一种时延感知调度算法的制作方法
本发明涉及计算机系统时延调度,具体为一种时延感知调度算法。
背景技术:
1、当前常见的以linux为操作系统的k8s集群,往往以容器的方式部署应用服务,k8s集群会为服务分配cpu/mem/io/net等资源,一方面,尽量提升集群里资源的利用率,可以有效降低成本,但是这也会使得资源的竞争更加激烈,多个服务竞争同一种资源,未能得到资源的服务,需要等待其他服务释放资源才能继续工作,对于时延敏感的服务,等待资源的时延会导致qps和rt抖动,从而影响客户体验;
2、目前常见的监控系统通常以qps和rt等指标反馈服务质量,这些指标与用户的直观感受密切相关。但是引起qps和rt抖动的原因往往是多方面的,比如提供服务的应用程序存在bug,数据在网络传输中丢失或重传,以及上文提到的资源竞争导致的等待时延等等,具体的原因需要具体分析,因此服务的qps和rt指标无法作为集群给服务分配资源的依据;
3、集群系统为服务分配资源,一般是配置服务能够使用的资源数量,比如“0.5个cpu,2g内存,100m/sio带宽”,并且设置服务使用资源的优先级(一般来说在线服务的优先级高于离线服务的优先级),提升集群资源利用率的一个常见方法是超卖,多个服务同时运行时,需要竞争才能获取到配置的资源份额,但linux上缺少以容器为单位,反映服务竞争资源激烈程度的指标,给准确评估资源分配是否合理带来难度。
技术实现思路
1、本发明的目的在于提供一种时延感知调度算法,监测机器上每个服务(容器)在使用cpu/mem/io/net资源的时延,以此评估服务分配的资源数量,优先级是否合理,从而为k8s集群调度系统调整服务资源,重新调度服务提供依据,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种时延感知调度算法,包括linux操作系统与以linux为操作系统的k8s集群调度系统,所述linux操作系统以容器为单位进行监测系统资源使用的时延,将其上报给所述k8s集群系统,通过对时延的分析,给容器分配更合理的资源具体为包括:监测容器的调度时延、监测容器申请内存的等待时延、监测容器io操作的等待时延与监测容器net的时延,获取到相应的指标数据后,根据cgroup id拼接出对应的cgroup路径,之后调用kubelet apiserver获取pod和container级别的元数据,对指标数据进行聚合后上报给所述k8s集群调度系统,所述k8s集群调度系统根据时延,调整分配给服务的资源。
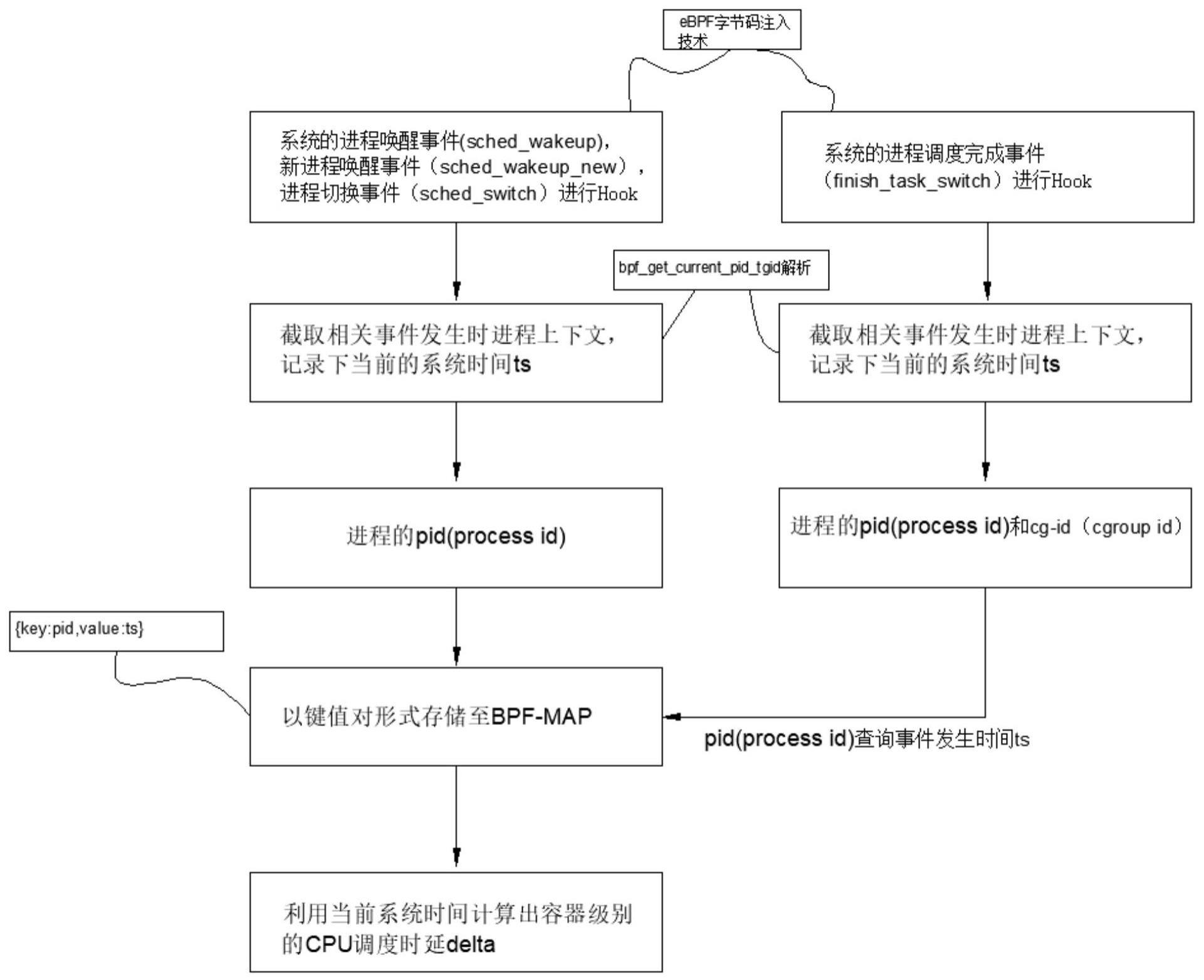
3、作为优选,所述监测容器的调度时延包括使用ebpf字节码注入技术分别对系统的进程唤醒事件(sched_wakeup),新进程唤醒事件(sched_wakeup_new),进程切换事件(sched_switch)进行捕获,截取相关事件发生时进程上下文,记录下当前的系统时间ts,利用bpf_get_current_pid_tgid解析出进程的pid(process id),将{key:pid,value:ts}以键值对形式存储至bpf-map中,
4、作为优选,所述监测容器的调度时延还包括对进程调度完成事件(finish_task_switch)进行捕获,截取相关事件发生时进程上下文并解析出进程的pid(process id)和cg-id(cgroup id),首先利用pid在map中查询出事件发生时间ts,利用当前系统时间计算出容器级别的cpu调度时延delta,将相关数据暴露至相关接口。
5、作为优选,所述监测容器申请内存的等待时延包括使用ebpf字节码注入技术分别对系统的直接内存回收开始事件(mm_vmscan_direct_reclaim_begin),内存控制组内存回收开始事件(mm_vmscan_direct_reclaim_begin),内存碎片尝试整理事件(mm_compaction_try_to_compact_pages)进行捕获,截取相关事件发生时进程上下文,记录下当前的系统时间ts,解析出进程的pid(process id),将{key:pid,value:ts}以键值对形式存储至bpf-map中。
6、作为优选,所述监测容器申请内存的等待时延还包括对系统的直接内存回收结束事件(mm_vmscan_direct_reclaim_end),内存控制组内存回收结束事件(mm_vmscan_direct_reclaim_end),内存碎片尝试整理回调事件(try_to_compact_pages)进行捕获,捕获相关事件发生时进程上下文并解析出进程的pid(process id)和cg-id(cgroup id),首先利用pid在map中查询出事件发生时间ts,利用当前系统时间计算出内存申请等待时延delta,将相关数据暴露至相关接口。
7、作为优选,所述监测容器io操作的等待时延包括使用ebpf字节码注入技术对系统的io预备调度事件(io_schedule_prepare)进行捕获,截取相关事件发生时进程上下文。记录下当前的系统时间ts,解析出进程的pid(processid),将{key:pid,value:ts}以键值对形式存储至bpf-map中。
8、作为优选,所述监测容器io操作的等待时延还包括对系统的io调度完成事件(io_schedule_finish),io调度超时事件(io_schedule_timeout)进行捕获。截取相关事件发生时进程上下文并解析出进程的pid(process id)和cg-id(cgroup id),首先利用pid在map中查询出事件发生时间ts,利用当前系统时间计算出容器级别的io调度时延delta,将相关数据暴露至相关接口。
9、作为优选,所述监测容器net的时延包括使用ebpf字节码注入技术对tcp完成三次握手后的连接建立成功事件进行捕获,获取该连接对应的sock结构体,从相应字段中解析出其srtt_us(以us为单位的往返时延)字段,然后根据__ck_common中的family字段解析出所使用的ip层协议,根据ip-protocol将rtt数据进行存储并暴露至相关接口,使用ebpf字节码注入技术对tcp协议栈中的发起连接建立事件(tcp_v4_connection和tcp_v6_connection)进行捕获,截取对应连接的sock结构体,记录下当前的系统时间ts,将{key:sock,value:ts}以键值对形式存储至bpf-map中
10、作为优选,所述监测容器net的时延还包括对tcp状态转变事件(tcp_rcv_state_process)进行捕获,检查当前的连接状态是否为tcp_syn_sent,若不是,则忽略,首先利用sock在map中查询出连接事件发生时间ts,利用当前系统时间计算出tcp连接时延delta,然后根据__ck_common中的family字段解析出所使用的ip层协议,其中的ip层协议是将ip层协议作为指标数据的特征值,对数据进行分类,根据ip-protocol将rtt数据进行存储并暴露至相关接口。
11、作为优选,对cgroup移除事件(cgroup_rmdir)进行捕获,当某个cgroup从系统中卸载时会触发该事件,此时将数据接口中该cg-id对应的数据指标一一删除。
12、综上所述,本发明有益效果是:
13、本发明通过监控资源使用方面的时延,能够准确反馈抖动是否因为资源的竞争而引起的,也能精确地判断出是哪些资源竞争激烈,集群调度系统,汇聚各个机器节点的资源时延数据,结合服务的资源使用特征,从而提升服务的部署密度,提高资源使用率。
- 还没有人留言评论。精彩留言会获得点赞!