基于VLP输入端细粒度对齐的跨模态赞助搜索方法及系统
本发明涉及跨模态数据搜索领域,具体涉及一种基于跨模态预训练和视觉语言细粒度对齐的跨模态检索方法及系统。
背景技术:
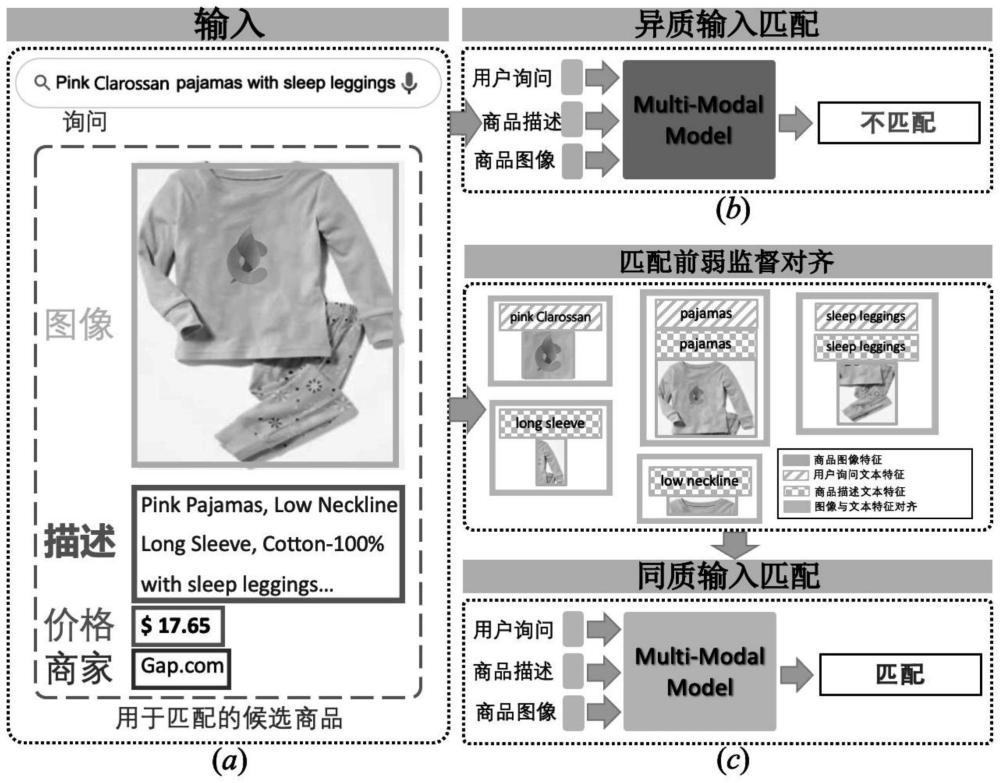
1、赞助搜索(sponsored search)是搜索引擎平台上广泛使用的商业模式,在其中,赞助广告与其他搜索结果一同呈现给用户。为查询展示相关广告将显著提高合适产品的曝光度,同时有效满足买家的需求。因此,赞助搜索系统需要准确建模查询和广告之间的相关性。除了纯文本广告外,带有图像的多模态广告已经成为一种新趋势。广告中的图像为文本提供了补充的产品细节。其要求模型利用商品图像信息补充或纠正商品文本描述中的缺失与错误的信息。因此,准确地对视觉和文本广告信息,并共同将这些对齐内容与查询进行匹配,对于实现高质量的赞助搜索至关重要。
2、跨模态赞助搜索(cross-modal sponsored search)任务,类似传统的图像-文本匹配任务,其利用图像-文本相关性学习方法来建模用户文本查询和多模态商品信息之间的相关性。跨模态赞助搜索典型的解决方案是adscvlr[1],它基于视觉和语言预训练(vision-language pretraining,vlp)框架,将用户查询和商品描述文本作为语言输入,将相应的商品图像作为视觉输入。所有输入都被馈送到单流的vlp模型中,以计算它们的相似度。然而,这种解决方案很难满足细粒度的赞助搜索,因为用户查询-商品匹配和图像-文本匹配之间存在很大差异。在多模态赞助搜索中,多模态广告包含更详细的产品信息,例如颜色、品牌、风格、价格和卖家。查询通常是短语[1],其通常涉及商品的部分和细粒度特征。因此,准确地对齐商品图像中的区域和用户查询中的单词对于赞助搜索非常重要。然而,在vlp中通过注意力机制隐式相关联视觉区域和单词,这种方法在没有有监督标注的区域-单词的情况下获得准确的对齐,这是很具有挑战性的。除了跨模态对齐,vlp模型还需要衡量用户查询与来自不同模态的对齐商品之间的相关性。因此,对于vlp模型来说,同时实现上述两个目标具有挑战性且需要大量数据。
3、跨模态赞助搜索模型实际上是一种相关性建模模型,而相关性建模模型是信息检索的关键组成部分。先前的研究[2,3,4,5]主要关注于语言模型,从文本中提取信息,而忽视了视觉信息的价值。fashionber[6]考虑了图像和文本信息,用于解决时尚领域中的图像-文本匹配问题。adscvlr首次提出了一种vlp方法用于跨模态赞助搜索,以建模用户查询、商品文本和商品图像之间的相关性,相比现有的vlp模型,取得了明显的性能提升。adsclvr还使用知识蒸馏训练了一个两流学生模型,以满足在线计算和延迟约束。然而,由于多模态输入未对齐,adsclvr很难将商品图像中的区域准确地与查询中的单词相关联,当广告文本不足或不准确时,会导致预测不准确。
4、目前跨模态赞助搜索主要存在以下问题:
5、1.由于现有方法基于vlp构建跨模态赞助搜索模型,而在vlp中通过注意力机制隐式相关联视觉区域和单词,这种方法在没有有监督标注的区域-单词的情况下很呐获得准确的细粒度对齐。
6、2.现有跨模态赞助搜索模型需要衡量用户查询与来自不同模态的对齐商品之间的相关性,而由于视觉语言在输入端没有对齐而需要大量有监督商品-文本对进行训练。
技术实现思路
1、针对上述不足,本发明提出了一种基于vlp输入端细粒度对齐的跨模态检索方法及系统,旨在改进电商平台中商品和用户查询之间的匹配效率和准确性,尤其是在数据稀缺的条件下。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于vlp输入端细粒度对齐的跨模态赞助搜索方法,包括以下步骤:
4、由商品目标表示构建视觉向量表示空间v,由商品描述单词嵌入构建语言单词向量表示空间t,由线性映射walign来对齐v和t的向量表示空间;
5、基于walign构建对齐模块valse,对valse进行训练,包括:利用对抗训练对商品目标与单词进行分布对齐,在结构化词典的监督下对walign进行粗略调整,在语义词典的语义监督下对walign进行精细调整;
6、基于vinvl模型构建vin-valse模型,其中vinvl模型的输入层的原始线性映射替换为valse;利用vinvl模型的预训练权重初始化vin-valse模型的参数,然后将vin-valse模型的输入层的线性映射层替换成已训练好的对齐模块valse;
7、利用跨模态赞助搜索训练数据对vin-valse模型进行微调训练;
8、利用微调完成后的vin-valse模型对用户查询输入的文本信息进行处理,找出对应的商品信息。
9、进一步地,线性映射walign的式子如下:
10、
11、其中,argmin表示最小化wv-t的函数,w表示vinvl模型的输入层的原始线性映射,表示d2×d1的矩阵空间,d1表示v中特征向量的维度,d2表示t中特征向量的维度。
12、进一步地,利用对抗训练对商品目标与单词进行分布对齐的步骤包括:
13、将walign作为生成器,由参数化的二元分类器θd作为判别器,二者进行对抗训练,判别器的目标是尽量区分从walign转换得到的表示,生成器的目标是尽量欺骗判别器的正确预测。
14、进一步地,判别器的目标是通过最小化以下目标函数来区分从walign转换得到的表示:
15、
16、其中,表示商品目标表示vi来自视觉向量表示空间v的概率,表示商品描述单词嵌入tj来自语言单词向量表示空间t的的概率,m,n分别表示vi,tj的数量。
17、进一步地,生成器的目标是通过最小化以下目标函数来欺骗判别器的正确预测:
18、
19、其中,表示商品目标表示vi来自语言单词向量表示空间t的概率,表示商品描述单词嵌入tj来自视觉向量表示空间v的概率,m,n分别表示vi,tj的数量。
20、进一步地,结构化词典为根据频率最高的前若干个单词,采用跨域相似度局部缩放度量方法从walign和t中保留相互最近的邻居构建得到;语义词典为由成对的目标-单词样本构建得到。
21、进一步地,利用跨模态赞助搜索训练数据对vin-valse模型进行微调训练的步骤包括:
22、在跨模态赞助搜索训练集上基于mtm和查询-商品对比学习这两个预训练任务来预训练vin-valse模型;
23、其中,mtm任务是以15%的概率随机遮蔽每个单词获得的输入token,并用特殊标记[mask]替换被遮蔽的标记,mtm任务的目标是基于其他标记通过最小化损失函数来预测遮蔽的标记;
24、其中,查询-商品对比学习任务是以25%的概率用训练集中的不同用户查询替换当前用户查询来构造每个用户查询-商品对的负样本,将输出嵌入作为分类器的输入,通过最小化对比损失函数用于预测查询是否与商品匹配或不匹配;
25、根据mtm和查询-商品对比学习这两个预训练任务的损失之和得到vin-valse的预训练损失函数;
26、将带有真实标签的用户查询-商品信息对输入到vin-valse模型中进行预测,将预测的结果输入到二分类器中预测查询与商品是否匹配,通过最小化交叉熵损失函数来提高预测准确度,该交叉熵损失函数基于vin-valse的预训练损失函数构建。
27、进一步地,mtm任务的损失函数如下:
28、
29、其中,hi表示每个单词获得的输入token,表示预测时基于的其他标记,表示从训练数据d中随机采样hj的负数期望,p表示预测概率。
30、进一步地,查询-商品对比学习任务的对比损失函数如下:
31、
32、其中,f(qi,ai)表示分类器,qi表示第i个用户查询,ai表示对应的商品信息,p表示预测概率;c表示预测的标签,c=0表示查询与商品匹配,c=1表示查询与商品不匹配;表示从包含正样本和负样本的训练数据d中随机采样(qi,ai;c)的负数期望。
33、进一步地,vin-valse的预训练损失函数如下:
34、l=lmtm+lcl。
35、进一步地,交叉熵损失函数如下:
36、
37、其中,表示从l中随机采样(qi,ai)的负数期望,qi表示第i个用户查询,ai表示对应的商品信息,l表示vin-valse的预训练损失函数;yi表示真实标签,yi=0表示查询与商品匹配,yi=1表示查询与商品不匹配;表示预测标签。
38、一种基于vlp输入端细粒度对齐的跨模态赞助搜索系统,包括存储器和处理器,在该存储器上存储有计算机程序,该处理器执行该程序时实现上述方法的步骤。
39、本发明的技术方案具有以下优点:
40、1.结构一致性启发:受人类认知中多模态共线结构一致性的启发,该模型通过视觉语言结构一致性对视觉目标和语言文字进行有效对齐,增加了模型的自然性和可解释性。
41、2.输入端细粒度对齐:通过在输入端进行细粒度的对齐,该方法能更准确地模拟用户查询和多模态广告之间的复杂关系。这是尤其重要的,因为在赞助搜索中,用户的查询通常是短且具体的。
42、3.训练效率和性能提升:模型采用先对齐,后交互的预训练策略,解耦了多模态交互模块中的对齐和关联,这有助于使用更少的数据达到更优的性能。
43、4.弱监督学习:模型在没有有监督标注的区域-单词的情况下也能实现准确的对齐,降低了标注成本,并加速了模型的训练和部署。
44、5.跨模态性能优化:该方法不仅对齐了视觉和语言信息,还将其与视觉语言预训练模型结合,从而优化了模型在不同模态数据(例如,图像、文本)上的表现。
45、6.应用广泛性:虽然该模型主要用于电商环境,但其结构和方法也可能适用于其他需要高效跨模态信息检索和对齐的场景。
46、7.产品信息的丰富性:在电商环境下,商品信息通常包括多个维度(如颜色、品牌、价格等),本模型能够有效地捕捉这些细粒度信息,从而提供更精准的匹配。
47、综上所述,本发明提供的技术方案,通过先进的视觉和语言对齐技术,提高了跨模态信息检索的准确性和效率。
- 还没有人留言评论。精彩留言会获得点赞!