一种基于机器学习的秸秆综合利用分类方法、系统和介质
本发明涉及秸秆综合利用,尤其涉及一种秸秆综合利用分类方法、系统和介质。
背景技术:
1、中国秸秆资源丰富,每年农作物收获后会产生大量的秸秆,但秸秆的处理一直是一个难题。传统的焚烧和直接还田等方法实施起来仍然存在环境污染问题,因此如何高效利用秸秆逐渐成为关注的焦点。
2、秸秆综合利用是将秸秆转化为可再生能源、生物基产品和其他高附加值产品的过程。这个过程主要分为能源化、肥料化、饲料化、基料化和材料化五大类。依据研究现状来看,目前并没有一种全面且系统的秸秆综合分类方法,部分分类基本依靠特性中的1-2种特性的含量大小进行简单的分类,但这种分类方法存在不同程度的主观性和局限性。因此,能够对综合利用进行更全面、系统地、科学地分类,选择最适合的处理方式,对于农业资源利用效率和经济效益提高是具有重要意义。
3、由于不同种类的秸秆存在着不同的理化特性,因此如何选择合适的特性作为综合利用方法标准是尤为重要的。但由于秸秆的种类众多,其理化特性、营养成分和用途等因素之间存在着相互影响、相互制约的关系,因此不同特性之间的相关性过于复杂,不利于展示和分析。而机器学习的出现可以弥补这一问题,是因为机器学习是一种基于数据驱动的技术,通过对数据的学习和分析,可以让机器根据数据自身的特征和规律来不断优化自身。采用机器学习方法,不仅可以克服传统分类方法的主观性和局限性,还可以挖掘秸秆不同特性之间的相关性和规律,提高分类的准确性和可比性。
4、根据数据库中的秸秆不同特性数据的分布情况,考虑了一种使用基于非参数pca和spearman相关系数构建的特性权值函数并结合机器学习的各类产量预测模型用来降维与优化特征。而目前,数据库中数据量太多,如果每一条数据邀请领域专家依据特性含量进行分类化评判还是具有主观性和局限性。但如果使用单一的的无监督算法进行分类,所得到的结果差异较大,很难得到一个稳定的模型。
技术实现思路
1、针对目前并没有一种全面且系统的秸秆综合分类方法,而部分分类基本依靠特性中的1-2种特性的含量大小进行简单的分类,但这种分类方法存在不同程度的主观性和局限性的问题,提出了一种无监督与自监督算法结合的方法。
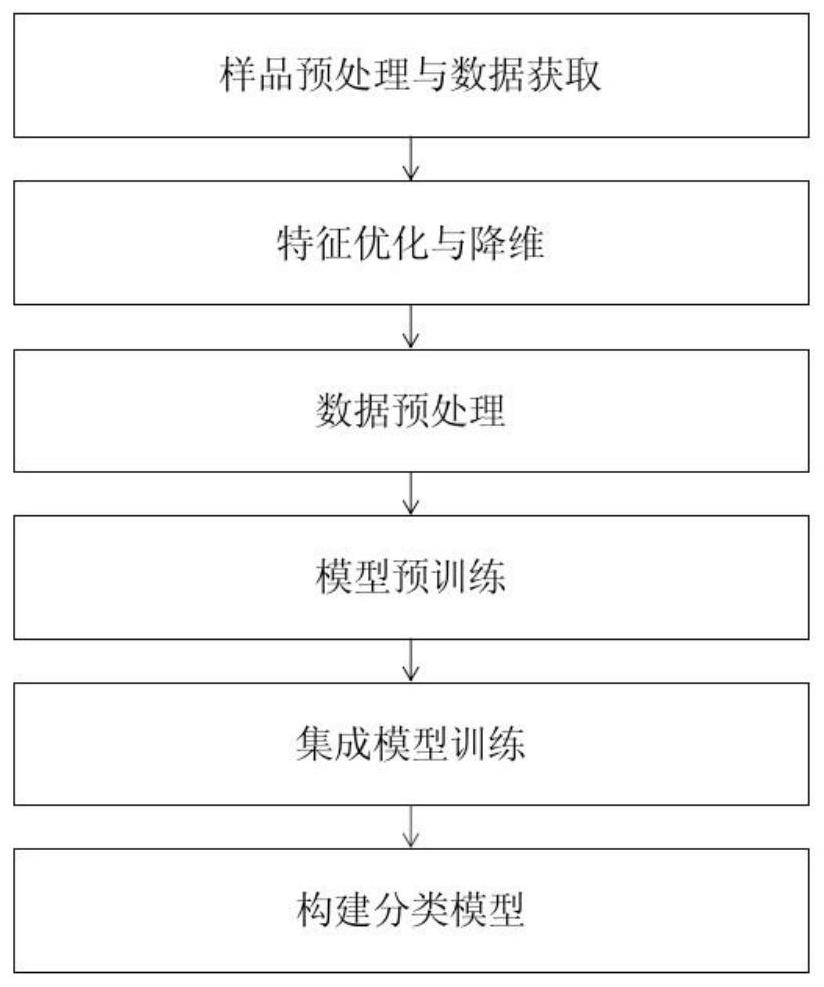
2、本发明的一种秸秆综合利用分类方法,包括以下步骤:
3、s1、通过对样品干燥、粉碎等预处理方式,使用光谱设备获得秸秆样品中性洗涤纤维等20项参数特性;
4、s2、对所得的参数特性进行特征优化与降维,使用spearman相关系数、非参数pca、预测模型等方法构建新的参数特征;
5、s3、对所述新的参数特征进行数据预处理,获得新的参数特征归一化后的数据;
6、s4:对所得的数据集,选取其中20%的数据进行预训练,根据不同分类结果进行对比,并确定预训练结果;
7、s5:将剩余未分类的数据集送入集成模型中,根据预训练结果结合集成模型进行分类训练;
8、s6:通过构建分类模型,得到最终分类结果。
9、在本方案的一个优选实施方式中,s1中参数特性包括:中性洗涤纤维、酸性洗涤纤维、纤维素、半纤维素、木质素、可溶性糖分、粗蛋白、磷、钾、水分、挥发分、固定碳、灰分、高位发热量、低位发热量以及碳、氢、氧、氮、硫元素含量共计20项参数特性。
10、在本方案的一个优选实施方式中,s2使用spearman相关系数结合非参数pca和预测模型两种方法构建新的参数特征,包括如下步骤:
11、s7:使用spearman相关系数法与非参数pca法对不同特征加权计算得到特定分类的得分;
12、s8:基于实验数据,训练机器学习预测模型,并将结果与步骤一得分等比缩放并相加构建新参数特征得分。
13、s7中特定分类标准为:选择木质素、挥发分、灰分、固定碳、高位发热量、低位发热量以及碳、氢、钾、硫元素含量作为燃料化分类的特性参数,选择纤维素、半纤维素、木质素、水分和氧元素含量作为生物转化分类的特性参数,选择中性洗涤纤维、酸性洗涤纤维、可溶解糖分、粗蛋白、磷和氮元素含量作为饲料化分类的特性参数;
14、s8中新参数特征为燃料乙醇、沼气/生物天然气、直燃热电联产、热解炭化、热解气化、热解油化、青贮、氨化利用共计8种分类,其中燃料乙醇、沼气/生物天然气为生物转化分类,直燃热电联产、热解炭化、热解气化、热解油化为燃料化分类,青贮、氨化为饲料化分类。
15、在本方案的一个优选实施方式中,s4具体为:不少于800条数据集中的20%的数据用于预训练,预训练步骤如下:
16、s9:s8中所述的每种分类方法标注3-5条数据用于knn算法的分类。
17、s10:将knn与k-means的结果进行比较,如果分类结果相同则赋上标签,如果分类结果不同,则将这条数据送入剩余数据集中。
18、在本方案的一个优选实施方式中,s5采取无监督与自监督算法集成方式;集成模型包含三个算法:k-means、标签传播和自监督集成算法,其中自监督集成算法使用的原始特征,即s1所述,k-means和标签传播算法使用的优化后的特征,即s8所述;所述s5中当每一轮预测结果出来,采取投票的方式确定最终结果,如果结果为平票,则此数据放置到数据集最后的位置,如果某一条数据参与过3次以上训练,则丢弃此数据;所述s5自监督集成算法采用集成线性与非线性机器学习模型,包括逻辑回归模型、极度极限梯度提升、支持向量机和线性判别分析四种模型,并对其超参数调优,其分类结果是根据每一种模型对不同分类预测结果的概率累加并求得均值的最大得到分类结果;所述标签传播与k-means,依赖预训练得到的结果进行下一步训练。
19、在本方案的一个优选实施方式中,s6具体为:将s4最后结果与s5得到的数据集使用knn算法构建最终分类模型,设置结果将欧几里得距离最近的三个分类标签输出,得到分类结果。
20、为了解决上述问题,本发明还提供了一种基于机器学习的秸秆综合利用分类系统,包括:推荐服务端和信息展示端;推荐服务端配置为:实现上述基于机器学习秸秆综合利用分类方法;信息展示端配置为:向信息推荐服务端发送信息获取请求。
21、为了解决上述问题,本发明还提供了一种计算机可读存储介质,计算机可读存储介质存储一个或多个程序,一个或多个程序当被包括多个应用程序的电子设备执行时,使得电子设备执行上述基于机器学习秸秆综合利用分类方法的计算机程序。
22、本发明公开了一种秸秆综合利用分类方法,本方法采用非参数pca、spearman相关系数、机器学习预测模型,通过挖掘秸秆的不同特性之间的相关性和规律来提高分类的准确性;相比传统的分类方法,本方法克服了主观性和局限性的问题,可以更加客观地评估秸秆的价值和利用途径;本方法可以广泛应用于秸秆的综合利用领域,为秸秆资源化提供了新的思路和方法。
23、本方法创新的提出了集成机器学习模型来提高模型精度;传统的机器学习模型往往存在着过拟合和欠拟合的问题,使得模型的预测能力受到了很大的影响,而集成机器学习模型则可以通过结合多个基本模型来提高模型的预测精度,从而提高了模型的广泛性和鲁棒性;在秸秆综合利用的领域,利用集成机器学习模型可以更好地挖掘秸秆的潜在价值和利用途径,从而促进秸秆的资源化和环境保护。
- 还没有人留言评论。精彩留言会获得点赞!