基于知识图谱的文本分类方法、系统、存储介质及计算机
本发明涉及数据处理,特别涉及一种基于知识图谱的文本分类方法、系统、存储介质及计算机。
背景技术:
1、随着移动互联网和信息技术的高速发展,社会进入信息爆炸时期,如何高效地将海量的农业信息标注到所属的类别仍然是一个难以解决的问题。在农业领域下,存在着数据稀疏且质量低下的问题。为了有效解决这一问题,农业文本分类技术应运而生。
2、目前业内的主流的共有三种技术路线,一是基于领域词典的文本分类,该方法可解释性强,易于理解,但缺点是过于依赖于领域词典的质量和规模。二是基于机器学习的文本分类,诸如knn、朴素贝叶斯、svm等算法都是其应用的典型代表算法。这类基于机器学习的分类算法虽然能一定程度上提升模型的准确率,但是忽略了文本深层的语义关系。三是基于深度学习的文本分类,该类方法能够较好地捕捉到文本上下文依赖关系,在各评价指标上也有较好的表现,但是此类算法训练模型需要大规模数据和强大的算力支持,且其模型可解释性差。
技术实现思路
1、基于此,本发明的目的是提供一种基于知识图谱的文本分类方法、系统、存储介质及计算机,以至少解决上述技术中的不足。
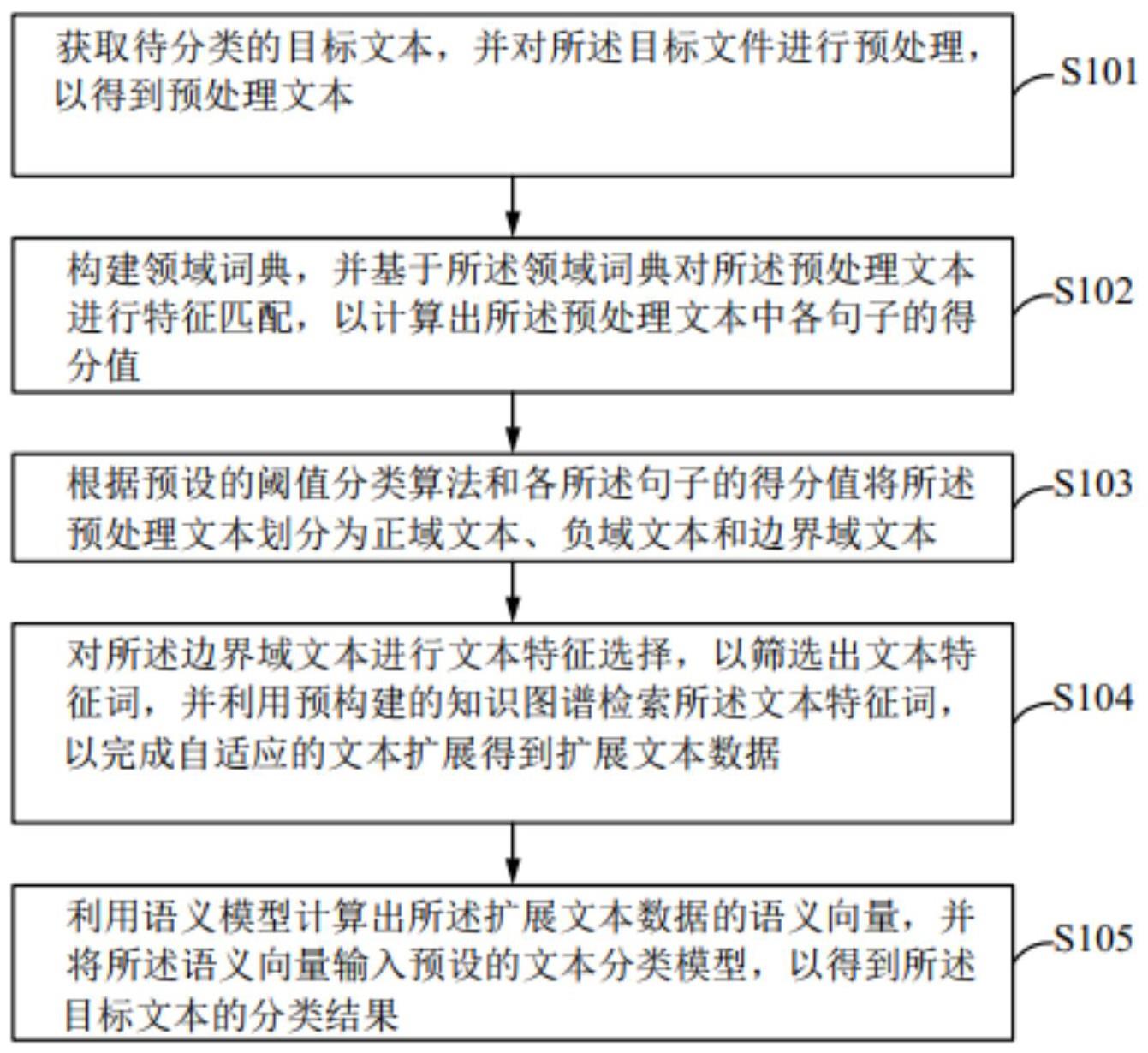
2、本发明提出一种基于知识图谱的文本分类方法,包括:
3、获取待分类的目标文本,并对所述目标文件进行预处理,以得到预处理文本;
4、构建领域词典,并基于所述领域词典对所述预处理文本进行特征匹配,以计算出所述预处理文本中各句子的得分值,其中,所述构建领域词典,并基于所述领域词典对所述预处理文本进行特征匹配,以计算出所述预处理文本中各句子的得分值的步骤包括:
5、基于所述目标文本的文本领域获取对应的领域词汇本体库中打分计算规则;
6、获取所述预处理文本的领域词汇,并根据所述领域词汇本体库中打分计算规则计算出所述领域词汇的类别极性和强度;
7、利用特征词汇得分值算法、所述领域词汇的类别极性以及所述领域词汇的强度计算出所述领域词汇的得分值;
8、将所述预处理文本中所有的领域词汇的得分值进行累加,并利用程度副词计算出所述预处理文本的句子整体强度,以得到所述预处理文本中各句子的得分值,所述领域词汇的得分值的表达式为:
9、;
10、式中,表示领域词汇的类别极性,表示领域词汇的强度;
11、所述预处理文本中各句子的得分值的表达式为:
12、;
13、式中,表示预处理文本的句子整体强度,表示第个领域词汇的得分值;
14、根据预设的阈值分类算法和各所述句子的得分值将所述预处理文本划分为正域文本、负域文本和边界域文本;
15、对所述边界域文本进行文本特征选择,以筛选出文本特征词,并利用预构建的知识图谱检索所述文本特征词,以完成自适应的文本扩展得到扩展文本数据;
16、利用语义模型计算出所述扩展文本数据的语义向量,并将所述语义向量输入预设的文本分类模型,以得到所述目标文本的分类结果。
17、进一步的,根据预设的阈值分类算法和各所述句子的得分值将所述预处理文本划分为正域文本、负域文本和边界域文本的步骤包括:
18、根据所述阈值分类算法获取第一阈值指标和第二阈值指标,当所述句子的得分值不小于所述第一阈值指标时,将所述句子所对应的预处理文本标记为正域文本;
19、当所述句子的得分值不大于所述第二阈值指标时,将所述句子所对应的预处理文本标记为负域文本;
20、当所述句子的得分值小于所述第一阈值指标、且大于所述第二阈值指标时,将所述句子所对应的预处理文本标记为边界域文本。
21、进一步的,对所述边界域文本进行文本特征选择,以筛选出文本特征词,并利用预构建的知识图谱检索所述文本特征词,以完成自适应的文本扩展得到扩展文本数据的步骤包括:
22、获取变种变量相关性分析算法和变种的词频-逆文档频率算法,并利用所述变种变量相关性分析算法和所述变种的词频-逆文档频率算法对所述边界域文本进行文本特征选择,以计算出所述边界域文本中所有特征词的贡献度;
23、将各所述特征词按照其对应的贡献度进行排序,并根据排序所得到的排序表和所述特征词的总数筛选出对应的文本特征词;
24、检索出所述文本特征词在所述知识图谱中一跳范围内的所有节点,并将所述节点组合形成扩展文本数据。
25、本发明还提出一种基于知识图谱的文本分类系统,包括:
26、预处理模块,用于获取待分类的目标文本,并对所述目标文件进行预处理,以得到预处理文本;
27、特征匹配模块,用于构建领域词典,并基于所述领域词典对所述预处理文本进行特征匹配,以计算出所述预处理文本中各句子的得分值,其中,所述特征匹配模块包括:
28、规则获取单元,用于基于所述目标文本的文本领域获取对应的领域词汇本体库中打分计算规则;
29、词汇计算单元,用于获取所述预处理文本的领域词汇,并根据所述领域词汇本体库中打分计算规则计算出所述领域词汇的类别极性和强度;
30、得分值计算单元,用于利用特征词汇得分值算法、所述领域词汇的类别极性以及所述领域词汇的强度计算出所述领域词汇的得分值;
31、特征匹配单元,用于将所述预处理文本中所有的领域词汇的得分值进行累加,并利用程度副词计算出所述预处理文本的句子整体强度,以得到所述预处理文本中各句子的得分值,所述领域词汇的得分值的表达式为:
32、;
33、式中,表示领域词汇的类别极性,表示领域词汇的强度;
34、所述预处理文本中各句子的得分值的表达式为:
35、;
36、式中,表示预处理文本的句子整体强度,表示第个领域词汇的得分值;
37、文本处理模块,用于根据预设的阈值分类算法和各所述句子的得分值将所述预处理文本划分为正域文本、负域文本和边界域文本;
38、文本检索模块,用于对所述边界域文本进行文本特征选择,以筛选出文本特征词,并利用预构建的知识图谱检索所述文本特征词,以完成自适应的文本扩展得到扩展文本数据;
39、文本分类模块,用于利用语义模型计算出所述扩展文本数据的语义向量,并将所述语义向量输入预设的文本分类模型,以得到所述目标文本的分类结果。
40、进一步的,所述文本处理模块包括:
41、第一文本处理单元,用于根据所述阈值分类算法获取第一阈值指标和第二阈值指标,当所述句子的得分值不小于所述第一阈值指标时,将所述句子所对应的预处理文本标记为正域文本;
42、第二文本处理单元,用于当所述句子的得分值不大于所述第二阈值指标时,将所述句子所对应的预处理文本标记为负域文本;
43、第三文本处理单元,用于当所述句子的得分值小于所述第一阈值指标、且大于所述第二阈值指标时,将所述句子所对应的预处理文本标记为边界域文本。
44、进一步的,所述文本检索模块包括:
45、贡献度计算单元,用于获取变种变量相关性分析算法和变种的词频-逆文档频率算法,并利用所述变种变量相关性分析算法和所述变种的词频-逆文档频率算法对所述边界域文本进行文本特征选择,以计算出所述边界域文本中所有特征词的贡献度;
46、特征词筛选单元,用于将各所述特征词按照其对应的贡献度进行排序,并根据排序所得到的排序表和所述特征词的总数筛选出对应的文本特征词;
47、文本检索单元,用于检索出所述文本特征词在所述知识图谱中一跳范围内的所有节点,并将所述节点组合形成扩展文本数据。
48、本发明还提出一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述的基于知识图谱的文本分类方法。
49、本发明还提出一种计算机,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的基于知识图谱的文本分类方法。
50、本发明当中的基于知识图谱的文本分类方法、系统、存储介质及计算机,通过对待分类的目标文本进行预处理,并利用领域词典对预处理后的文本进行特征匹配,以得到文本中各句子的得分值,根据阈值分类算法和各得分值将文本划分为正域文本、负域文本和边界域文本,针对边界域文本进行文本特征选择,并利用知识图谱检索选择出的文本特征词,以完成自适应的文本扩展得到扩展文本数据,过滤掉低贡献度的特征词,保留高贡献度的特征词,达到扩大信息量的目的。
- 还没有人留言评论。精彩留言会获得点赞!