基于模型损失容忍度的联邦学习设备调度方法
本发明涉及通信网络技术和机器学习领域,主要设计了基于模型损失容忍度的联邦学习设备调度方法。
背景技术:
1、随着各种新兴智能应用(如增强现实/虚拟现实、自动驾驶和数字孪生)的发展,物联网设备的数量呈爆炸式增长,并且大规模物联网设备产生海量的数据,为了利用这些数据进行传统机器学习算法,中央控制器需要访问所有用户的训练数据样本。然而,由于隐私安全问题,无线用户将他们的训练数据样本传输到中央服务器进行集中式机器学习是不切实际的。
2、联邦学习作为分布式机器学习的一种范式,能够在不收集所有用户的训练数据样本的情况下训练机器学习模型。它使用户能够协作学习共享的机器学习模型,同时将收集的数据保存在用户本地设备中。然而,由于带宽有限,在无线网络中,只有一部分设备可以参与联邦训练。同时,从用户终端设备发送到服务器端的联邦学习模型参数也会受到网络信道引起的错误和延迟。例如,在无线网络中执行联邦学习算法时,其收敛时间不仅取决于训练的轮数,还取决于每个训练步骤的机器学习模型参数的传输时间。同时,在每一轮训练当中,全局模型的收敛速度也随着参与训练设备的数量增多而变快。因此,对联邦学习设备选择的调度问题进行优化对于减少联邦学习训练时间和加快模型收敛速度是很有必要的。
3、除此之外,机器学习训练在每次迭代过程中,模型参数中的某些误差不一定会对模型精度产生太大影响;即使在早期迭代中发生的误差,也可以在后期迭代中进行修复。所以机器学习具有有界损失容忍特性,并且对于不同数据集同一模型的界限是相似的。不仅如此,在模型收敛方面,前层的下降梯度比后层的下降梯度具有更小的影响,所以有更大的容忍界限,这是因为在神经网络中,不同的层提取不同抽象级别的特征。通常,后层包含基于前层中的信息学习的累计信息,所以后层具有更高的重要性,有界容忍损失相对较小。
技术实现思路
1、发明目的:为解决联邦学习过程中由于网络状况较差(及信噪比较低)的情况下,终端设备传输模型参数出现数据丢失从而导致训练轮数增加和准确率降低甚至模型无法收敛的问题。本发明提出了一种基于模型损失容忍度的联邦学习设备调度方法,解决了由于模型参数以无线方式传输过程中出现数据丢失从而对联邦学习模型准确率产生的影响。
2、技术方案:为实现上述目的,本发明采用的技术方案为:
3、第一方面,本发明提供一种基于模型损失容忍度的联邦学习设备调度方法,包括:
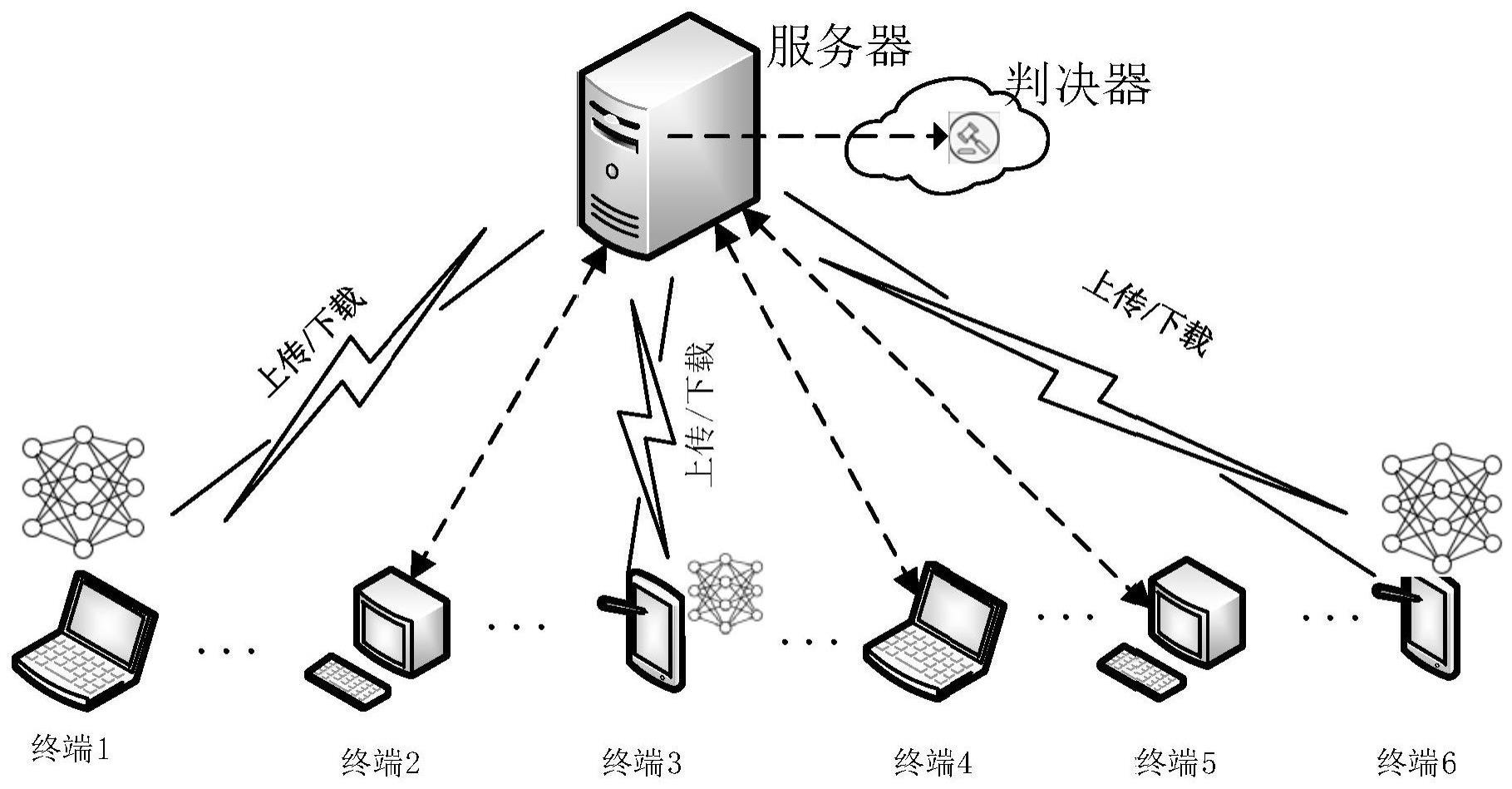
4、服务器获取终端设备上传的终端设备信息,根据终端设备信息计算对应终端设备当前信道的误码率;其中所述终端设备信息包括传输功率、信道带宽、信道增益和噪声功率谱密度;
5、将所述误码率与判决器中设置的容忍阈值进行比较,当误码率小于判决器中设置的阈值时,选取对应的终端设备参与训练,判决器将参与训练的终端设备选择结果交给服务器;
6、服务器将初始全局模型发送给参与训练的终端设备;
7、终端设备利用本地训练数据集对初始全局模型进行本地训练得到训练后的本地模型;
8、以训练后的本地模型和全局模型收敛为目标,迭代执行以下循环步骤:
9、服务器获取所有参与训练的终端设备训练后的本地模型参数,对本地模型参数进行聚合得到更新后的全局模型,并将更新后的全局模型传输给参与训练的终端设备;
10、各终端设备根据接收的全局模型更新本地模型并进行新一轮训练,更新训练后的本地模型。
11、在一些实施例中,服务器根据不同的训练任务构建相应的初始全局模型;搭建判决器,根据初始全局模型设置容忍阈值,并将模型参数分为前层参数、中层参数、后层参数,按照顺序对前层参数、中层参数、后层参数分别设置不同的容忍阈值。
12、在一些实施例中,服务器获取终端设备上传的终端设备信息,根据终端设备信息计算对应终端设备当前信道的误码率,包括:
13、根据终端设备的传输功率、信道带宽、信道增益和噪声功率谱密度,计算得到对应终端设备的信噪比;
14、根据终端设备的信噪比计算得到对应终端设备当前信道的误码率。
15、进一步地,所述的基于模型损失容忍度的联邦学习设备调度方法,其特征在于,根据终端设备的传输功率、信道带宽、信道增益和噪声功率谱密度,计算得到对应终端设备的信噪比包括:
16、
17、其中pi为终端设备i的传输功率,hi为信道增益,b为信道带宽,n0为噪声功率谱密度。
18、进一步地,根据终端设备的信噪比计算得到对应终端设备当前信道的误码率包括:
19、
20、其中,终端设备i采用m-qam调制方式表示为其中u表示时隙索引,l表示子信道数。
21、在一些实施例中,终端设备根据接收的全局模型更新本地模型并进行新一轮训练,包括:
22、终端设备接收服务器下达的训练任务,通过接收服务器广播的全局模型更新本地模型,然后依据本地训练数据集,使用随机梯度下降算法训练更新本地模型,即:
23、
24、其中ωi,k(j)表示第i个终端在第k轮本地训练中训练j次后的本地模型参数,η表示学习率,τ表示更新梯度的次数,由数据样本数si和随机抽样的小批量db,o样本数di决定,根据db,i计算所得,表示了小批量损失函数下降最快的方向。
25、在一些实施例中,服务器获取所有参与训练的终端设备训练后的本地模型参数,对本地模型参数进行聚合得到更新后的全局模型,包括:
26、服务器接收所有参与训练的终端设备训练后的本地模型参数,使用fedavg聚合算法执行模型聚合,生成一个新的全局模型参数;
27、fedavg聚合公式为:
28、其中ωk+1表示第k轮聚合后的全局模型参数并作为第k+1轮训练的初始化全局模型参数,si为第i个终端设备持有的数据集样本数,m为参与训练的终端设备总数,stotal为m个终端设备持有的总样本数。
29、第二方面,本发明提供了一种基于模型损失容忍度的联邦学习设备调度装置,包括处理器及存储介质;
30、所述存储介质用于存储指令;
31、所述处理器用于根据所述指令进行操作以执行根据第一方面所述的方法。
32、第三方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的方法。
33、第四方面,本发明提供了一种设备,包括,
34、存储器;
35、处理器;
36、以及
37、计算机程序;
38、其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现上述第一方面所述的方法。
39、有益效果:本发明提出了基于模型损失容忍度的联邦学习设备调度方法,该方法解决了联邦学习过程中由于网络信道较差而无法选择最优设备参与训练的问题。本发明公开了一种基于模型损失容忍度的联邦学习设备调度方法,在联邦学习训练之前增加了设备调度器。对于无线网络中由于网络状况差引起的错误和延迟问题,依据服务器端内置判决器进行设备选择,判决方法即是本地模型参数在无线传输过程中数据丢失率不超过判决器中设置的阈值。并在每轮训练中不断重复这个过程,使得每轮训练选出尽可能多的设备,以此来提高模型准确率。
- 还没有人留言评论。精彩留言会获得点赞!