一种SPISlave芯片设计中去毛刺的方法及电路与流程
本发明涉及一种spi slave芯片设计领域,特别是spi slave芯片设计中去毛刺的方法及电路。
背景技术:
1、spi(serial peripheral interface,串行外围设备接口),是motorola公司提出的一种同步串行接口技术,是一种高速、全双工、同步通信总线,在芯片中只占用四根管脚用来控制及数据传输。广泛用于eeprom、flash、rtc(实时时钟)、adc(数模转换器)、dsp(数字信号处理器)以及数字信号解码器上。
2、spi采用主从模式(master-slave)的控制方式,支持单master对一个或多个slave。spi规定了两个spi设备之间通信必须由主设备spi master来控制从设备spislave。也就是说,如果fpga是主机的情况下,不管是fpga给芯片发送数据还是从芯片中接收数据,写verilog逻辑的时候片选信号cs与串行时钟信号sck必须由fpga来产生,一个spimaster可以设置多个片选(chip select)来控制多个spi slave。spi协议还规定spi slave设备的clock由spi master通过sck管脚提供给spi slave,spi slave本身不能产生或控制clock,没有clock则spi slave不能正常工作。
3、如图1所示,单master对多slave的典型结构,其中:
4、(1)、sck(serial clock):sck是串行时钟线,作用是spi master向spi slave传输时钟信号,控制数据交换的时机和速率;
5、(2)、mosi(master out slave in):在spi master上也被称为tx-channel,作用是spi master主机给spi slave从机发送数据;
6、(3)、cs/ss(chip select/slave select):作用是spi master选择与哪一个spislave通信;
7、(4)、miso(master in slave out):在spi master上也被称为rx-channel,作用是spi master主机接收spi slave从机传输过来的数据;
8、因为,spi总线在传输数据data的同时也传输了时钟信号clock,所以spi协议是一种同步(synchronous)传输协议。spi master会根据将要交换的数据产生相应的时钟脉冲,组成时钟信号clock,时钟信号通过时钟极性(cpol)和时钟相位(cpha)控制主、从两个spi设备何时交换数据以及何时对接收数据进行采样,保证数据在两个spi设备之间是同步传输,如下:
9、(1)、cpol(clock polarity)时钟极性,cpol配置spi总线的极性,极性会直接影响spi总线空闲时的时钟信号是高电平还是低电平,由于数据传输往往是从跳变沿开始的,也就表示开始传输数据的时候,是下降沿还是上升沿:
10、如图2所示;cpol=1:表示空闲时是高电平,无数据传输时的空闲状态(高电平),空闲状态后第一个跳变沿,下降沿(高电平->低电平),表示有效数据的开始;
11、cpol=0:表示空闲时是低电平,无数据传输时的空闲状态(低电平),空闲状态后第一个跳变沿,上升沿(低电平->高电平),表示有效数据的开始;
12、(2)、cpha(clock phase)时钟相位,cpha配置spi总线的相位,而相位,直接决定spi总线从那个跳变沿开始采样数据,一个时钟周期会有2个跳变沿,cpha决定从哪个跳变沿开始采样,
13、如图3所示,cpha=0:表示从第一个跳变沿开始采样;
14、cpha=1:表示从第二个跳变沿开始采样;
15、一个时钟周期会有两个跳变沿,至于跳变沿究竟是上升沿还是下降沿,这取决于cpol,cpha只决定是哪个跳变沿采样。
16、通过cpol和cpha两两不同组合,形成了spi总线有4种不同模式。
17、 序号 mode cpol cpha 1 mode 0 0 0 2 mode 1 0 1 3 mode 2 1 0 4 mode 3 1 1
18、(1)、mode 0(cpol=0;cpha=0),如图4所示:
19、cpol=0:空闲时是低电平,周期内第1个跳变沿是上升沿,第2个跳变沿是下降沿;
20、cpha=0:数据在第一个周期的第1个跳变沿(上升沿)采样;
21、(2)、mode 1(cpol=0;cpha=1),如图5所示:
22、cpol=0:空闲时是低电平,周期内第1个跳变沿是上升沿,第2个跳变沿是下降沿;
23、cpha=1:数据在第一个周期的第2个跳变沿(下降沿)采样;
24、(3)、mode 2(cpol=1;cpha=0),如图6所示:
25、cpol=1:空闲时是高电平,周期内第1个跳变沿是下降沿,第2个跳变沿是上升沿;
26、cpha=0:数据在第一个周期的第1个跳变沿(下降沿)采样;
27、(4)、mode。2(cpol=1;cpha=1),如图7所示:
28、cpol=1:空闲时是高电平,周期内第1个跳变沿是下降沿,第2个跳变沿是上升沿;
29、cpha=1:数据在第一个周期的第2个跳变沿(上升沿)采样。
30、通过以上介绍,可以看出spi一个时钟沿只能传输一个位的数据(一个时钟周期内传输1个bit数据);如何在时钟频率不变的情况下提高传输速度呢?motorola公司对spi接口进行了扩展,在spi协议的基础上,motorola公司对其功能进行了增强,增加了队列传输机制,推出了队列串行外围接口协议(即qspi协议,qspi是queued spi的简写)。qspi是一种专用的通信接口,连接单、双或四条数据线,甚至六条数据线的spi slave存储介质,比spi应用更加广泛。如图8所示,一种四线的qspi slave,具有8个引脚,分别如下:
31、 名称 功能 vcc 电源正 gnd 电源地 cs 传输控制–片选 clk 传输控制–时钟 mosi 可以复用 miso 可以复用 wp 可以复用 hold 可以复用
32、以上8个引脚除了电源引脚(vcc,gnd)以及控制传输的cs、clk不能复用外,其他的四个引脚都是可以复用为数据传输引脚的,这里设定的场景是单向通信,比如只读的操作中,只写的操作中,并非双工通信,全双工并不常用,因此扩展了mosi和moso的用法,让它们工作在半双工,这样一个时钟周期内就能传输2个bit数据,加倍了数据传输,实现高速采样,如果spi slave存储介质采用六条数据线,则一个时钟周期内就能传输4个bit数据,可以实现更高速采样。
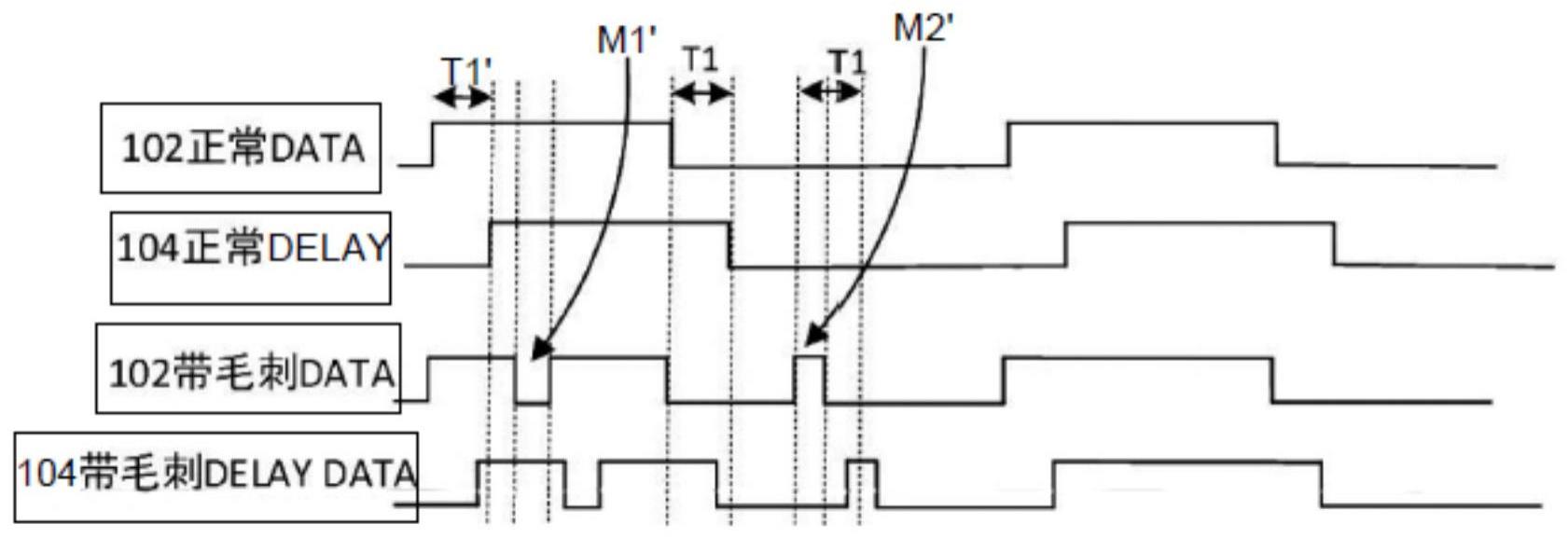
33、在spi slave芯片设计中接收clock和data数据,clock通过clock tree(时钟树)同时到达spi slave芯片中的寄存器,clock tree(时钟树)会带来延时,经过延时后到clock通过clock tree(时钟树)到达spi slave ip中的寄存器的ck端,data数据经过复用选择直接会到寄存器的d端,data数据与clock tree存skew差(时间差),需要增加delaycell(延时单元)做齐到达寄存器d端前的data数据。如图9所示,4个spi slave芯片106`的设计(即caption data register(3:0)(表示4路数据传输),spi slave芯片106`接受data(数据)102`(来源于spi master传送),data(数据)102`通过data path delay path(数据链路延时线路)103`后,分别传输到spi slave芯片106`的寄存器的d端104`,spi slave芯片106`接受到的clock(时钟信号)100`(为spi master发出的控制信号),经过clock treedelay path(时钟树延时线路)105`后,分别控制spi slave芯片106`的寄存器的ck端101`。
34、如图9、图10所示,在时间在的时间段内,clock的第一个跳变沿(上升沿)t3时,在clock的的时段内,4路数据data0、data1、data2、data3经data pathdelay path(数据链路延时线路)103`补齐后,理论上数据data应该完全与clock对齐,但实际数据传输过程,并没有绝对与clock对齐,各路数据data与clock之间仍存在间隙差(skew),而采样需要数据data与clock在对齐的时间内才能进行,如图10中所示t1`表示clock上升沿来前data需要先建立好稳定的时间,t2`表示clock上升沿来后data需要保持住的时间。
35、如果spi slave芯片在使用过程中受到静电、电源不稳定、或通路被干扰等因素影响,data会存在毛刺,如图11所示,理论上,正常的data(数据)102`通过data path delaypath(数据链路延时线路)103`后(参见图9),传输到spi slave芯片106`的寄存器的d端104`(参见图9),寄存器的d端104`正常数据data的波形与正常的data(数据)102`之间除了存在延时t1`之外,波形仍然是保持一致的,然而实际中,带毛刺m1`、m2`的data数据102`通过data path delay path(数据链路延时线路)103`后(参见图9),再传输到spi slave芯片106`的寄存器的d端104`(参见图9),寄存器的d端104`数据data仍然是带毛刺的data(数据),这种带毛刺data会影响到数据的采样效率,为了避免这种情况,行业中通常采用降低频率来进行采样,但是,当今人们都在追求高速运算,往往需要进行高速采样,在高速采样过程中,这种带毛刺的data影响更加明显,往往导致数据存储错误。
36、为此,发明人经过细心研究,发明了一种在现有的芯片资源下,不增加资源,在跑高速的情况仍能进行采样spi slave的芯片设计方法及电路,特别是对于qspi这样跑高速的芯片尤为适用。
技术实现思路
1、本发明提供了一种spi slave芯片设计中去毛刺的方法,在在不增加资源情况下增加了去毛刺的功能,实现高速采样。
2、同时,本发明还提供了一种spi slave芯片设计中去毛刺的电路,在在不增加资源情况下增加了去毛刺的功能,实现高速采样。
3、实现上述目的所采取的技术方案是:
4、一种spi slave芯片设计中去毛刺的方法,在spi slave芯片的数据链路延时线路中原有设计的延时单元电路的基础上,减少原有延时单元电路中延时单元的个数,增加与滤波单元电路,滤波单元电路的延时与减少的数个延时单元的总延时相同,即数据data经过延时单元电路中剩余的延时单元与滤波单元电路到达spi slave芯片的寄存器的d端的延时总和,与时钟信号经过时钟树延时线路到spi slave芯片的寄存器的ck端的延时仍保持基本一致。
5、进一步,减少原有延时单元电路中延时单元的个数与增加的滤波单元电路的级数相同。
6、一种spi slave芯片设计中去毛刺的电路,包括在spi slave芯片的数据链路延时线路中设计有延时单元电路,在原有设计延时单元电路的础上,减少原有延时单元电路中延时单元的个数,增加与滤波单元电路,滤波单元电路的延时与减少的数个延时单元的总延时相同,即数据data经过延时单元电路中剩余的延时单元与滤波单元电路到达spislave芯片的寄存器的d端的延时总和,与时钟信号经过时钟树延时线路到spi slave芯片的寄存器的ck端的延时仍保持基本一致。
7、进一步,所述的数据链路延时线路分成两条支路,一条支路直接接入滤波单元电路的一个输入端,另一条支路接入延时单元电路的输入端,延时单元电路的输出端接入滤波单元电路的另一个输入端。
8、进一步,所述的数据链路延时线路中的延时单元电路减少三个延时单元,增加一个三级滤波单元电路,所述的三级滤波单元电路包括一个与非门、三个或非门、一个反相器,所述的一个与非门、三个或非门、一个反相器构成的三级电路的延时与减少三个延时单元的总延时相同,所述的数据链路延时线路分成三条支路,第一条支路接入与非门的一个输入端,第三条支路接入第一个或非门的一个输入端,第二条支路接入延时单元电路的输入端,延时单元电路的输出端分两成条分支路,一条分支路接入与非门的另一个输入端,另一条分支路接入第一个或非门的另一个输入端,第一个或非门的输出端接第二个或非门的一个输入端,第二个或非门的输出端接第三个或非门的一个输入端,与非门的输出端接第三个或非门的另一个输入端,第三个或非门的输出端接第二个或非门的另一个输入端,第三个或非门的输出端最后接反相器。
9、本发明在现有的芯片资源下,不增加资源,替换掉原有设计延时单元电路几个延时单元delay cell,增加具有去毛刺的滤波功能的滤波单元电路,目的是要恢复经过延时后带毛刺的data的上升沿和下降沿,使得经过延时后data数据波形恢复到正常状态,符合芯片跑高速的要求,同时选取合适的电路或选配电子元器件使得data经延时单元电路与滤波单元电路到寄存器的d端的延时总和与clk到寄存器的ck端的延时保持一致,达到数据采样的需求。
- 还没有人留言评论。精彩留言会获得点赞!