一种融合熵、方差和相关系数的权重分配特征评估与选择方法及计算机设备
本发明属于机器学习和数据挖掘,特别涉及一种融合熵、方差和相关系数的权重分配特征评估与选择方法及计算机设备。
背景技术:
1、特征选择是机器学习和数据挖掘中的一个重要任务,它旨在从原始数据中选择最相关、最有信息量的特征,以提高模型的性能和解释能力。特征选择技术在降低维度、消除冗余、提高模型训练效率和减少过拟合等方面具有重要作用。
2、现有的特征选择技术主要包括以下几个类别,即过滤式特征选择(filterfeature selection),包裹式特征选择(wrapper feature selection),嵌入式特征选择(embedded feature selection)。过滤式方法独立于具体的机器学习算法,通过对特征进行评估和排序来选择特征。常用的评估指标包括方差、互信息、相关系数等。过滤式方法的优点是计算效率高,可以快速筛选出相关性较高的特征,但无法考虑特征与分类目标的交互作用。包裹式方法将特征选择作为一个子问题嵌入到特定的机器学习算法中。它通过搜索特征子集并使用评估指标来评估子集的性能,以选择最佳的特征子集。包裹式方法可以考虑特征之间的相互作用,但计算复杂度较高。嵌入式方法将特征选择与机器学习算法的训练过程结合在一起。它通过在模型训练过程中自动选择和调整特征权重来进行特征选择。常见的嵌入式方法包括l1正则化、决策树的特征重要性等。
3、以上的特征选择技术,大多从数据的一个方面来进行考量,考虑了数据的统计特性,没有考虑到数据的信息量和相关系数。诚然,不同的数据集会表现出不一样的特点,仅从一个方面考虑有时是合理的,但如何选择正确的方面也是极为困难的,需要拥有一定的专家经验。
4、基于以上考虑,急需设计一种特征选择方法,可以综合的考虑数据的各个方面并快速的找到最适合的特征,从而达到降低维度、消除冗余、提高模型训练效率和减少过拟合的目的。
技术实现思路
1、本发明提出的结合熵、方差和相关系数的权重分配特征评估与选择方法,涉及数据的统计特性,信息特性以及相关系数特性等多个方面,同时考虑了单个特征与标签的多种关系,多个特征与标签之间的关联关系,以及特征之间的关联关系。通过设置权重,也可以仅从单个方面对数据的单个特性进行针对性的研究。
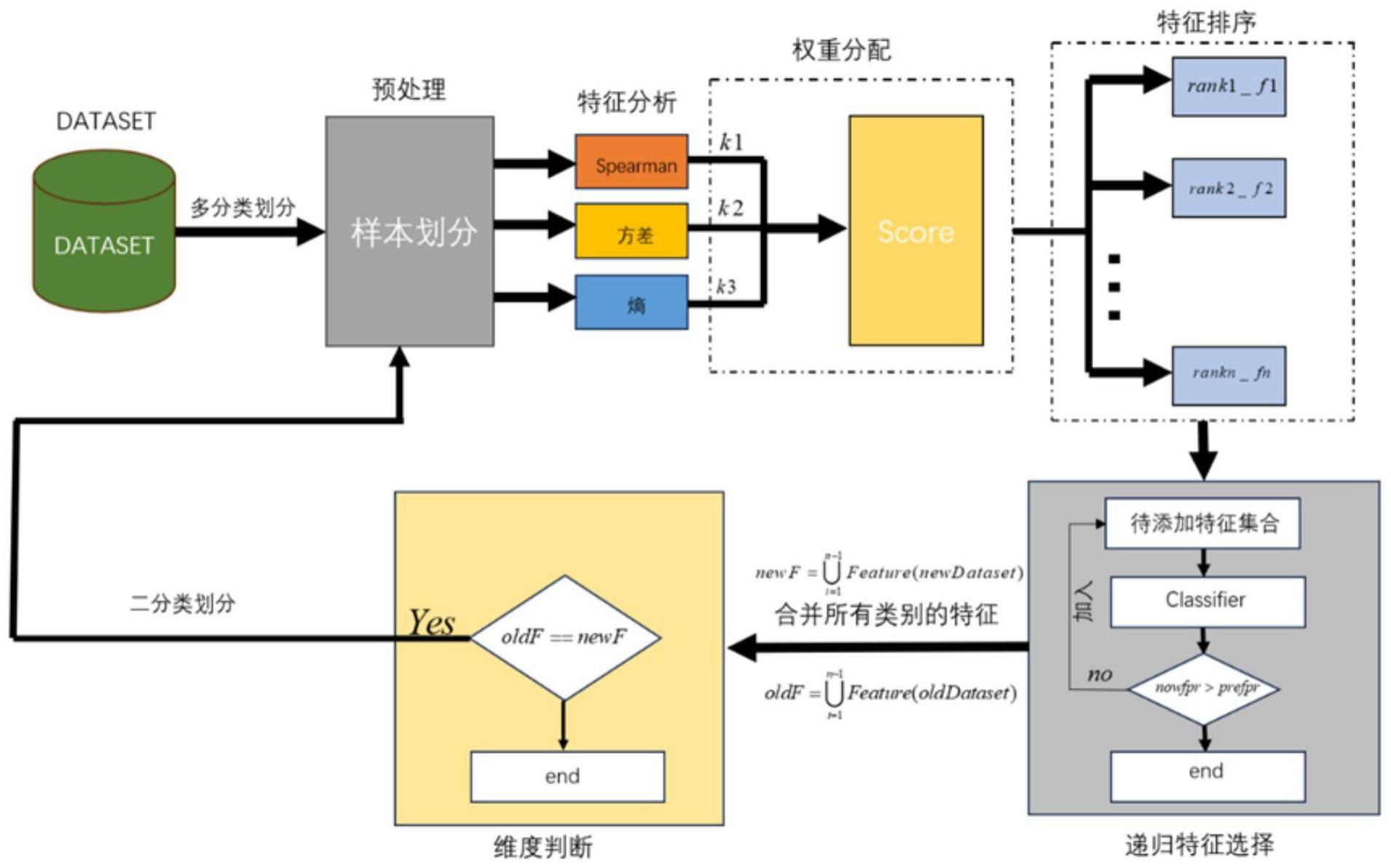
2、为了实现上述目的,本发明的技术方案为:一种结合熵、方差和相关系数的权重分配特征评估与选择方法,包括以下步骤:
3、(1)确定需要进行特征选择的数据集a;
4、(2)对a数据进行样本的划分;
5、(3)基于spearman相关系数,计算(2)中每类样本每个特征的相关系数;
6、(4)计算(2)中每类样本每个特征的方差;
7、(5)计算(2)中每类样本每个特征的熵;
8、(6)将(3)(4)(5)中得到的特征指标进行缩放后再进行权重分配;
9、(7)递归添加特征,选择出最重要的特征集合;
10、(8)合并经过特征选择后(2)中的每个样本,并进行特征维度检查。
11、所述步骤(1)确定需要进行特征选择的数据集a;其步骤如下:
12、确定需要进行特征选择的数据集a;首先确定需要进行特征提取的数据集a,a应尽可能含有高维的特征以及细分的标签类别。
13、进一步,所述步骤(2)对a数据进行样本的划分;其步骤如下:
14、对a数据集进行样本类别的划分。假设a数据集中有n种不同的样本类型(包括小样本,和大样本和正类样本),并且a中只有一类为正类,其他类别统一称为负类;则将a数据集按照标签进行划分后,得到样本集合a1,a2,…,an。
15、进一步,所述步骤(3)基于spearman相关系数,计算(2)中每类样本每个特征的相关系数;其步骤如下:
16、步骤3.1:对于a1,a2,…,an中的每一中样本ai,使用spearman特征选择技术,衡量特征与标签之间的单调相关程度,计算出ai中每一个特征的spearman相关系数。其中,spearman相关系数的计算公式如下所示:
17、
18、其中,ρ表示spearman相关系数,di表示每对变量在等级上的差异,n表示样本数量;
19、步骤3.2:规格化spearman相关系数。由于spearman相关系数的取值范围是[-1,1]之间的任意值,而spearman相关系数为0的时候代表变量之间不存在明显单调关系,且越接近两头代表相关性越高。因此,对最终的ρ做如下处理:
20、
21、其中,ρi表示每一个特征的ρ值;
22、步骤3.3:根据ρ的大小关系将特征进行排序,ρ越大则特征与其标签之间的关系越大,代表特征重要性越强。对于每一类样本i,返回排序后的特征与等级分数的字典r1i,i=1,2,3…n;
23、步骤3.4:将所有样本的特征与等级分数字典放入统一的字典中,最终获得相关系数指标下的所有类型样本的特征与ρ的字典r1,
24、即,
25、r1=r11∪r12∪…∪r1n。
26、进一步,所述步骤(4)计算(2)中每类样本每个特征的方差;其步骤如下:
27、步骤4.1:对于a1,a2,…,an中的每一中样本ai,基于统计特性,计算ai中每一个特征的方差var(xi),其公式如下:
28、
29、其中,xij表示第j个样本在第i个特征上的取值,表示第i个特征在整个数据集上的均值,n表示该特征下的样本总数;
30、步骤4.2:根据方差的大小进行排序,认为方差越大的数据分布越复杂信息量更多,返回特征与方差的字典r2i,i=1,2,3…n;
31、步骤4.3:将所有样本的特征与方差字典放入统一的字典中,最终获得方差指标下的所有类型样本的特征与方差的字典r2。
32、即:
33、r2=r21∪r22∪…∪r2n。
34、进一步,所述步骤(5)计算(2)中每类样本每个特征的熵;其步骤如下:
35、步骤5.1:对于a1,a2,…,an中的每一中样本ai,基于信息论,计算ai中每一个特征的熵h(xj),其公式如下:
36、
37、其中,xj表示特征j,x表示特征xj的取值,p(x)表示特征xj取值为x的概率。
38、步骤5.2:根据熵的大小进行排序,认为熵越大的特征所含信息量更丰富,返回特征与其熵的字典r3i,i=1,2,3…n,如果出现负熵,直接丢弃该特征。
39、步骤5.3:将所有样本的特征与熵字典放入统一的字典中,最终获得熵指标下的所有类型样本的特征与熵的字典r3。
40、即:
41、r3=r31∪r32∪…∪r3n。
42、进一步,所述步骤(6)将(3)(4)(5)中得到的特征指标进行权重分配;其步骤如下:
43、步骤6.1:对于集合a1,a2,…,an中每种样本的ai,取出其特征的三个指标字典r1i,r2i,r3i,即对于ai中的每一个特征j,计算该特征的综合得分scorej:
44、scorej=k1 r1 r1j+k2 r2 r2j+k3 r3 r3j;
45、其中,k1,k2,k3分别表示每个特征在r1,r2,r3所对应指标中分配的权重;这个权重是根据指标重要性自行指定的定值,且k1+k2+k3=1;r1,r2,r3为缩放比例系数,将过大或者过小的指标进行缩放,使得三个指标具有相似的数值范围。缩放比例可以根据指标的数值大小进行指定。
46、关于对k1,k2,k3的确定,可以尝试不同的取值组合,只需满足k1+k2+k3=1即可,目的是选出最佳的指标组合以达到最好的分类模型检测率。
47、关于r1,r2,r3的确定,可以通过观察特征指标的量级大小,手动的指定比例系数使得每个特征下的三个指标含有相同的数值范围;也可以使用最大-最小缩放法,将所有特征均缩放至0-1的范围内,再进行综合得分的计算,其公式如下:
48、
49、其中,x是某个特征指标下的原始值,xmin是某个特征指标下的最小值,xmax是某个特征指标下的最大值,xscaled是经过缩放后的最终值;
50、对字典r2和字典r3中的每一类样本中的所有特征依次进行最大最小缩放,得到范围为[0,1]的缩放后的指标字典r2和r3。
51、步骤6.2:根据步骤6.1公式,对集合a1,a2,…,an中每一中样本ai,可以获得ai中每一个特征的综合得分。根据综合得分score,对ai中的每个特征进行最终排名,score越大的特征,拥有越好的统计特性,相关性以及信息量,从而在该样本上具有更加重要的地位,返回特征与综合得分的字典r4i,i=1,2,3…n。
52、步骤6.3:将所有样本的特征与综合得分字典放入统一的字典中,最终获得综合得分指标下的所有类型样本的特征与熵的字典r4,
53、即:
54、r4=r41∪r42∪…∪r4n。
55、进一步,所述步骤(7)递归添加特征,选择出最重要的特征集合;其步骤如下:
56、步骤7.1:取出a1,a2,…,an中的正类样本,记为apos,将其他的所有负类记为aneg。
57、步骤7.2:将apos与aneg中的每一类样本进行两两合并,构成只含有两个标签的集合s,即:
58、s={(apos,aneg(i))∣apos=apos,aneg(i)∈aneg,i=1,2,…,n-1}
59、步骤7.3:对于s中的每个数据集si,均含有正类样本和负类样本,将正类样本的特征依次提取到spos集合中,将负类样本的特征依次提取到集合sneg(i)中。对每一个数据集si都做上述操作后,得到最终的spos和sneg。由于假设只存在一个正类,所有spos对于所有的si都是相同的,即spos为正类所有特征排序后的集合;sneg即为所有负类的所有特征排序后的集合,sneg中共含有n-1个元素。
60、步骤7.4:对于s中的每个数据集si,取其正类中的前三个特征,加入特征集合posi中;再取其负类中的前3个特征,加入特征集合negi中,在选取过程中若发现共同的特征,则在posi和negi中均加入该特征。对每个si都做相同操作后,最终获得s中所有元素的正类样本仅含三个特征的特征集集合pos,负类样本的仅含三个特征的特征集集合neg。初始时,将pos和neg称为初始特征集,在后续步骤7.5递归操作中,逐一的在其中添加新的特征,最终完成特征选择。
61、步骤7.5:对于s中的每个数据集si,其中每类负类的初始特征集合为negi,正类的初始特征集合为posi,按照如下步骤进行处理;1)建立二分类模型,将negi和posi进行合并作为训练用初始特征集,使用初始特征集对si进行分类,获得正类和负类的初始误报率;2)从spos中选择下一个特征(排除一开始的三个,按顺序往下选)加入posi;3)将negi和posi进行合并作为训练用特征集,使用1)中模型对其进行分类,对比当前正类误报率与前一次正类误报率是否有所降低,若无明显降低或误报率提高,则停止迭代,转至4),否则将所选特征加入posi,并重复2)3);4)从sneg(i)中选择下一个特征(排除一开始的三个,按顺序往下选)加入negi;5)将negi和posi进行合并作为训练用特征集,使用1)中模型对其进行分类,对比当前负类误报率与前一次负类误报率是否有所降低,若无明显降低或误报率提高,则停止迭代,转至6),否则将所选特征加入negi,并重复4)5);6)对s中每个数据集重复上述过程,最终对于s中的每类样本si都可以获得其正类和负类所需要的最重要的特征集合pos和neg。
62、步骤7.6:对于s中的每个数据集si,根据步骤7.5获得的posi和negi,将posi和negi进行特征合并,并去重,得到si最终所需的特征集,根据此特征集,从si中导出新的数据集newsi;对每个si做相同的操作,最终可以获得正类与每一类负类组成的含有两个类别且经过特征选择的新数据集news,
63、即,
64、news=news1∪news2∪…∪newsn
65、进一步,所述步骤(8)合并经过特征选择后步骤(2)中的每个样本,并进行特征维度检查;其步骤如下:
66、步骤8.1:根据步骤7.6,导出了正类与每一类负类组合而成的数据集集合news,这个集合中含有n-1个子数据集,每个子数据集都经过了特征选择,从而他们之间的特征数量以及特征含义可能都存在不同,即,对于不同的类别i和j有可能有如下的不等式关系:
67、posi∪negi≠posj∪negj
68、这种情况下,将所有的子数据集特征进行合并,得到完整数据集的特征集合f,即:
69、
70、步骤8.2:根据步骤8.1得到的完整特征集合f,假设原数据集a的特征集合为x,对f和x做如下判断:
71、
72、步骤8.3:由于x=f,则先划分样本经过特征提取后再合并的方式达不到降维的效果。这里需要说明的是,将样本进行划分再进行特征提取的方式,可以充分考虑每一种样本的特点,从而有利于后续合并样本后的多分类,如果此种方式达不到降维的效果,考虑使用二分类技术,即,将正类归为一类,将所有其他类归为负类,再重复步骤(3)-(7)的过程。当然,认为单独考虑每一类样本会有比较好的结果,无论对多分类还是二分类都是十分有效的,具体要看实验效果。
73、本发明还提出一种计算机设备,该计算机设备能够执行上述的方法。
74、本发明的有益效果:
75、(1)本发明通过设置权重有效结合了数据的统计特性,信息特性和相关度特性,使得既可以从单个方面来对数据进行分析,也可以从多个方面对数据进行分析,也可以通过设置不同的权重比例研究出最好的特征选择方式,从而大大便利了特征提取过程,以及提取特征的准确和全面性,进而能够达到降低维度、消除冗余、提高模型训练效率和减少过拟合的目的。
76、(2)本发明通过递归的添加特征训练模型,并选择正类和负类误报率作为递归停止的指标,在保证高的模型性能的同时,也充分的考虑了多特征与标签之间的联系,这是一般基于统计,相关度和信息论的特征选择就似乎所达不到的效果。
- 还没有人留言评论。精彩留言会获得点赞!