一种基于非线性池化与深度可分离卷积的适用于MCU部署的图像分类方法
本发明涉及机器学习领域,具体为一种基于非线性池化与深度可分离卷积的适用于mcu部署的图像分类方法。
背景技术:
1、近年来,随着机器学习(ml)不断进步,为机器学习应用到资源受限的物联网(iot)节点上,带来了新的机遇。目前机器学习算法已广泛应用于智能家居、精准农业、消费电子等行业。尽管在微控制器(mcu)上运行机器学习模型(如图像分类等)可以避免将数据上传到云,加速实时处理和响应,极大地保护了数据隐私,同时大大减少了能源消耗,但在mcu上部署智能算法仍然面临着诸多问题。
2、1)模型大小,mcu的闪存(flash)用于存储模型参数,其空间范围大多为0~2mb,而一般轻量化的神经网络模型大小在10mb以上,例如mobilenetv2大小为13.6mb,参数效率太低。
3、2)峰值内存大小,mcu的静态随机存取存储器(sram)用于存储神经网络运行临时的中间数据,包括输入、输出激活矩阵,其存储大小一般为0~512kb。而mobilenetv2和efficientnet-b0峰值内存达到了2.29mb,不适合现有的大多数mcu。
4、3)现有的方法,利用剪枝、量化等技术进行压缩模型的方法只关注于减少模型参数和计算量并没有解决内存瓶颈,另外利用神经网络架构搜索(nas)的方法,需要花费大量硬件资源,而手工设计的网络mobilenetv2-0.35,etinynet也没有权衡峰值内存、计算量和准确率之间的矛盾。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于非线性池化与深度可分离卷积的适用于mcu部署的图像分类方法。
3、(二)技术方案
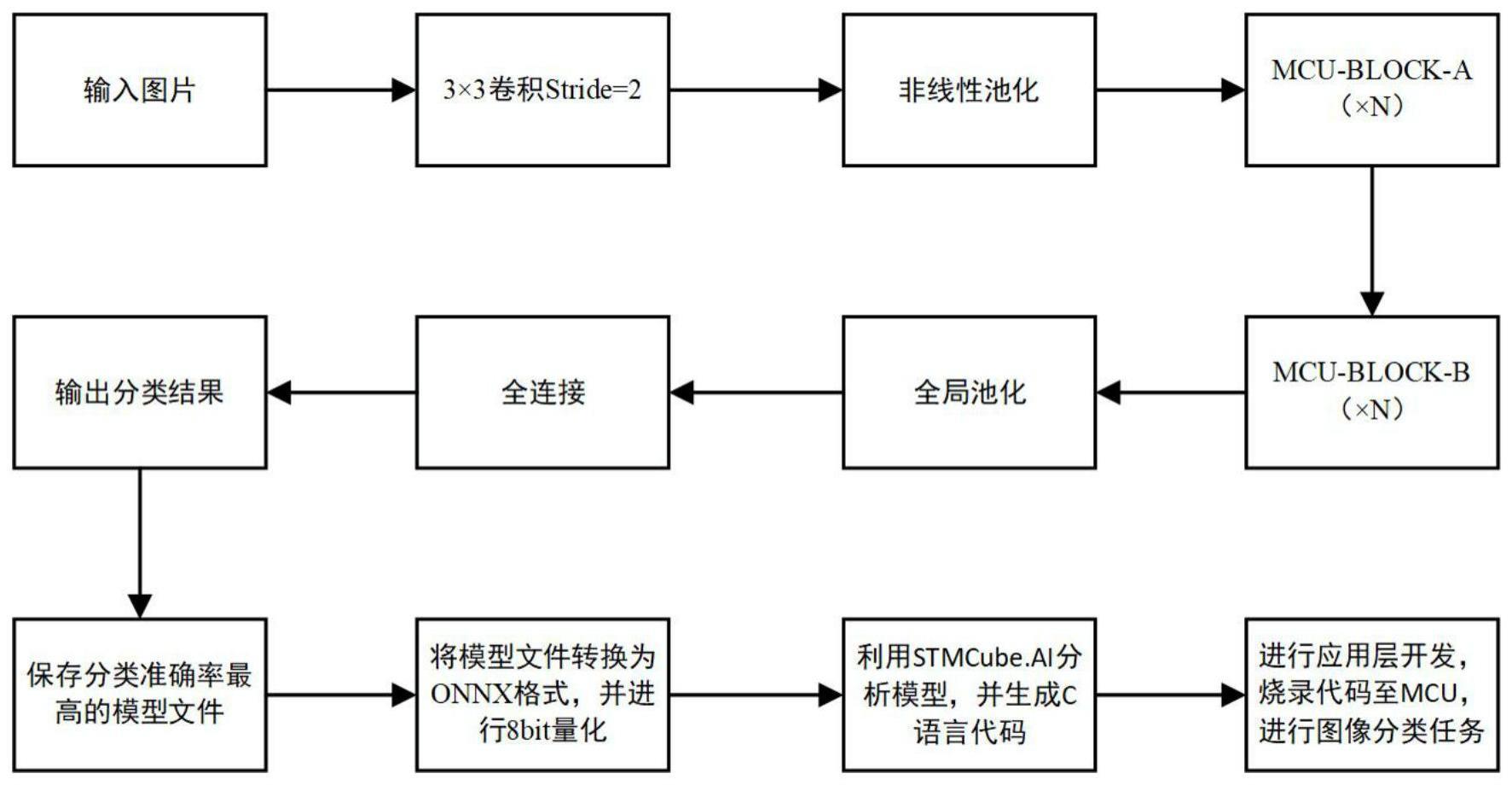
4、为实现以上目的,本发明通过以下技术方案予以实现:一种基于非线性池化与深度可分离卷积的适用于mcu部署的图像分类方法,具体包括以下步骤:
5、步骤1.mcu-block-a的获取
6、对轻量化神经网络mobilenets的深度可分离卷积进行改进得到mcu-block-a,利用一个深度卷积(dwconv)和逐点卷积(pwconv),并在它们之间加入了bn层和高效通道注意力机制(efficient channel attention,简称eca),最后再增加一层深度卷积,并将输入与最后一层深度卷积输出进行残差连接;
7、步骤2.mcu-block-b的获取
8、基于步骤1中获取的mcu-block-a,在mcu-block-a的基础上去掉输入与最后一层深度卷积输出的残差连接,增加输入与第一个逐点卷积输出的残差连接,并将连接后的输出与最后一层深度卷积的输出进行残差连接;
9、步骤3.非线性池化层的获取
10、基于非线性池化模块,在第一个卷积层后,引入非线性池化,对图片尺寸进行快速下采样,绕过中间的大激活层完成图像聚合计算衰减;
11、步骤4.模型构建
12、结合卷积、非线性池化、mcu-block-a、mcu-block-b模块进行模型的构建,权衡峰值内存、模型大小、计算量、准确率,具体包括:
13、1)第一阶段,利用步距为2的卷积进行局部特征的提取;
14、2)第二阶段,利用非线性池化沿图片中的行和列两个方向提取特征信息,然后将图片尺寸快速降低,保证cnn模型的峰值内存不高于mcu的静态随机存取存储器;
15、3)第三阶段,经过若干个mcu-block-a模块进行提取特征;
16、4)第四阶段,采用构建的mcu-block-b模块;
17、5)第五阶段,利用全局池化进行降维,最后通过全连接层得到分类结果;步骤5.模型训练及部署
18、采用imagenet数据集和视觉唤醒词数据集对模型进行训练和测试,并将在vww数据集上训练好的模型部署到单片机上测试其性能。
19、优选的,所述步骤1中mcu-block-a、步骤2中mcu-block-b、逐点卷积和深度卷积之间,以及最后一个深度卷积后均采用的relu激活函数。
20、优选的,所述步骤1中的高效通道注意力机制具体包括:
21、首先对输入原始特征图进行全局池化,再利用一个可学习的1d卷积操作,计算出每个通道的权重,公式如下:
22、wi=σ(c1dk(y))
23、其中c1dk为快速1d卷积,k表示有多少相邻的通道参与该通道的注意力预测过程,σ为sigmoid激活函数,之后与原始特征图逐元素相乘。
24、优选的,所述步骤3中的非线性池化模块具体操作包括,从输入图片中提取指定格式的感受野图片(r×c×k),其中r为感受野行尺寸,c为感受野列尺寸,k为感受野通道数。然后在行阶上利用快速门循环神经网络(fastgrnn1)进行提取特征,得到r个长度为h1的特征块,h1为fastgrnn1隐藏层尺寸,然后在r个长度为h1的特征块上进行双向的fastgrnn2,得到两个长度为h2的特征块;与在行阶上提取特征类似,首先在列阶上得到c个长度为h1的特征块,再进行双向fastgrnn2操作得到两个长度为h2的特征块;最后将四个长度为h2的特征块进行拼接,得到在单个感受野上进行非线性池化操作后的特征向量。
25、优选的,基于mcu部署cnn神经网络的步骤,具体包括以下步骤:
26、基于所述步骤四进行模型搭建,加载图像分类数据集,进行训练,保存准确率最高的模型权重文件,将模型权重文件转换成开放神经网络交换格式,再进行8bit非对称量化,量化公式为:
27、valfp32=scale*valquantized
28、
29、利用stmcube.ai工具包对模型进行分析,并生成相应的c语言基础代码,再进行上层应用的开发,实现在mcu上运行图像分类算法。
30、优选的,基于mcu部署图像分类算的装置,该装置包括mcu微处理器和摄像头,其中:
31、stm32f746g-disco作为mcu,mcu中的闪存用于存储神经网络模型权重、基础代码框架、os,mcu中的sram用于存储cnn网络运行过程中的中间激活值以及其他缓冲文件,arducam作为摄像头获取图像。
32、(三)有益效果
33、本发明提供了一种基于非线性池化与深度可分离卷积的适用于mcu部署的图像分类方法。具备以下有益效果:
34、1、本发明提供了一种基于非线性池化与深度可分离卷积的适用于mcu部署的图像分类方法,该发明引入mcu-block-a和mcu-block-b,其通过增加dwconv的数量提高参数效率,增加多个残差连接来增加网络宽度。受限于mcu内存与计算能力,传统的注意力机制se,参数多、计算量大,并不适合在mcu上部署,通过添加了eca,与传统的注意力相比,不需要引入额外的参数使得模型能够更加关注重要的特征通道,减少了普通注意力机制全连接层的参数量和计算代价,从而提高了计算效率。该发明使用少于1m参数实现了更好的分类性能。
35、2、本发明提供了一种基于非线性池化与深度可分离卷积的适用于mcu部署的图像分类方法,该发明具有更小的峰值内存,通过第一阶段使用输出通道为8步距为2的卷积,然后利用非线性池化将图片下采样到原来的1/4,因此相比较其他模型,该发明拥有更小的峰值内存,进一步减少计算量,适用于多数mcu,并取得了较好的分类性能。将机器学习模型在mcu上运行,可以避免将数据上传到云,极大地保护了数据隐私,加速实时处理和响应,大大减少了能源消耗。本发明可广泛应用于智能家居、精准农业、消费电子等行业。
- 还没有人留言评论。精彩留言会获得点赞!