一种融合关系语义信息的医疗文本实体关系联合抽取方法
本发明属于医疗自然语言处理,具体是指一种融合关系语义信息的医疗文本实体关系联合抽取方法。
背景技术:
1、当前,国内大多数医院的病历采用自然语言记录,这类非结构化的文本没办法直接被计算机使用,需要转化成计算机易于处理的结构化格式,而从非结构化文本中提取结构化的信息正是自然语言处理的研究方向之一。从病历中快速准确地提取结构化信息主要基于自然语言处理中的信息抽取技术,包括实体抽取,关系抽取,事件抽取。其中实体和关系抽取是病历结构化的关键步骤。
2、实体和关系抽取是信息抽取的关键任务之一。实体关系抽取主要有两类方法,一类是采用流水线的方式,研究者将实体关系抽取当成两个级联的子任务处理,其中关系抽取依赖实体抽取。缺点是这种方法存在误差传播的问题,没有考虑两个子任务间的交互性。另一类是采用联合解码的方式,即关系和实体抽取共用一个编码器,这类方法目前已成为主流方式,例如casrel,实体和关系抽取共用一个bert编码器。
3、近几年,实体关系抽取领域实现sota效果的方法大多基于token-pair的方式,例如tplinker,枚举句子中任意两个token作为可能的实体或者实体对的表示。这种方式优点非常明显,解决了误差累积的问题,实现了实体和关系同时抽取。
4、最近,chatgpt的大火再次将人工智能推向新的浪尖。我们不仅可以和chatgpt进行聊天,还可以在和其对话过程中辅助我们完成科研任务。在实体关系抽取领域,一方面,我们可以使用chatgpt进行数据增强,通过和chatgpt进行聊天的方式让其帮助我们生成新样本。另一方面,我们也可以通过chatgpt对抽取的关系三元组进行逻辑判断。
5、最后,目前的实体关系抽取模型仅仅把关系当做成一个数字编号,而没有具体的语义信息。实际上这种做法是有欠妥的。例如在给你定句子和关系名称的条件下,我们可以很快地捕获到句子哪些词语和关系名称存在关联。这个例子充分说明关系的语义信息对于捕获关系三元组的重要意义。另外,很多模型训练数据集本身存在类别不平衡的问题。因此,在这样的背景下,我们需要提出一种模型将关系的语义信息考虑进去,同时解决数据集本身类别不平衡的问题。
技术实现思路
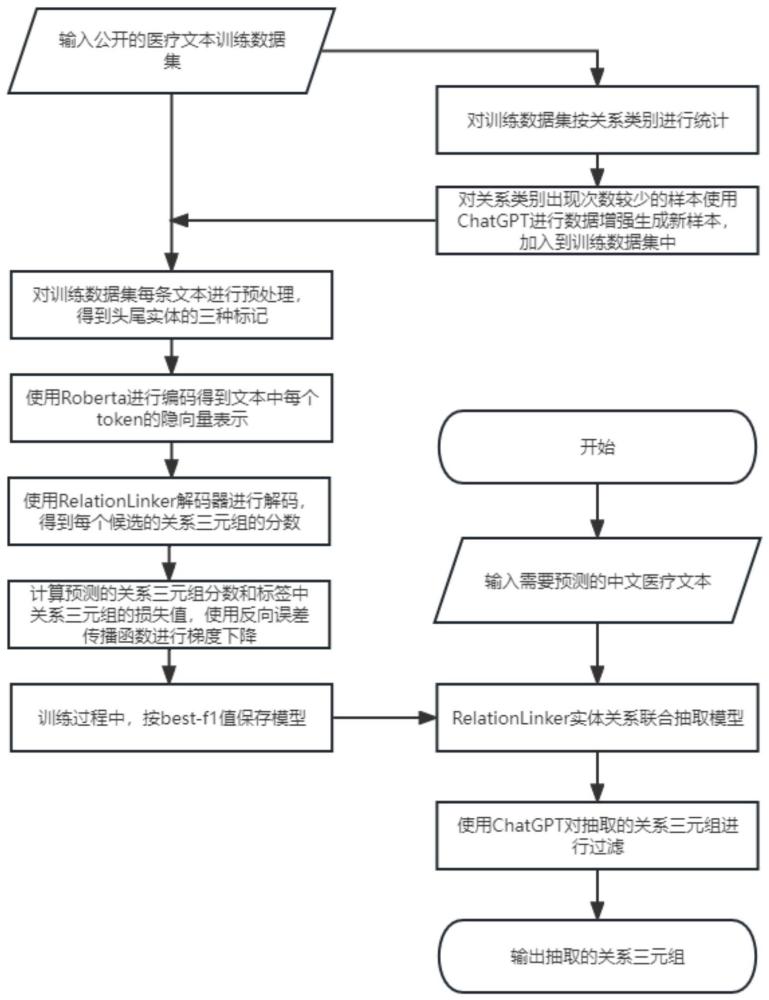
1、为了解决背景技术中的问题,本发明公开了一种融合关系语义信息的医疗文本实体关系联合抽取方法。本发明的目的有三点:1)将关系的语义信息融入候选的关系三元组中,解决三元组信息不完整的问题。2)使用chatgpt帮助我们生成新样本解决数据集本身类别不平衡的问题。3)使用chatgpt对抽取的关系三元组进行过滤操作提升了模型的精准率。
2、本发明采用的技术方案包括以下步骤:
3、(1)对公开的医疗文本数据集中的每条样本进行预处理生成原始的模型训练数据集;
4、(2)使用chatgpt对步骤1)构建的模型训练数据集进行数据增强以解决其存在类别不平衡的问题,构建新的模型训练数据集;
5、(3)基于预训练语言模型bert构建relationlinker神经网络模型结构;
6、(4)基于步骤2)的模型数据集训练步骤3)构建的relationlinker神经网络模型。
7、(5)使用步骤4)训练好的relationlinker神经网络模型对医学文本进行实体关系联合抽取;
8、(6)使用chatgpt对步骤5)抽取的关系三元组进行过滤得到最终结果集。
9、所述步骤1)具体为:
10、1.1)根据公开的医疗文本数据集中的每条文本t和文本对应的三元组列表定义三种标记矩阵:实体的首尾标记eh-et,主语和宾语组合的首首标记sh-oh和尾尾标记st-ot;
11、其中,三元组列表包括subject,predicate,object;
12、其中,实体的首尾标记矩阵用于抽取主语和宾语;主语和宾语的首首标记、尾尾标记矩阵用于进行主客体对齐。
13、1.2)使用tokenizer对文本t(包括cls和sep符号)进行分词生成token序列:t1,t2,…,tn;
14、1.3)对文本t对应的每个三元组进行处理:
15、a)获取实体的首尾标记:
16、抽取三元组中的主语和宾语作为实体,将实体在token序列中的起始和终止位置形成的二元组(entity-head,entity-tail)作为实体首尾标记矩阵的坐标,并设置其上的值为1。
17、b)获取实体对的首首标记和尾尾标记:
18、实体对为三元组中已知关系的主语和宾语组合;
19、将主语和宾语在token序列中的起始位置形成的二元组(subject-head,object-head)作为实体对首首标记矩阵的坐标,并设置其上的值为1;将主语和宾语在token序列中的终止位置形成的二元组(subject-tail,object-tail)作为实体对尾尾标记矩阵的坐标,并设置其上的值为1;
20、其中,标记矩阵上其他坐标的值为0。
21、所述步骤2)具体为:
22、2.1)对公开的医疗文本数据集中的样本进行关系的类别统计;
23、2.2)对于类别出现次数小于阈值的样本使用chatgpt进行数据增强,在不改变句意和关键词的条件下进行句子改写生成新样本。
24、2.3)对新样本进行预处理后加入步骤(1)的数据集中构建新的模型训练数据集;
25、所述新样本的预处理为:去除语义不顺、句义扭曲的句子后,采用步骤1的预处理方法对新样本进行处理。
26、所述步骤3)的relationlinker神经网络模型结构包括bert编码层、关系嵌入表示模块、主客体抽取模块和主客体对齐模块;
27、3.1)编码层
28、采用roberta进行编码,其中编码层的输入为:[cls]文本[sep],输出为:(h1,h2,…,hn);
29、其中,hi为第i个token经过roberta编码后的隐向量表示,hi∈(h1,h2,…,hn);
30、3.2)关系嵌入模块
31、在主客体对齐过程中,对数据集遵循的关系范式中任意一种关系ri,使用嵌入向量进行表示,嵌入向量使用函数torch.nn.embedding随机生成;
32、其中,ri∈r,r={r1,r2,…,rm},1≤i≤m,m为关系范式中的关系个数;
33、在主客体生成过程中,将抽取主体和抽取客体视作两种特殊的关系r1和r2,对其中任意一种特殊关系rk使用嵌入向量进行表示,嵌入向量使用函数torch.nn.embedding随机生成;
34、其中,rk∈r,r={r1,r2},1≤k≤2;
35、其中,抽取主体表示抽取句子中的主语,抽取客体表示抽取句子中的宾语;特殊的关系r和r2用于表示抽取主体或客体的行为;
36、3.3)主客体生成模块
37、通过关系嵌入模块获得r,进一步枚举每一种关系rk;
38、基于编码层输出的隐向量序列(h1,h2,…,hn)枚举所有可能成为实体的二元组(hi,hj);再通过全连接层分别学习到成为实体的首尾表示(qi,tj);使用learnedpositional embedding得到相对位置向量p,即候选实体的片段长度;
39、将候选实体的首字符向量qi,关系向量rk,尾字符向量tj,相对位置向量p按顺序拼接得到一个长向量(qi,rk,tj,p),将长向量通过一个线性层学习到对应的四元组表示s(通过线性层降维后生成一个向量);
40、将四元组表示s和关系rk的嵌入向量进行点乘操作得到的分数作为当前候选实体四元组的最终打分;
41、3.4)主客体对齐模块
42、将实体对的首首标记和尾尾标记分开处理,实体对二元组包括(subject-head,object-head)和(subject-tail,object-tail);
43、通过关系嵌入模块获取关系范式集合r={r1,r2,…,rm},m为关系范式中关系个数;进一步枚举关系范式中每一种关系rk,1≤k≤m;
44、基于编码层输出的隐向量序列(h1,h2,…,hn)枚举所有可能成为实体对的二元组(hi,hj),通过两个线性层学习其主语和宾语表示,从而生成主语向量si、宾语向量oj;基于主语向量si、关系嵌入向量rk、宾语向量oj枚举一个潜在的关系三元组候选,将主语向量si、关系嵌入向量rk、宾语向量oj按顺序拼接成一个长向量(si,rk,oj);再将长向量通过一个线性层学习到其对应的三元组表示t;
45、将三元组表示t和关系rk的嵌入向量进行点乘操作得到的分数作为当前候选关系三元组的最终打分。
46、所述步骤4)具体为:
47、采用步骤2)的模型训练数据集对步骤3)构建的relationlinker神经网络模型进行训练,选取稀疏多标签交叉熵函数作为最终损失函数,采用误差反向传播对relationlinker神经网络模型的权值和偏置进行调整;根据训练过程中模型多标签分类的f1值选取神经网络模型参数,将多标签分类f1值最大时对应的一组参数作为relationlinker神经网络模型参数。
48、所述步骤5)具体为:
49、5.1)对于给定的文本t,先在文本首部和尾部分别添加特殊字符[cls]和[seq],之后输入到bert编码层,bert编码层输出(h1,h2,…,hn);
50、5.2)将输出的隐向量序列(h1,h2,…,hn)输入主客体生成模块,主客体生成模块输出两个矩阵,主语和宾语的首尾矩阵:sh-st,oh-ot;
51、矩阵每个坐标上的值代表对应的候选实体二元组的最终分数,当分数超过设定阈值时表示对应的候选实体二元组成立,并保留;否则认为不成立,并筛除;最终得到主语和宾语集合;
52、其中,设定阈值默认为0;
53、5.3)将输出的隐向量序列(h1,h2,…,hn)输入主客体对齐模块,主客体对齐模块输出两类主客体对齐矩阵,包括主语和宾语组合的首首矩阵sh-oh和尾尾矩阵st-ot,每类矩阵有|r|个;
54、矩阵每个坐标上的值代表对应的候选关系三元组的最终分数;
55、其中,主客体对齐矩阵存在两个阈值α和β,α<β;α用于判断候选关系三元组是否成立,β用于判断关系三元组成立的可信度是否较高;
56、5.4)使用双重循环枚举法从步骤5.2)输出的主语和宾语集合中枚举所有可能的主语和宾语组合,对每个可能的主语和宾语组合进行解码处理,得到文本对应的关系三元组集合。
57、所述步骤5.4)的解码过程具体为:
58、5.4.1)对于每个可能的主语和宾语组合,其主语坐标表示为(subject-head,subject-tail),宾语坐标表示为(object-head,object-tail),主语和宾语组合的坐标表示为(subject-head,object-head)、(subject-tail,object-tail);
59、5.4.2)步骤5.3)输出每种关系的两类主客体对齐矩阵,对于每个关系对应的主客体首首对齐矩阵和尾尾对齐矩阵:
60、a)若坐标(subject-head,object-head)在主客体首首对齐矩阵上的值超过指定阈值α并且坐标(subject-tail,object-tail)在主客体尾尾对齐矩阵上的值也超过指定阈值α,基于主语和宾语组合的坐标从文本和关系范式中抽取主语名称、关系名称和宾语名称,将抽取的关系三元组加入关系三元组集合s1中;
61、b)同理,当超过阈值β时,参照a)步骤得到另一个可信度较高的关系三元组集合s2。
62、所述步骤6)具体为:
63、令s3=s1-s2,得到可信度较低的关系三元组集合s3,其中s2是s1的子集;
64、对集合s3中每条抽取的关系三元组,将关系三元组按主谓宾顺序组成语句输入chatgpt,通过chatgpt判断句子是否成立,将成立的关系三元组加入集合s4中;
65、输出s2和s4的并集作为最终结果集。
66、本发明的有益效果:
67、1)本发明提出的融合关系语义信息的神经网络结构模型relationlinker,将关系的语义信息融入到候选的关系三元组中,使得候选的关系三元组有了较为完整的信息。在保证关系三元组提取效果的同时提升了模型的召回率。
68、2)本发明基于token-pair的方式定义了3种标记:实体的首尾标记,实体对的首首标记,尾尾标记,解决了实体关系联合抽取中的实体嵌套,spo,epo问题。
69、3)针对原始数据集本身类别不平衡的问题,使用chatgpt进行数据增强。
70、4)使用chatgpt对可信度较低的关系三元组进行过滤,进一步提升了模型的精准率。
- 还没有人留言评论。精彩留言会获得点赞!