基于自适应蚁群整定长短期记忆网络的分布式光伏功率预测方法与流程
【】本发明涉及光伏功率预测领域,尤其涉及一种基于自适应蚁群整定长短期记忆网络的分布式光伏功率预测方法。
背景技术
0、
背景技术:
1、随着“碳达峰、碳中和”目标的提出,大力发展新能源已经成为电力系统的重要发展方向之一。光伏发电作为一种环保、可持续的能源形式,正受到日益增长的关注和推广。然而,光伏发电系统的特殊性质带来了一系列挑战,其中最重要的之一就是光伏功率预测的问题。由于光伏发电受到日照强度、天气变化、季节差异、地理位置等多种因素的影响,其功率输出呈现高度非线性和时变性。因此,准确预测光伏功率成为实现智能电网、优化能源调度以及市场交易的关键。
2、目前,传统的功率预测方法主要基于统计学或者数学模型,例如:中国专利cn110598896a、cn112085260a等均提出了光伏功率预测方法,能够依据相似日的基本原理,选取待预测日的相似日进行待预测日各基值点光伏发电功率预测。但是由于光伏发电系统的复杂性和非线性,这些方法的准确性和稳定性较差,无法满足实际应用的需求。
3、为了提高预测精度,深度学习技术逐渐引入到光伏功率预测中。其中,长短期记忆网络(lstm)作为一种优秀的循环神经网络(rnn)的变体,能够有效地捕捉时间序列数据的长期依赖关系,为光伏功率预测提供了新的思路。中国专利cn116029442a提出了一种基于lstm组合预测框架的光伏功率预测方法、系统、设备及存储介质,将预处理后的气象数据输入优化lstms预测模型,得到该模型下的光伏功率预测值,通过arima与svr组合的方法,通过优化算法对集成lstms模型进行优化,进一步提升了预测的精确性。然而,传统的lstm网络需要通过离线训练确定其参数,导致网络的参数难以适应光伏系统的实时变化,预测结果缺乏稳定性。
4、因此,有必要充分考虑分布式光伏功率预测过程中的复杂性和非线性特征,设计合理的分布式光伏功率预测方法,利用人工智能算法优化分布式光伏功率预测模型,提升预测模型的泛化能力,增强预测模型对不同环境条件下预测准确性和稳定性,提高预测方法的有效性和普适性,提高光伏功率预测模型的性能和效率,为光伏发电系统的智能管理和优化运行提供有力支持。
技术实现思路
0、
技术实现要素:
1、本发明的目的就是解决现有技术中的问题,提供一种基于自适应蚁群整定长短期记忆网络的分布式光伏功率预测方法,能够增强预测模型对不同环境条件下预测准确性和稳定性,提高预测方法的有效性和普适性,从而提高光伏功率预测模型的性能和效率,为光伏发电系统的智能管理和优化运行提供有力支持。
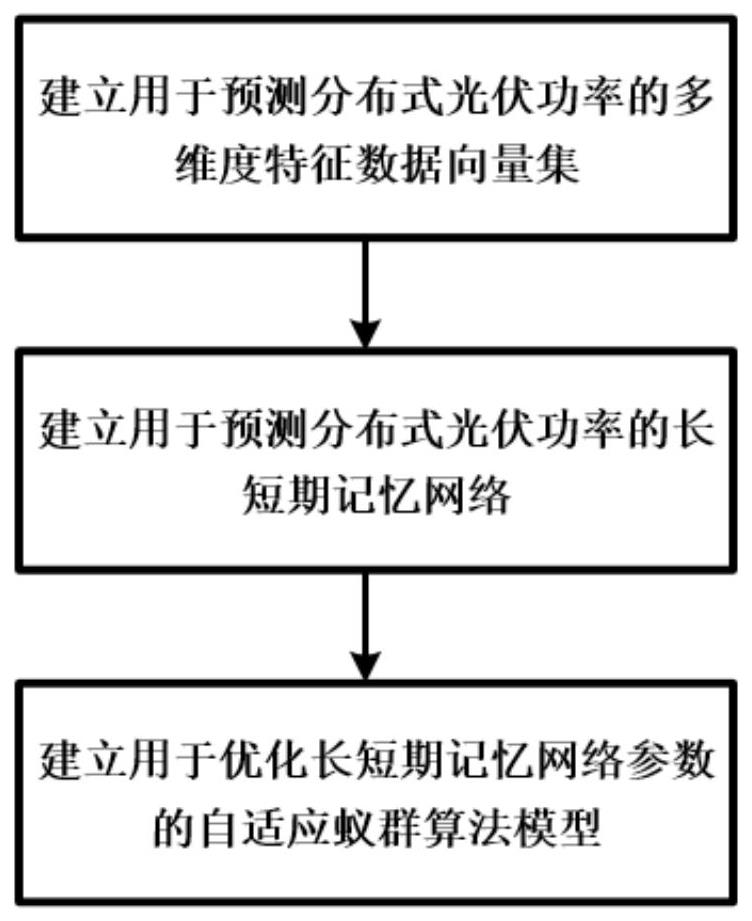
2、为实现上述目的,本发明提出一种基于自适应蚁群整定长短期记忆网络的分布式光伏功率预测方法,包括以下步骤:
3、步骤1:建立用于预测分布式光伏功率的多维度特征数据向量集;
4、步骤2:针对步骤1建立的用于预测分布式光伏功率的多维度特征数据向量集,建立用于预测分布式光伏功率的长短期记忆网络;
5、步骤3:针对步骤2建立的长短期记忆网络,建立用于优化长短期记忆网络参数的自适应蚁群算法模型。
6、作为优选,所述步骤1中用于预测分布式光伏功率的多维度特征数据向量集中的特征数据包括辐照度数据、气温数据、湿度数据、气压数据、分布式光伏发电功率数据以及负荷用电数据。
7、作为优选,将分布式光伏发电功率数据作为输出向量,将辐照度数据、气温数据、湿度数据、气压数据以及负荷用电数据作为输入向量;基于lightgbm特征选择算法将辐照度数据、气温数据、湿度数据、气压数据、分布式光伏发电功率数据以及负荷用电数据等输入向量的特征值转化为直方图,随后对多维度特征数据向量集的各维度特征贡献度进行排序,剔除贡献度小于5%的特征,形成优化后的分布式光伏功率预测多维度特征数据向量集。
8、作为优选,所述步骤2中长短期记忆网络包括有若干输入变量、若干lstm单元,所述输入变量顺序经过长短期记忆网络中的隐含层中的各lstm单元进行训练。
9、作为优选,所述lstm单元中引入可保留输入变量的关键时序关联信息的更新门函数,lstm网络通过更新门函数可选择性更新每个时刻的状态;lstm单元中引入可去除输入变量的非必要时序关联信息的重置门函数,lstm网络通过重置门函数可选择性丢弃不必要信息。
10、作为优选,所述步骤2包括:
11、s201:将步骤1获得的优化后的分布式光伏功率预测多维度特征数据向量集作为分布式光伏功率预测模型的输入变量x;
12、s202:基于步骤s201所述的输入变量x,构建分布式光伏功率lstm预测模型;分布式光伏功率lstm预测模型包括输入层、隐含层和输出层;输入层接收优化后的分布式光伏功率预测多维度特征数据作为输入,隐含层包含若干个用于学习时间序列的长期依赖关系的lstm单元,输出层用于预测分布式光伏功率;每个lstm单元包括t时刻的更新门、遗忘门和输出门;更新门用于记忆当前t时刻的分布式光伏功率预测多维度特征信息,遗忘门用于选择分布式光伏功率预测多维度特征中非必要的特征信息;输出门用于将当前隐含层的结果输出至下个lstm单元。
13、作为优选,所述s202中的更新门和遗忘门同时基于输入变量进行操作;更新门通过一个sigmoid激活函数来决定每个输入特征的重要性,以控制合适的信息输入到记忆单元中;更新门根据当前时刻的输入数据和上一个时刻的隐藏状态,选择性地将相关的信息传递给记忆单元,以更新当前的状态;遗忘门也通过一个sigmoid激活函数来决定每个记忆单元中的信息是否需要被保留;遗忘门通过过去的状态和当前输入,通过不断迭代决定应该被遗忘的信息;
14、更新门的输出lt可以表示为:
15、lt=ftlt-1+jtct
16、jt=g(wjxt+vjht-1+bj)
17、ct=tanh(wixt+viht-1+bi)
18、式中,lt为更新门的输出,ft为遗忘门的输出;xt为t时刻的输入向量;ht-1为t-1时刻隐含层的输出量,即输出门的输出结果;g为sigmoid激活函数;jt为sigmoid激活函数的输出;wj、vj为从xt与ht-1映射到更新门激活函数输出jt的权重矩阵,矩阵中元素分别为初始值随机的实数。bj为更新门激活函数输出的偏置向量,向量元素为初始值随机的实数;ct为tanh函数的输出;wi、vi为从xt与ht-1映射到更新门tanh函数输出ct的权重矩阵,矩阵中元素分别为初始值随机的实数。bi为更新门tanh函数输出的偏置向量,向量元素为初始值随机的实数;
19、遗忘门的输出ft由如下公式确定:
20、ft=g(wfxt+vfht-1+bf)
21、式中,wf、vf为从xt与ht-1映射到遗忘门激活函数输出ft的权重矩阵,矩阵中元素分别为初始值随机的实数。bf为遗忘门激活函数输出的偏置向量,向量元素为初始值随机的实数;
22、输出门的输出ot由如下公式确定:
23、ot=g(woxt+voht-1+bo)
24、式中,wo、vo为从xt与ht-1映射到遗忘门激活函数输出ot的权重矩阵,矩阵中元素分别为初始值随机的实数。bo为从xt与ht-1映射到遗忘门激活函数输出偏置向量,向量元素为初始值随机的实数;
25、输出门基于更新门的输出和遗忘门的输出,获得当前隐含层的输出。t时刻的隐含层输出ht可以表示为:
26、ht=ot·tanhlt
27、经过多层lstm单元的迭代,最终形成基于长短期记忆网络的分布式光伏功率预测模型的输出。
28、作为优选,所述步骤3包括:
29、s301:初始化自适应蚁群算法参数;
30、s302:计算自适应蚁群算法食物位置信息素含量函数;
31、s303:采用引入自适应系数的自适应蚁群算法邻域搜索方程进行邻域搜索寻找新的食物位置;
32、s304:设计概率选择公式决定蚂蚁是否向食物位置信息素含量函数值更高的位置搜索食物;
33、s305:判断搜索次数是否达到最大迭代次数;若是,输出自适应蚁群算法当前轮次最优解;若否,则进行下一轮次的食物位置搜索,返回s302。
34、作为优选,所述步骤3包括:
35、s301:初始化自适应蚁群算法参数;所述自适应蚁群算法包括自适应蚁群算法中的蚂蚁数量n,最大搜索食物次数为imax以及食物位置xm;其中,食物位置xm中存储的多维度信息包含长短期记忆网络模型中wj,vj,bj,wf,vf,bf,wo,vo,bo的待优化参数;
36、s302:计算自适应蚁群算法食物位置信息素含量函数f,用于量化当前长短期记忆网络待优化参数的优劣;所述自适应蚁群算法食物位置信息素含量函数f可以表示为:
37、
38、式中,em为基于长短期记忆网络的分布式光伏功率预测模型的预测平均误差;er为基于长短期记忆网络的分布式光伏功率预测模型的预测均方根误差;np为分布式光伏功率预测时间点的总数;分别为第i个点的真实值和预测值;
39、s303:采用引入自适应系数的自适应蚁群算法邻域搜索方程进行邻域搜索,具体为:
40、
41、式中,为邻域食物位置;u(t)为自适应蚁群算法的自适应函数;k与j为不同于i的食物位置;为自适应系数;vig为当前循环中的最优解;
42、s304:建立轮盘概率公式对蚂蚁搜索得到的食物位置进行选择,具体可以表示为:
43、
44、式中,fi为蚂蚁i的食物位置选择概率;fi为蚂蚁i的食物位置信息素含量函数值;
45、s305:判断自适应蚁群算法计算次数是否达到最大探索次数imax;若达到最大探索次数,则自适应蚁群算法当前计算得到的lstm参数为最优参数。若尚未达到最大探索次数,则继续利用自适应蚁群算法进行lstm参数寻优,返回步骤302。
46、作为优选,所述s303中采用如下方法设计自适应函数:在循环开始时,自适应函数的取值应为小于1且大于0.5的实数;随着循环次数增加,自适应函数的取值应单调递减,直至趋近于0。
47、本发明的有益效果:
48、1.提出了考虑多维度预测影响因素时序关联性及泛化性的分布式光伏功率智能预测方法。通过充分利用长短期记忆网络中的更新门,挖掘光伏输出功率与自然环境信息之间的潜在时序关联关系。同时,利用长短期记忆网络中的遗忘门,剔除对光伏输出功率与自然环境信息的非普适性影响,从而显著提升了预测模型的泛化能力,增强了预测模型对不同环境条件下的预测准确性和稳定性,从而提高了预测方法的有效性和普适性。
49、2.设计了一种基于自适应蚁群算法的分布式光伏功率预测网络参数优化方法。自适应蚁群算法通过对预测网络的参数进行优化,能够显著提升分布式光伏功率预测的准确性。该优化方法能够自动调整预测网络的参数,以适应分布式光伏功率预测多维度特征之间的复杂关联关系,从而更好地捕捉光伏发电系统的特性。通过自适应蚁群算法的参数优化,可以进一步提高光伏功率预测模型的性能和效率,为光伏发电系统的智能管理和优化运行提供有力支持。
50、本发明的特征及优点将通过实施例结合附图进行详细说明。
- 还没有人留言评论。精彩留言会获得点赞!