文本匹配的方法、装置及电子设备与流程
本技术涉及自然语言处理领域,具体而言,涉及一种文本匹配的方法、装置及电子设备。
背景技术:
1、随着近些年人工智能技术的迅速发展,特别是自然语言处理的日益更新,文本检索匹配成为一个自然语言处理领域一个比较核心的任务,不管是在对话系统、推荐系统、搜索引擎中,文本匹配都是必不可少的。因此,中文文本检索匹配方法的优劣将严重影响相关企业业务的健康发展。
2、为实现数字化转型战略性任务,需要将数据域中所存在的m域、b域、o域等多个生产域的数据进行融合比对,其中某些信息性的数据以中文文本形式存储,由于历史及条线管理等原因,这些文本之间存在一定的相似度,却无法实现完全精准匹配(如m域的供应商名称与b域的客户名称),使用传统的sql查询匹配到的结果有限,而使用基于规则的相似度检索匹配方法(代表性的有tf-idf)往往忽略了语义的相关性,因此存在匹配度较低的技术问题。
3、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术实施例提供了一种文本匹配的方法、装置及电子设备,以至少解决相关技术中在对不同生产域之间存储的具有一定相似度的文本进行匹配时存在匹配度较低的技术问题。
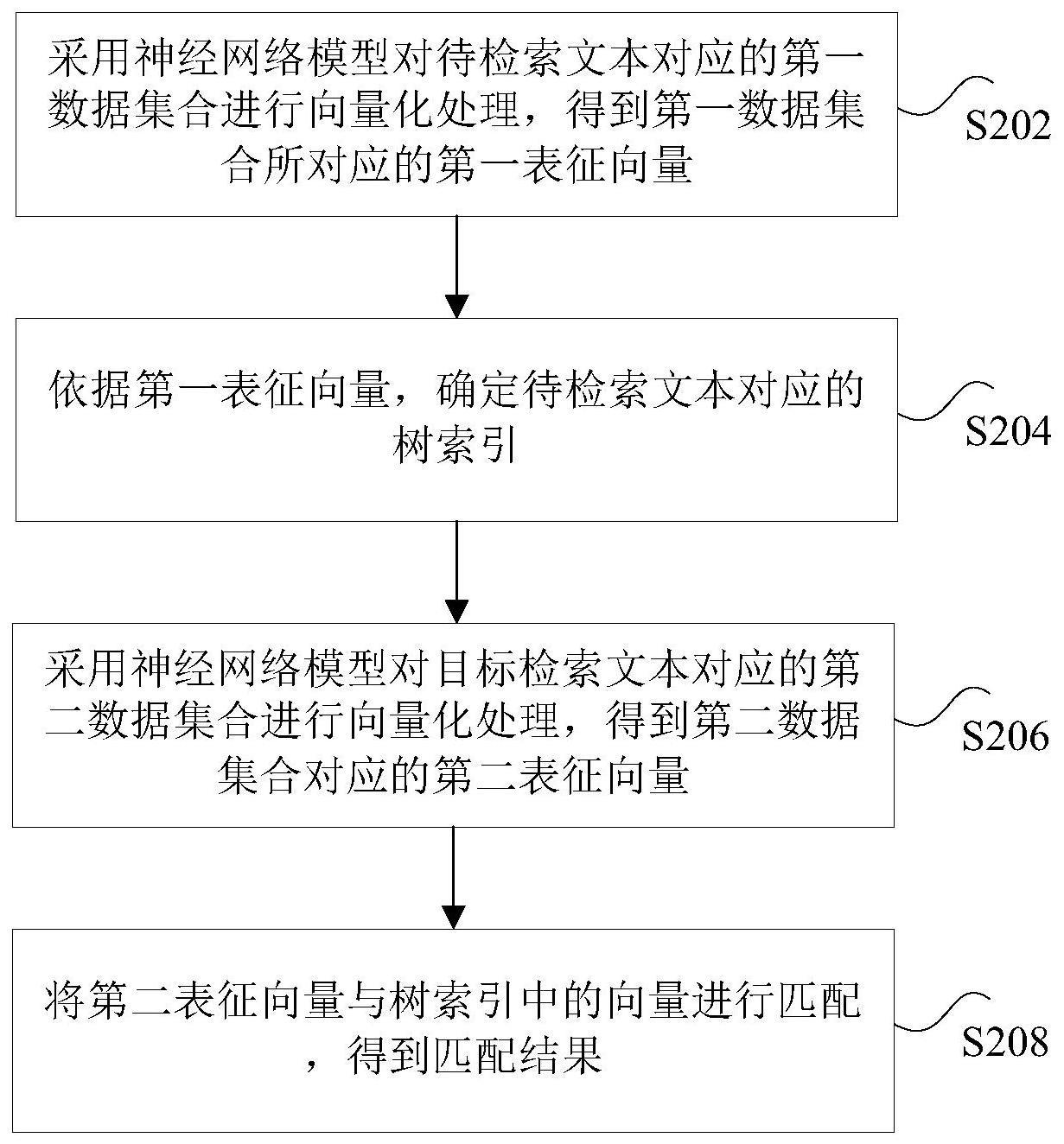
2、根据本技术实施例的一个方面,提供了一种文本匹配的方法,包括:采用神经网络模型对待检索文本对应的第一数据集合进行向量化处理,得到第一数据集合所对应的第一表征向量,其中,神经网络模型中的参数至少由对抗梯度确定,对抗梯度为第一数据集合对应的原始表征向量的原始梯度和增加扰动后的第二梯度累加得到;依据第一表征向量,确定待检索文本对应的树索引,其中,树索引用于匹配与目标检索文本所对应的文本;采用神经网络模型对目标检索文本对应的第二数据集合进行向量化处理,得到第二数据集合对应的第二表征向量;将第二表征向量与树索引中的向量进行匹配,得到匹配结果。
3、可选地,采用神经网络模型对待检索文本对应的第一数据集合进行向量化处理,包括:对第一数据集合进行分词处理,得到第一子词序列;按照预设重复率随机重复第一子词序列中的子词,得到第二子词序列;将第一子词序列和第二子词序列分别通过编码器随机删除对应的子词,得到正样本对;将第一子词序列和第二子词序列分别通过动量编码器生成负样本对。
4、可选地,采用神经网络模型对待检索文本对应的第一数据集合进行向量化处理,包括:确定神经网络模型的损失函数,其中,损失函数由对第一数据集合进行批处理时一个批处理中包含的数据大小和条件概率确定,条件概率为正样本对中第一个样本出现的情况下,第二个样本出现的条件概率。
5、可选地,确定神经网络模型的损失函数之后,方法还包括:确定由正样本对和负样本对构成的第一矩阵的原始梯度,其中,第一矩阵由第一数据集合对应的原始表征向量确定;依据原始梯度和扰动参数,确定扰动值,其中,扰动值的方向和原始梯度的方向一致;将扰动值加入到第一矩阵中得到第二矩阵,并确定第二矩阵对应的第二梯度;将第二梯度累加到原始梯度上,得到对抗梯度。
6、可选地,通过以下方式调整神经网络模型的参数:确定神经网络模型的动量维度的数量为第一数量;确定当前次数的上一次对神经网络模型进行迭代得到的第一参数;在当前次数对神经网络模型的参数进行调整时,聚合神经网络模型在每个动量维度下的动量,得到动量和;依据第一数量、第一参数和动量和,确定在当前次数下神经网络模型对应的参数。
7、可选地,通过以下方式确定在当前次数下对神经网络模型进行迭代时每个动量维度的动量:确定当前次数的上一次对神经网络模型进行迭代时目标动量维度上的第一动量,其中,目标动量维度为第一数量的动量维度中的任意一个动量维度;确定神经网络模型在目标动量维度上的阻尼系数;确定当前次数的上一次对神经网络模型进行迭代时所对应的第一对抗梯度;依据第一动量、阻尼系数和第一对抗梯度,确定在当前次数下对神经网络模型进行迭代时在目标动量维度上的第二动量。
8、可选地,依据第一表征向量,确定待检索文本对应的树索引,包括:从第一表征向量中对应的空间中随机选取两个点,作为初始中心节点,其中,第一表征向量中的每个向量对应空间内的一个节点;依据初始中心节点,对第一表征向量中的其他节点执行聚类,得到收敛后的两个聚类中心点;将两个聚类中心点之间的连线的垂线确定为超平面,其中,超平面将第一表征向量对应的空间划分为两个子空间;在每个子空间内重复执行空间划分后确定每个子空间内的超平面,直至最终划分的子空间内包含的子节点的数量小于或等于预设数量时停止执行空间划分,其中,每个子空间及该子空间中包含的子节点作为树索引的一个分支。
9、可选地,将第二表征向量与树索引中的向量进行匹配,得到匹配结果,包括:将第二表征向量与树索引中的表征向量进行相似度计算;输出相似度大于预设阈值的向量,得到匹配结果。
10、根据本技术实施例的另一方面,还提供了一种文本匹配的装置,包括:第一处理模块,用于采用神经网络模型对待检索文本对应的第一数据集合进行向量化处理,得到第一数据集合所对应的第一表征向量,其中,神经网络模型中的参数至少由对抗梯度确定,对抗梯度为第一数据集合对应的原始表征向量的原始梯度和增加扰动后的第二梯度累加得到;确定模块,用于依据第一表征向量,确定待检索文本对应的树索引,其中,树索引用于匹配与目标检索文本所对应的文本;第二处理模块,用于采用神经网络模型对目标检索文本对应的第二数据集合进行向量化处理,得到第二数据集合对应的第二表征向量;匹配模块,用于将第二表征向量与树索引中的向量进行匹配,得到匹配结果。
11、根据本技术实施例的又一方面,还提供了一种电子设备,包括:存储器,用于存储程序指令;处理器,与存储器连接,用于执行实现以下功能的程序指令:采用神经网络模型对待检索文本对应的第一数据集合进行向量化处理,得到第一数据集合所对应的第一表征向量,其中,神经网络模型中的参数至少由对抗梯度确定,对抗梯度为第一数据集合对应的原始表征向量的原始梯度和增加扰动后的第二梯度累加得到;依据第一表征向量,确定待检索文本对应的树索引,其中,树索引用于匹配与目标检索文本所对应的文本;采用神经网络模型对目标检索文本对应的第二数据集合进行向量化处理,得到第二数据集合对应的第二表征向量;将第二表征向量与树索引中的向量进行匹配,得到匹配结果。
12、根据本技术实施例的再一方面,还提供了一种非易失性存储介质,该非易失性存储介质包括存储的计算机程序,其中,该非易失性存储介质所在设备通过运行计算机程序执行上述文本匹配的方法。
13、在本技术实施例中,采用神经网络模型对待检索文本对应的第一数据集合进行向量化处理,得到第一数据集合所对应的第一表征向量,其中,神经网络模型中的参数至少由对抗梯度确定,对抗梯度为第一数据集合对应的原始表征向量的原始梯度和增加扰动后的第二梯度累加得到;依据第一表征向量,确定待检索文本对应的树索引,其中,树索引用于匹配与目标检索文本所对应的文本;采用神经网络模型对目标检索文本对应的第二数据集合进行向量化处理,得到第二数据集合对应的第二表征向量;将第二表征向量与树索引中的向量进行匹配,得到匹配结果,达到了通过对抗梯度优化神经网络模型的参数的目的,从而实现了提高待检索文本与目标检索文本进行文本匹配时的匹配度的技术效果,进而解决了相关技术中在对不同生产域之间存储的具有一定相似度的文本进行匹配时存在匹配度较低的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!