一种用于用户复购行为的预测方法及其装置
本发明属于用户行为分析和数据挖掘,尤其涉及一种用于用户复购行为的预测方法及其装置。
背景技术:
1、从具有数据体量大、维度高、有效信息有限、价值密度低等特点的大量用户中挖掘老用户,可以有效降低企业运行成本,提高客户的购物体验。
2、有的机器学习和集成学习在预测用户购买行为中应用在预测过程中也存在一些问题,例如,类别数据不平衡;单一模型在未学习的数据上表现糟糕;单个学习器可能会陷入局部最优等。这些都增加了预测用户复购行为的难度,降低了预测的精度。
3、针对现有技术的不足,提出一种稳定性高、泛化能力强的集成学习法来预测用户复购行为是必要的。
技术实现思路
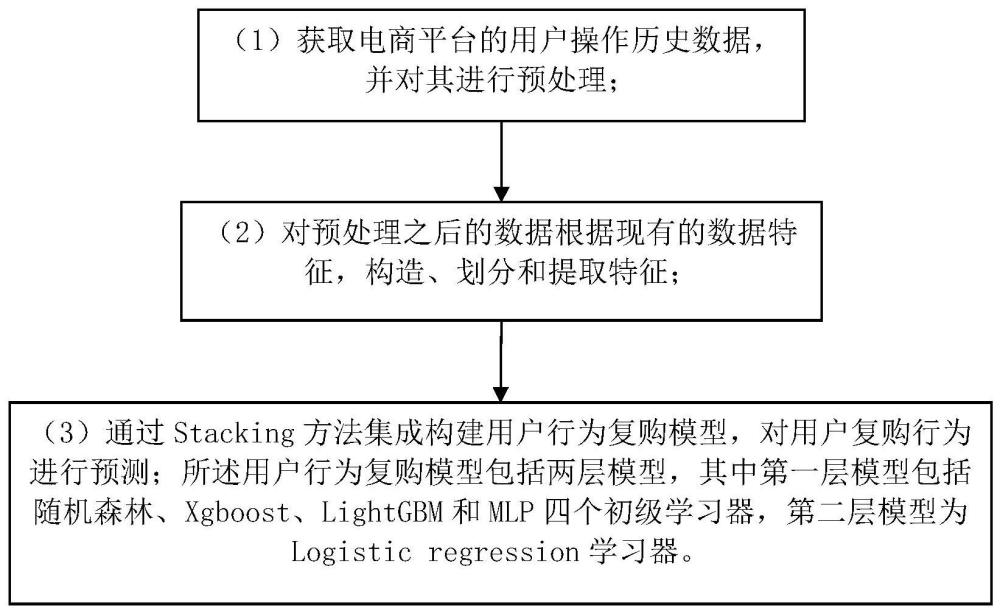
1、本发明的目的在于提供一种用于用户复购行为的预测方法,其特征在于,包括如下步骤:
2、s1:获取电商平台的用户操作历史数据,并对数据进行预处理;
3、s2:对于处理后的数据根据现有的数据特征构造、划分和提取特征;
4、s3:基于s2中构造、划分和提取的特征,采用stacking方法集成构建用户行为复购模型,完成对用户复购行为的预测。
5、进一步地,s1中,对用户操作历史数据的预处理包括以下步骤:
6、s11:对获取的历史数据进行量化处理;
7、s12:对量化后数据的缺失值和异常值进行处理;
8、s13:划分训练数据和测试数据;
9、s14:对数据特征进行归一化处理;
10、s15:利用borderlines-smote算法对归一化处理后的数据的不平衡性进行扩充;
11、s16:对于完成扩充后的数据,在训练数据上使用5折交叉验证法划分训练集和验证集,通过训练集和验证集评估不同参数下的模型性能。
12、进一步地,s11中,历史数据具体为电商平台用户在特定时间当天以及此特定时间前六个月的用户行为日志、用户画像、训练数据和测试数据,并将用户行为、性别等字符型数据转换成数值型数据,最后对提取的数据进行量化;
13、s12中,采取前向填充方法插补用户年龄和性别的缺失数据,具体为根据特征的本身含义,使用0值填充缺失的特征;
14、s13中,对处理后的数据通过分层抽样抽取20%的数据作为测试数据,其余数据为训练数据,抽取测试数据时,通过固定随机数种子确保结果的可复现性;
15、s14中,在归一化数据时,对测试数据和训练数据分别进行归一化,进行归一化数据时,通过对类别特征进行one-hot编码处理,从而使归一化后的数据不失去原本的特征含义,归一化具体为min-max归一化,计算公式表示为:
16、
17、其中,x为特征;xmax为特征在样本中的最大值;xmin为特征在样本中的最小值;
18、s15中,在不包含测试数据的训练数据上进行数据扩充;
19、s16中,交叉验证将训练数据均分为5分,依次选择其中一份数据作为验证集,其余4份作为训练集,通过在训练集上训练模型,在验证集上评估模型,最后使用5次评估结果的平均作为最终结果。
20、进一步地,s2中,对于处理后的数据进行构造、划分和提取特征具体包括以下步骤:
21、s21:特征构造具体为:首先利用用户行为日志和用户画像提供的基本数据,对用户和店铺构造特征,反映用户和店铺个体的基本属性,然后从用户+店铺的角度出发,构造特征;
22、s22:划分特征具体为:根据特定时期当天和该日前两个不同时间点对也正进行划分;
23、s23:特征提取具体为:建立随机森林模型充分学习训练数据,使用mdi作为评价特征重要性的指标,从原始的特征中筛选出重要度总和达到预设阈值且位于前几位的多个特征作为输入特征,完成特征选择。
24、进一步地,mdi的指标定义公式表示为:
25、
26、其中,为随机森林中所有树;t为树中的结点;i(jt=j)为该节点是否使用第j个变量;xj为划分特征;p(t)为结点t处的样本比例当基尼系数作为不纯度指标时,δi(st,t)为划分前后的基尼不纯度减少;st为最佳分裂结点;
27、在训练随机森林进行特征选择时,通过改变多数类和少数类的权重,使随机森林模型同时兼顾多数类和少数类,输出更合理的特征,其中,类别权重的计算公式表示为:
28、
29、其中,nsamples为样本量;nj为类j的样本数量。
30、进一步地,s3中,用户行为复购模型包括第一层模型和第二层模型,第一层模型包括随机森林、xgboost、lightgbm和mlp四个初级学习器,第二层模型为logisticregression学习器,具体通过以下步骤实现:
31、s31:调整随机森林、xgboost、lightgbm和mlp四个初级学习器的最优参数;将auc值作为优化目标,使用tree-structured parzen estimator(tpe)优化算法进行参数调优;
32、s32:通过stacking集成方法,基于4个初级学习器通过stacking方法构建次级学习器的训练数据,使用次级学习器logistic regression进行学习,完成模型集成,得到最终的用户行为复购模型,从而完成对用户复购行为进行预测。
33、进一步地,s31中,xgboost的目标函数表示为:
34、
35、其中,yi为第i个样本的真实值;t为树模型的结点数;fk为第k个树模型;w'为叶子节点权重向量;γ和λ皆为自定义常系数;l为度量预测值和真实值yi的损失函数;惩罚项ω用于限制模型的复杂度;
36、lightgbm为在xgboost的基础上加入四方面的优化,四方面具体为:单边梯度采样、互斥特征捆绑、直方图加速算法以及带有深度限制的leaf-wise生长策略;
37、mlp的基本学习过程为:首先将信号输入后通过隐藏层前向传播给输出层,输出层计算输入信号与期望值的损失,当损失超过设定的范围,则通过反向传播算法对参数进行学习,直到达到预设范围;
38、logistic regression即逻辑回归模型,用于通过线性回归模型对事件的对数几率进行拟合,事件的对数几率表示为:
39、
40、其中,p为事件发生概率;因此,在模型中表示为:
41、
42、其中,w为权值向量;w=(w(1),w(2),...,w(n),b)t,b为常数系数;x为输入向量;x=(x(1),x(2),...,x(n),1)t;p(y=1|x)为在x已知的条件下,y=1发生的概率;
43、逻辑回归模型学习时,权值向量和偏置值的参数估计通过极大似然估计来进行求解;对于给定的训练集t={(x1,y1),(x2,y2),...,(xn,yn)},其中,yi∈{0,1};
44、设p(y=1|x)=π(x),p(y=0|x)=1-π(x),则样本的似然函数表示为:
45、
46、定义损失函数,表示为:
47、
48、最终通过求损失函数极小值或求似然函数极大值来得到权值向量w的估计;
49、auc是指roc曲线下的面积,roc曲线为全程受试者曲线,其横坐标为假阳性率,纵坐标为真阳性率,假阳性率和真阳性率的计算公式分别表示为:
50、
51、
52、其中,p为真实的正样本的数量;n为真实的负样本的数量;tp是p个正样本中被分类器预测为正样本的个数;fp是n个负样本中被分类器预测为正样本的个数;tn是被分类器正确分类的负样本个数;fn是被错误地标记为负样本的正样本个数;
53、准确率反映了模型分类正确的样本数占所有样本个数的比例,准确率accuracy表示为:
54、
55、其中,ncorrect为被正确分类的样本个数;ntotal为样本的总个数。
56、一种用于用户复购行为预测装置,使用用于用户复购行为的预测方法,其特征在于,包括处理器、存储器和至少一个程序,至少一个程序存储于存储器内,并通过处理器进行执行,至少一个程序包括用于执行用于用户复购行为的预测方法中的步骤的指令。
57、进一步地,还包括计算机可读存储介质,计算机可读存储介质用于存储至少一个程序,程序使计算机执行用于用户复购行为的预测方法中的步骤。
58、与现有技术相比,本发明的有益效果主要体现在:
59、1、当样本量相对较少时,单一模型容易过拟合,本发明方法构建组合模型从不同视角进行预测,使得整体泛化性能表现良好。
60、2、当局部搜索时,单个学习器会陷入局部优势,本发明方法利用组合方式可以降低陷入局部最小点的风险。
- 还没有人留言评论。精彩留言会获得点赞!