基于多样性图融合的多视图子空间聚类方法
本发明涉及机器学习和数据挖掘,具体地,涉及一种基于多样性图融合的多视图子空间聚类方法。
背景技术:
1、多视图数据是指来自不同源头或来源的、在不同特征空间中描述的数据。对于同一对象或事物,不同的数据视图可能呈现出各自独特的特性信息,这些信息可以互为补充或相互矛盾,但都可以提供关于该对象或事物更全面和准确的描述。例如,一条新闻或者文本可以用不同的语言表达,比如,中文,英文,西班牙文等。一个网站可以用视频,音频,文字等来表示,一辆汽车可以从不同的角度来观察,从正面,侧面,背面等。又例如,在人脸识别领域中,一个人的面部图像可以被表示为不同的视图,如灰度图像、深度图像、红外图像等。每个视图可以提供不同的信息来帮助识别和验证该人的身份。同时,在社交网络分析领域中,用户的信息可以从多个角度收集和描述,如好友列表、发帖记录、用户画像等,这些信息可以结合起来形成一个用户的多视图数据。
2、多视图聚类(multi-view clustering)是指使用不同的数据视图或数据源,对样本进行聚类分析。多视图聚类通常用于解决单视图聚类中数据不完整、数据维度高等问题,其目的是通过从不同角度和多个数据源获取样本的性质和特征,挖掘多视图数据的潜在结构,提高聚类的准确性和稳健性。常见的多视图聚类方法可分为四类:(1)基于联合训练(co-training)的多视图聚类;(2)基于多核学习(multiple kernel learning)的多视图聚类;(3)基于图学习(graph learning)的多视图聚类;(4)基于子空间(subspace learning)学习的多视图聚类。这些多视图聚类方法的主要思路是通过融合不同视图的信息,将多个视图关联起来形成一个新的视图,然后在新的视图上进行聚类分析。多视图聚类是数据挖掘、图像处理、自然语言处理等领域中的重要技术,广泛应用于文本分类、图像识别、蛋白质功能预测等任务中。
3、多视图子空间聚类(multi-view subspace clustering)是一种集成多个视图数据的聚类方法。在现实世界中,可以从不同的传感器、不同的算法或不同的特征提取器中获得多个视图的数据。但是,每个视图都可能只能提供数据的一个方面,因此只使用单个视图来聚类数据可能会导致信息损失和结果不准确。与传统的单视图聚类方法相比,多视图子空间聚类可以更好地处理具有复杂结构的数据,并且更加鲁棒和可靠。多视图子空间聚类通过利用多个视图的优势,将它们组合起来以更好地表示数据,并且通过保留每个视图中的子空间结构,以便更好地识别和区分数据。由于多视图聚类可以提供更全面和准确的聚类结果,因此在许多领域,例如计算机视觉、生物信息学和社交网络分析中得到了广泛应用。
4、但是,现有的多视图子空间聚类方法聚类性能不高,难以获得最佳的聚类效果。
技术实现思路
1、本发明的目的是提供一种基于多样性图融合的多视图子空间聚类方法,该方法能够提高聚类性能,获得最佳的聚类效果。
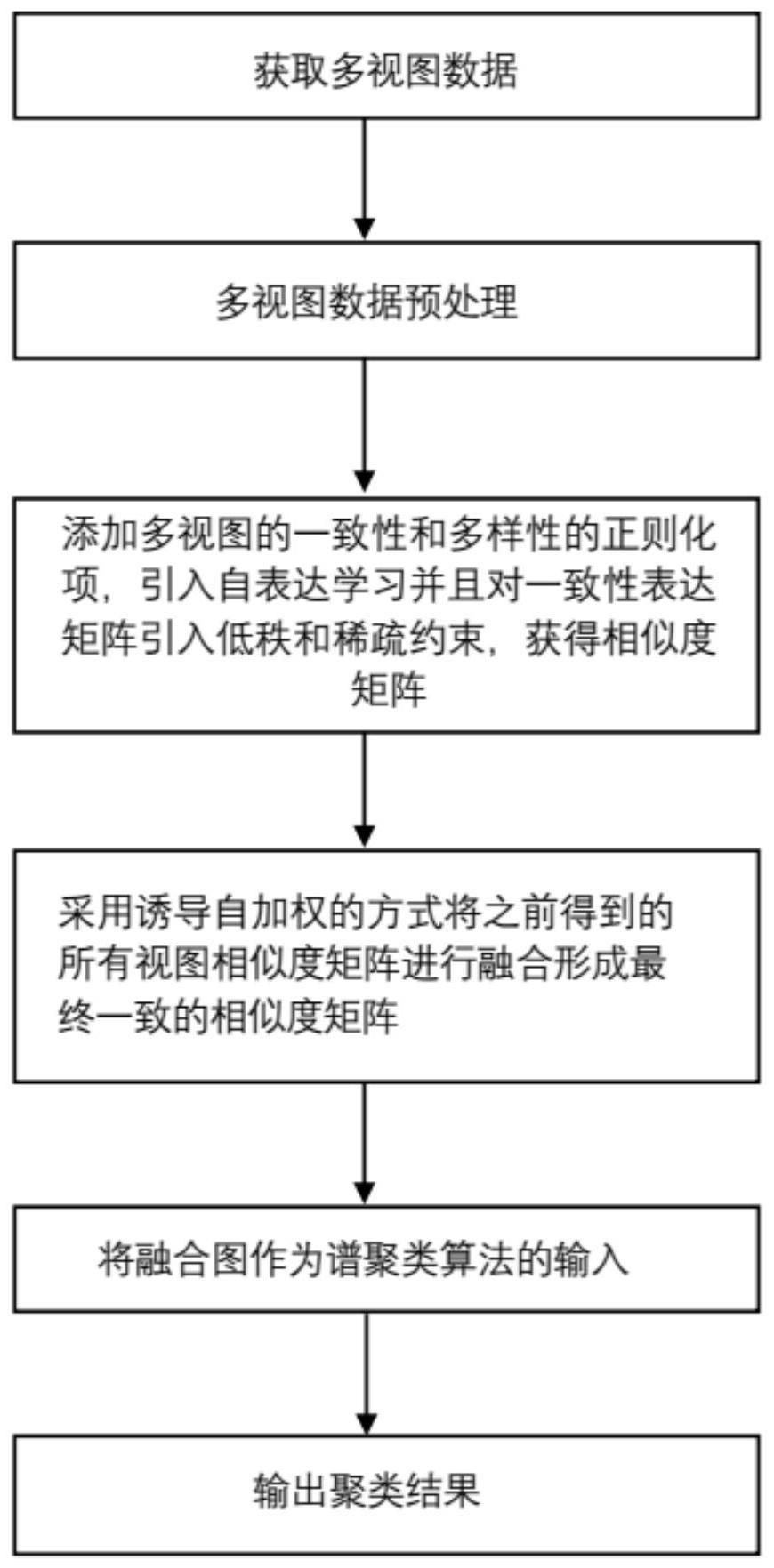
2、为了实现上述目的,本发明提供了一种基于多样性图融合的多视图子空间聚类方法,该方法包括:
3、步骤1:获取多视图数据并进行预处理;
4、步骤2:通过添加多视图的一致性和多样性的正则化项,引入自表达学习来挖掘多视图数据的内在结构,并且对一致性表达矩阵引入低秩和稀疏约束,从而获得高可靠和高鲁棒性的相似度矩阵;
5、步骤3:采用诱导自加权的方式将经过步骤2得到的视图相似度矩阵进行融合形成最终一致的相似度矩阵,作为谱聚类算法的输入并且输出聚类的结果。
6、优选地,步骤1中的预处理包括:
7、步骤1.1:特征提取,对同一批多视图数据采用多种特征提取方法得到不同的特征;
8、步骤1.2:数据清洗,对多视图数据中缺失部分采用样条插值的方法进行插值处理,对于多视图数据中出现极大或者极小的异常值采用取平均值法进行替换。
9、优选地,步骤2中获得的多视图数据中的每个视图数据所对应的相似度矩阵:
10、
11、其中,β1和β2分别是一致性矩阵的低秩约束和稀疏约束的参数;λ1和λ2为平衡参数;目标函数中第三项是采用了以位置为核心的多样性计算方法的多样性正则项,第四项为引入的一致性正则项,通过一致性指示矩阵f1来进行约束。
12、优选地,步骤3中作为谱聚类算法的输入并且输出聚类的结果为:
13、
14、优选地,在步骤3中,根据拉普拉斯矩阵性质,图u的连接点k的数目和它的拉普拉斯矩阵lu的零特征值的重根数目等同;因lu具有半正定矩阵的性质,故其特征值λn≥…≥λ2≥λ1≥0;如果则融合图u有相应k个连接点;根据ky fan定理,得到谱聚类的目标函数:
15、
16、其中,f2∈rn×k是聚类指示矩阵,lu是拉普拉斯矩阵,tr(·)表示矩阵的秩;
17、将公式(3)带入公式(2)中,得到新的表达式,即将公式(2)转化为:
18、
19、其中,ε和ζ是正则化项参数。
20、优选地,在步骤3中,通过将公式(1)和公式(4)集成在一起,得到基于多样性的多视图融合的子空间聚类方法的目标函数:
21、
22、其中,β1和β2分别是一致性矩阵的低秩约束和稀疏约束的参数;λ1和λ2为平衡参数;目标函数中第三项是采用了以位置为核心的多样性计算方法的多样性正则项,第四项为引入的一致性正则项,通过一致性指示矩阵f1来进行约束;f2∈rn×k是聚类指示矩阵,lu是拉普拉斯矩阵,tr(·)表示矩阵的秩,ε和ζ是正则化项参数;后两项采用诱导自加权的方式将之前得到的视图相似度矩阵进行融合形成最终一致的相似度矩阵;
23、由于公式(5)中存在多个变量和多个约束条件,只对其中一个变量进行求解,然后交替进行直到求得所有变量的最优解;
24、先对公式(1)进行优化,固定f1,求解c(v),公式(1)转化为如下形式:
25、
26、令a(v)、和为辅助变量,并带入到公式(6)中,表达式如下:
27、
28、引入拉格朗日表达式进行求解公式(7),可得如下的表达式:
29、
30、对a(v)进行求导,并令其为0,得到a(v)的表达式如下:
31、
32、更新的具体表达式如下:
33、
34、更新的具体表达式如下:
35、
36、更新的具体表达式如下:
37、
38、更新的具体表达式如下:
39、
40、在上述得到了a(v)、和之后,根据以下表达式来更新对偶变量:
41、
42、其中,μmax为乘子系数的最大值,ρ为乘子的正系数;
43、固定c(v),求解f1,公式(1)转为如下形式:
44、
45、其中,d(v)是第v视图的度矩阵,w(v)是第v视图的邻接矩阵;将公式(15)转化为如下表达式:
46、
47、定义矩阵m=∑v(d(v)-w(v)),公式(16)改写为:
48、
49、公式(17)对应的解为特征矩阵m的前k个最小特征值对应的特征向量,重复公式(9)至公式(17)的计算200次停止,得到了一致性表达矩阵,接着对公式(4)进行优化,固定f2和u,更新wv,其中wv表达式如下:
50、
51、其中,μ是一个非常小的数,用于防止分母为0;
52、固定f2和wv,更新u,因l是u的函数公式(4)转化为:
53、
54、对公式(19)进行转换,可转化为:
55、
56、定义公式(20)转化为:
57、
58、对公式(21)求导并且等于零得到表达式如下所示:
59、
60、固定u和wv,更新f2,将公式(1)转化为如下表达式:
61、
62、f2的最优解是由lu的k个特征值对应的k个最小的特征向量所组成;重复公式(18)至公式(23)的计算200次停止。
63、根据上述技术方案,本发明首先获取到多视图数据并且对多视图数据进行预处理。其次通过添加多视图的一致性和多样性的正则化项,引入自表达学习来挖掘多视图数据的内在结构,并且对一致性表达矩阵引入低秩和稀疏约束,从而获得高可靠和高鲁棒性的相似度矩阵。然后,采用诱导自加权的方式将之前得到的视图相似度矩阵进行融合形成最终一致的相似度矩阵。最后,将融合图作为谱聚类算法的输入并且输出聚类的结果。本发明所提供的方法在生成一致的相似度矩阵的同时也揭示了数据潜在的聚类结构,提高聚类的准确性和稳健性,获得了高质量的聚类效果。
64、本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!