用于低代码平台的缓存数据处理方法与流程
本发明涉及数据处理,具体涉及用于低代码平台的缓存数据处理方法。
背景技术:
1、在低代码平台中,缓存数据处理方法有助于提高应用程序的性能和响应速度,为了避免重复查询数据库,往往将查询结果缓存在内存中,但是内存有限,因此现有方法往往根据查询结果的出现频率来对数据进行排序,频率越大的数据在内存中的位置越靠前,从而在下一次查询过程中方便从内存的缓存数据中进行调用。
2、然而调用频率较大的数据不一定被调用的概率越大,将该数据置于缓存数据最前面的位置,会导致查询过程相应较慢,进而导致应用程序相应速度较慢;因此需要通过查询结果及缓存数据对下一次查询过程可能调用的查询结果进行预测,进而实现对于缓存数据的自适应排序,从而提高响应速度。
技术实现思路
1、本发明提供用于低代码平台的缓存数据处理方法,以解决现有的缓存数据与查询过程不能够自适应调整而使得响应速度较慢的问题,所采用的技术方案具体如下:
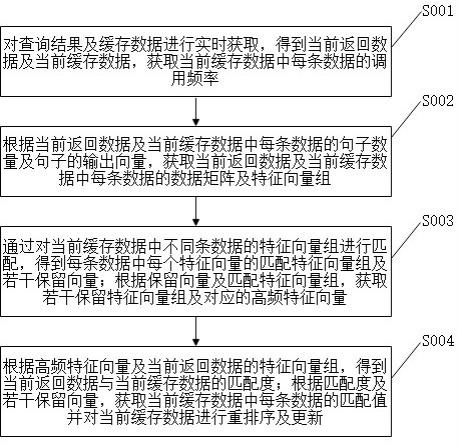
2、本发明一个实施例提供了用于低代码平台的缓存数据处理方法,该方法包括以下步骤:
3、对查询结果及缓存数据进行实时获取,得到当前返回数据及当前缓存数据,获取当前缓存数据中每条数据的调用频率;
4、根据当前返回数据及当前缓存数据中每条数据的句子数量及句子的输出向量,获取当前返回数据及当前缓存数据中每条数据的数据矩阵及特征向量组;
5、通过对当前缓存数据中不同条数据的特征向量组进行匹配,得到每条数据中每个特征向量的匹配特征向量组及若干保留向量;根据保留向量及匹配特征向量组,获取若干保留特征向量组及对应的高频特征向量;
6、根据高频特征向量及当前返回数据的特征向量组,得到当前返回数据与当前缓存数据的匹配度;根据匹配度及若干保留向量,获取当前缓存数据中每条数据的匹配值并对当前缓存数据进行重排序及更新。
7、进一步的,所述当前返回数据及当前缓存数据中每条数据的数据矩阵及特征向量组,具体的获取方法为:
8、根据当前返回数据及当前缓存数据中每条数据的句子数量及句子的输出向量,得到当前返回数据及当前缓存数据中每条数据中的若干输入句子及每个输入句子的输出向量;
9、以当前返回数据或当前缓存数据中任意一条数据为目标数据,将目标数据中所有输入句子的输出向量按照输入句子在目标数据中心的顺序,对输出向量逐行排列,一个输出向量作为矩阵的一行,得到的矩阵记为目标数据的数据矩阵;
10、对目标数据的数据矩阵进行svd分解,得到若干特征向量,将目标数据的数据矩阵得到的所有特征向量,组成目标数据的特征向量组;
11、获取当前返回数据及当前缓存数据中每条数据的数据矩阵及特征向量组。
12、进一步的,所述得到当前返回数据及当前缓存数据中每条数据中的若干输入句子及每个输入句子的输出向量,包括的具体方法为:
13、构建并训练用于将一个句子转化为一个固定长度的向量的循环神经网络,输出的向量记为句子的输出向量;
14、获取当前返回数据及当前缓存数据中每条数据的句子数量,将所有句子数量中的最小值记为标准句子数量,表示为a;
15、对于句子数量大于a的一条数据或当前返回数据,将该数据中所有句子通过训练完成的循环神经网络,输出得到每个句子的输出向量,将任意相邻两个句子的输出向量作为相邻输出向量对,获取每个相邻输出向量对中两个输出向量的余弦相似度,将所有余弦相似度中最大值对应的相邻输出向量对所对应的两个句子合并为一个句子,记为合并句子,对合并句子获取输出向量,获取合并句子与前后相邻两个句子的相邻输出向量对,并去除前后相邻两个句子与合并句子合并前两个句子对应的相邻输出向量对;
16、逐步对余弦相似度中最大值对应的相邻输出向量对所对应的两个句子进行合并,直到合并句子及未合并句子的数量等于a时,停止对该数据的句子合并;
17、对句子数量大于a的每条数据或当前返回数据的句子进行合并,使得当前返回数据及当前缓存数据中每条数据的句子数量都为a,对此时的当前返回数据及当前缓存数据中每条数据中的所有句子,记为输入句子。
18、进一步的,所述得到每条数据中每个特征向量的匹配特征向量组及若干保留向量,包括的具体方法为:
19、对当前缓存数据中任意两条数据的特征向量组进行km匹配,得到当前缓存数据中任意两条数据的特征向量之间的匹配关系;
20、以任意一条数据中任意一个特征向量为目标特征向量,将目标特征向量在其他条数据中所有匹配关系对应的特征向量,组成目标特征向量的匹配特征向量组;将匹配特征向量组中与目标特征向量的余弦相似度大于相似阈值的特征向量记为目标特征向量的匹配向量,将匹配特征向量组中匹配向量的数量与特征向量的数量的比值,记为目标特征向量的相似频率;
21、获取每条数据中每个特征向量的相似频率,将相似频率大于频率阈值的特征向量,记为保留向量,得到若干保留向量。
22、进一步的,所述得到当前缓存数据中任意两条数据的特征向量之间的匹配关系,包括的具体方法为:
23、对于当前缓存数据中任意两条数据,将其中一条数据的特征向量组中每个特征向量作为二分图左侧的节点,另一条数据的特征向量组中每个特征向量作为二分图右侧的节点,节点之间的边值通过对应特征向量的余弦相似度来表示,对二分图进行km匹配,得到该两条数据中特征向量之间的匹配关系;获取当前缓存数据中任意两条数据的特征向量之间的匹配关系。
24、进一步的,所述若干保留特征向量组及对应的高频特征向量,具体的获取方法为:
25、以任意一个保留向量为目标保留向量,获取目标保留向量的匹配特征向量组中保留向量的数量,将匹配特征向量组中保留向量的数量与特征向量的数量的比值记为目标保留向量的保留频率;
26、若保留频率大于保留阈值,将目标保留向量添加到匹配特征向量组中,添加后的匹配特征向量组记为一个保留特征向量组;
27、对每个保留向量的匹配特征向量组进行保留频率计算,得到若干保留特征向量组;
28、根据每个保留特征向量组中的特征向量,以及特征向量对应数据的调用频率,得到每个保留特征向量组的高频特征向量。
29、进一步的,所述得到每个保留特征向量组的高频特征向量,包括的具体方法为:
30、以任意一个保留特征向量组为目标保留特征向量组,将目标保留特征向量组中每个特征向量对应数据的调用频率作为每个特征向量的参考系数,对所有参考系数进行softmax归一化,得到的结果作为每个特征向量的参考权重;
31、对目标保留特征向量组的所有特征向量中相同位置的元素,根据特征向量的参考权重进行加权求和,对每个位置的元素都得到一个加权和值,记为每个位置的代表值,将代表值按照位置顺序排列,得到的向量记为目标保留特征向量组的高频特征向量;
32、获取每个保留特征向量组的高频特征向量。
33、进一步的,所述得到当前返回数据与当前缓存数据的匹配度,包括的具体方法为:
34、将所有高频特征向量作为二分图的左侧节点,将当前返回数据的特征向量作为二分图的右侧节点,节点之间的边值通过高频特征向量与特征向量之间的余弦相似度来表示,对二分图进行km匹配,得到若干匹配对;将匹配对中高频特征向量与特征向量之间的余弦相似度小于或等于匹配阈值的匹配对进行去除,将剩余的匹配对记为相似匹配对,将相似匹配对的数量与匹配对的数量的比值记为当前返回数据与当前缓存数据的匹配度。
35、进一步,所述获取当前缓存数据中每条数据的匹配值并对当前缓存数据进行重排序及更新,包括的具体方法为:
36、对于当前缓存数据中任意一条数据,获取该数据的保留向量的数量与特征向量的数量的比值,记为该数据的保留程度;获取当前缓存数据中每条数据的保留程度,若保留程度大于保留程度阈值,将保留程度对应的特征向量组记为高频特征向量组;若保留程度小于或等于保留程度阈值,将保留程度对应的特征向量组记为局部特征向量组;
37、若匹配度大于或等于匹配度阈值,以任意一个特征向量组为目标特征向量组,对目标特征向量组与当前返回数据的特征向量组进行km匹配,其中两侧节点为特征向量,边值为特征向量之间的余弦相似度,通过对二分图进行km匹配,得到若干匹配向量对;将存在保留向量的匹配向量对记为保留向量对,将保留向量对的数量作为目标特征向量组的匹配值,获取每个特征向量组的匹配值;按照匹配值从大到小的顺序对高频特征向量组对应的数据进行排序,完成后再按照匹配值从大到小的顺序,对局部特征向量组对应的数据进行排序,完成当前缓存数据的重排序;
38、若匹配度小于匹配度阈值,对于任意一个特征向量组,通过与当前返回数据的特征向量组进行km匹配后,得到若干匹配向量对,将不存在保留向量的匹配向量对记为局部向量对,将局部向量对的数量作为特征向量组的匹配值,获取每个特征向量组的匹配值;按照匹配值从大到小的顺序对局部特征向量组对应的数据进行排序,完成后再按照匹配值从大到小的顺序,对高频特征向量组对应的数据进行排序,完成当前缓存数据的重排序;
39、根据当前缓存数据中每条数据的特征向量组的匹配值,以及当前缓存数据,对重排序后的当前缓存数据进行更新。
40、进一步的,所述对重排序后的当前缓存数据进行更新,包括的具体方法为:
41、若当前缓存数据中所有条数据的匹配值的最大值,与当前返回数据的特征向量的数量相同,将匹配值最大值对应的数据的调用次数加1,对当前缓存数据中所有条数据的调用频率进行更新,完成当前缓存数据的更新;
42、若当前缓存数据中所有条数据的匹配值的最大值,不等于当前返回数据的特征向量的数量,将当前返回数据添加到当前缓存数据中,并排列在最前面的第一个位置,将重排序后的当前缓存数据中最后一个位置的一条数据踢出内存,对添加及踢出后的当前缓存数据重新获取每条数据的调用频率,完成当前缓存数据的更新。
43、本发明的有益效果是:本发明通过对当前返回数据及当前缓存数据中每条数据进行句子划分及合并,保证得到的数据矩阵大小一致,进而有助于后续特征向量的匹配量化及高频信息的获取;通过对不同条数据的特征向量进行匹配,结合匹配关系中特征向量之间的相似度得到保留向量及保留特征向量组,通过保留特征向量组反映高频信息,进而量化得到高频特征向量,为后续当前返回数据与当前缓存数据的高频信息还是局部信息的识别匹配提供基础,保证搜索趋向判断的准确性;通过获取匹配度及每条数据的匹配值,实现对当前缓存数据的重排序及更新,实现对于搜索趋向的预测,进而提高后续查询过程应用程序的响应速度,增大低代码平台的查询效率。
- 还没有人留言评论。精彩留言会获得点赞!