方案通过对数据进行分段的操作,使各数据段的信息熵尽可能小,从而达到增大数据压缩率。
- 还没有人留言评论。精彩留言会获得点赞!