一种机器人问答方法及存储介质与流程
本技术涉及人工智能,具体涉及一种基于rasa的自定义nlu模型和llm结合的机器人问答方法。
背景技术:
1、近年来,智能问答机器人已经成为诸多领域的研究热点,已经广泛应用于电商平台、教育辅助、医疗咨询等各种场景,尤其是随着大语言模型llm(large language model,如chatgpt、glm等)的出现,使得智能问答机器人取得了突破性的进展,其通过深度学习技术从海量文本中数据中学习,通过上下文理解和推理生成回答,具备了极高水平的自动问答能力。然而,尽管llm已经取得了巨大突破,仍面临一些限制和挑战,由于llm是在通用的大数据集上训练的,其具有通用性但不具备特定领域的知识,无法回答一些专业问题,同时对于一些复杂或有歧义的问题可能产生幻觉,给出错误回答。
2、同时现有给llm注入领域知识的普遍做法是进行微调,使用预训练的llm作为初始模型,在垂直领域的小规模数据上进行进一步训练,以提高模型在该领域的表现,但是微调训练需要耗费较大的计算资源,成本较高。
技术实现思路
1、鉴于上述问题,本技术提供了基于rasa的自定义nlu模型和llm结合的机器人问答方法,解决现有在机器人对话中,大语言模型llm无法回答一些专业问题,同时对一些复杂或有歧义的问题可能产生幻觉,给出错误回答的问题。
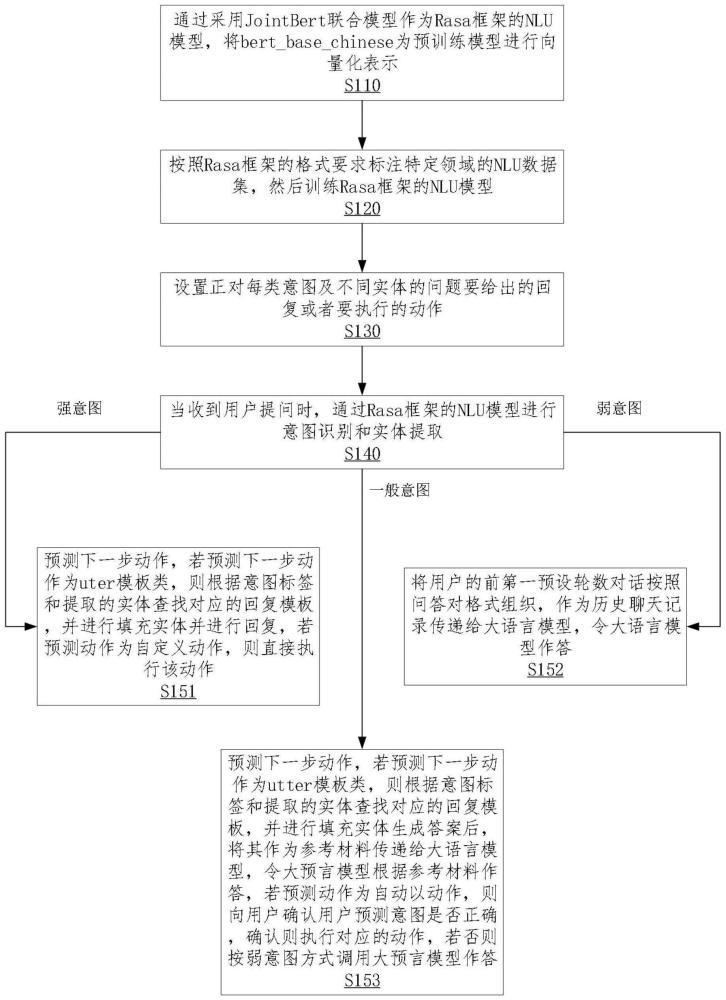
2、为实现上述目的,发明人提供了一种基于rasa的自定义nlu模型和llm结合的机器人问答方法,包括以下步骤:
3、通过采用jointbert联合模型作为rasa框架的nlu模型,将bert_base_chinese为预训练模型进行向量化表示;
4、按照rasa框架的格式要求标注特定领域的nlu数据集,然后训练rasa框架的nlu模型,所述nlu数据集包括问题文本、意图标签及实体标签;
5、设置正对每类意图及不同实体的问题要给出的回复或者要执行的动作;
6、当收到用户提问时,通过rasa框架的nlu模型进行意图识别和实体提取;
7、当意图识别为强意图时,若预测下一步动作为uter模板类,则根据意图标签和提取的实体查找对应的回复模板,并进行填充实体并进行回复,若预测动作为自定义动作,则直接执行该动作;
8、当意图识别为弱意图时,将用户的前第一预设轮数对话按照问答对格式组织,作为历史聊天记录传递给大语言模型,令大语言模型作答;
9、当意图识别为一般意图时,若预测下一步动作为utter模板类,则根据意图标签和提取的实体查找对应的回复模板,并进行填充实体生成答案后,将其作为参考材料传递给大语言模型,令大预言模型根据参考材料作答,若预测动作为自动以动作,则向用户确认用户预测意图是否正确,确认则执行对应的动作,若否则按弱意图方式调用大预言模型作答。
10、在一些实施例中,所述意图识别包括以下步骤:
11、将输入的问题文本序列x=(x1,…,xt)经过预训练模型后得到输出结果h=(h1,…,ht),x1为添加的分类任务标记[cls],xt为添加的结束标记[sep],x1及xt的中间为文字,h1对应为x1的向量化表示;
12、将输出结果h输入softmax层进行分类得到意图预测yi=softmax(wih1+bi),i为意图标签,w为权重,b为偏置;
13、将yi大于0.9的分为强意图,将yi介于0.5至0.9的分为一般意图,将yi小于0.5的分为弱意图。
14、在一些实施例中,所述实体提取具体包括以下步骤:
15、将问题文本序列x=(x1,…,xt)中的文字序列的向量化表示输入softmax层,预测每个文字的实体标签s为实体标签,n表示问题文本的长度,n为字的序号。
16、在一些实施例中,所述训练rasa框架的nlu模型具体包括以下步骤:
17、选择jointbert模型训练rasanlu。
18、在一些实施例中,还包括以下步骤:
19、若同一用户前第二预设轮数对话中已存在与当前问题相同意图且以调用过对应模板回复,则对当前问题不再进行模板回复,将模板答案作为参考材料发送至大语言模型作答。
20、还提供了另一个技术方案,一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器运行时执行以下步骤:
21、通过采用jointbert联合模型作为rasa框架的nlu模型,将bert_base_chinese为预训练模型进行向量化表示;
22、按照rasa框架的格式要求标注特定领域的nlu数据集,然后训练rasa框架的nlu模型,所述nlu数据集包括问题文本、意图标签及实体标签;
23、设置正对每类意图及不同实体的问题要给出的回复或者要执行的动作;
24、当收到用户提问时,通过rasa框架的nlu模型进行意图识别和实体提取;
25、当意图识别为强意图时,若预测下一步动作为uter模板类,则根据意图标签和提取的实体查找对应的回复模板,并进行填充实体并进行回复,若预测动作为自定义动作,则直接执行该动作;
26、当意图识别为弱意图时,将用户的前第一预设轮数对话按照问答对格式组织,作为历史聊天记录传递给大语言模型,令大语言模型作答;
27、当意图识别为一般意图时,若预测下一步动作为utter模板类,则根据意图标签和提取的实体查找对应的回复模板,并进行填充实体生成答案后,将其作为参考材料传递给大语言模型,令大预言模型根据参考材料作答,若预测动作为自动以动作,则向用户确认用户预测意图是否正确,确认则执行对应的动作,若否则按弱意图方式调用大预言模型作答。
28、在一些实施例中,所述意图识别包括以下步骤:
29、将输入的问题文本序列x=(x1,…,xt)经过预训练模型后得到输出结果h=(h1,…,ht),x1为添加的分类任务标记[cls],xt为添加的结束标记[sep],x1及xt的中间为文字,h1对应为x1的向量化表示;
30、将输出结果h输入softmax层进行分类得到意图预测yi=softmax(wih1+bi),i为意图标签,w为权重,b为偏置;
31、将yi大于0.9的分为强意图,将yi介于0.5至0.9的分为一般意图,将yi小于0.5的分为弱意图。
32、在一些实施例中,所述实体提取具体包括以下步骤:
33、将问题文本序列x=(x1,…,xt)中的文字序列的向量化表示输入softmax层,预测每个文字的实体标签s为实体标签,n表示问题文本的长度,n为字的序号。
34、在一些实施例中,所述训练rasa框架的nlu模型具体包括以下步骤:
35、选择jointbert模型训练rasanlu。
36、在一些实施例中,还包括以下步骤:
37、若同一用户前第二预设轮数对话中已存在与当前问题相同意图且以调用过对应模板回复,则对当前问题不再进行模板回复,将模板答案作为参考材料发送至大语言模型作答。
38、区别于现有技术,上述技术方案,基于rasa框架自定义nlu模型同时进行意图识别和实体抽取,并按照rasa的格式设置问题样本和模板回答,将其作为领域知识库,根据问题理解的置信度区分调用模板直接回复还是调用大语言模型生成回复,以提高机器人回答的准确性和泛化能力。
39、上述
技术实现要素:
相关记载仅是本技术技术方案的概述,为了让本领域普通技术人员能够更清楚地了解本技术的技术方案,进而可以依据说明书的文字及附图记载的内容予以实施,并且为了让本技术的上述目的及其它目的、特征和优点能够更易于理解,以下结合本技术的具体实施方式及附图进行说明。
- 还没有人留言评论。精彩留言会获得点赞!