一种金融问答算法的快速构建方法及生命周期管理平台
本发明涉及人工智能,具体涉及一种金融问答算法的快速构建方法及生命周期管理平台。
背景技术:
1、在金融领域,nlp技术被应用于处理大量的金融文本数据,例如金融新闻、公司报告和用户提问等。通过将nlp技术与金融数据相结合,可以构建金融问答系统,帮助用户快速获取相关的金融信息、进行数据分析和决策支持。
2、然而,这些技术和方法仍然存在一些缺点和挑战。其中一些问题包括:
3、1.算法构建效率低下:当前的金融问答系统构建过程通常需要大量的时间和资源,包括数据收集、标注、模型训练和调优等。现有方法对于快速构建金融问答算法的需求尚未得到很好解决。
4、2.系统生命周期管理不完善:在金融问答系统的实际应用中,模型的生命周期管理是一个重要而复杂的任务。现有方法缺乏一种一体化的管理平台,无法有效地支持模型的生成、测试、部署、监控和更新等环节。
5、3.缺乏领域专业知识的整合:金融领域的问答系统需要具备对金融相关问题和领域知识的理解能力。现有方法在整合领域专业知识方面存在不足,限制了问答系统在金融领域的准确性和效果。
技术实现思路
1、为了解决上述现有技术中存在的问题,本发明拟提供了一种金融问答算法的快速构建方法及生命周期管理平台,拟解决金融问答系统构建效率低下和系统生命周期管理不完善的问题。
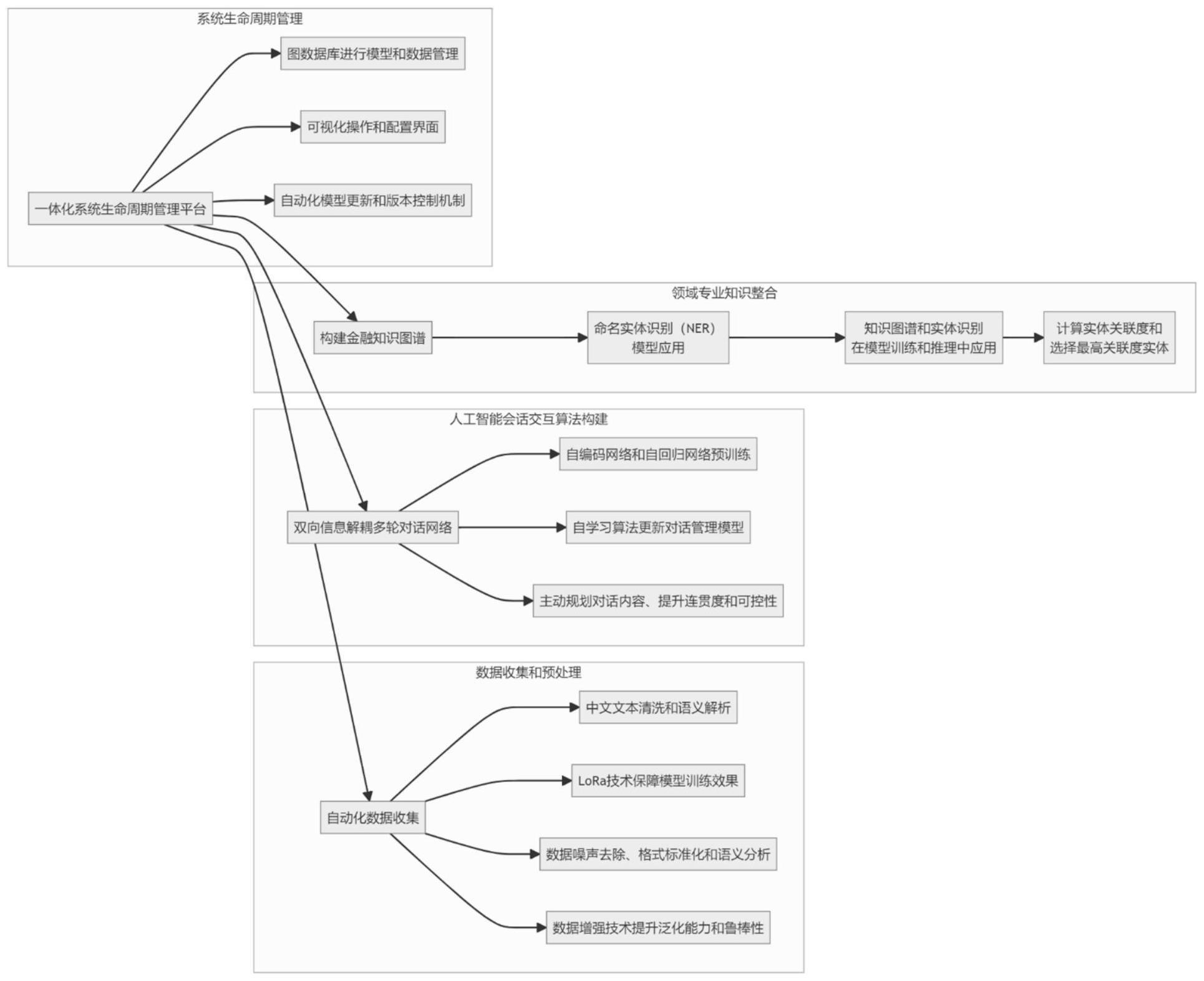
2、一种金融问答算法的快速构建方法,包括以下步骤:
3、s1:收集金融数据并进行预处理;
4、s2:构建人工智能会话交互算法;
5、s3:在人工智能会话交互算法中整合领域专业知识。
6、优选的,所述s1包括以下步骤:
7、s11:采用基于开源数据集、网络爬虫技术以及日志采集的自动化数据收集方法,从多个金融相关数据源中快速获取大规模的问答数据,所述金融相关数据源包括金融新网、报告、文档和用户提问;
8、s12:运用自然语言处理和文本清洗对收集到的大规模问答数据进行预处理,所述预处理包括去噪、文本标准化和语义解析;
9、s13:利用lora技术提取经过预处理的数据的特征。
10、优选的,所述s2包括以下步骤:
11、s21:搭建基于强化学习的双向信息解耦多轮对话网络作为通用对话编码器;将自回归网络和自编码网络融合在一起预训练,持续提升意图识别能力;
12、s22:通过融合预训练后的自回归网络和自编码网络并结合通用对话编码器搭建通用领域大规模自然处理语言模型,同时在其中引入大规模知识图谱类数据;
13、s23:通过开放域多轮对话策略学习优化通用领域大规模自然语言处理模型。
14、优选的,s21中所述双向信息解耦多轮对话网络结合强化学习作为通用对话编码器的公式如下:
15、ht=bidirectionalrnn(dh,ht-1,qt)
16、
17、其中,j(θ)表示目标函数,θ表示模型参数,q代表对话历史的序列,包括多个轮次的对话内容;a表示动作序列,表示在每一轮中双向信息解耦网络的编码选择;rt表示奖励序列,表示在每一轮中的强化学习奖励;bidirectionalrnn表示双向循环神经网络,用于编码对话历史;dh代表网络的参数,用于控制双向信息解耦网络的编码过程。
18、优选的,s21中所述自编码网络采用多任务学习进行增量式的预训练;具体的:
19、自编码网络的训练目标可以表示为:
20、
21、其中,lautoencoder表示自编码网络的训练损失,xt表示原始输入,表示重建的输入;
22、多任务学习的目标可以表示为:
23、
24、其中,lmtl表示多任务学习的总损失,αi表示任务i的权重,lossi即为任务i的损失;
25、所述自回归网络基于tranformer-xl结构,支持长文本语言模型建模。
26、优选的,s22中所述通用领域大规模自然处理语言模型中的通用对话编码器可以表示为:
27、z=encoder(q)
28、其中,z表示对话历史的编码特征,encoder表示通用对话编码器,q表示对话历史的序列。
29、优选的,所述s24包括:
30、构建基于规则对话流的对话引擎,基于监督学习实现对话管理的初步模型化,通过自学习算法持续增强对话能力,主动规划对话内容,提升多轮连贯度和可控性;
31、所述对话引擎建模为根据规则生成动作的函数:
32、at=ruleengine(dh,qt)
33、其中,at表示第t轮的动作,ruleengine表示基于规则的对话引擎,dh表示对话历史的编码特征,qt表示第t轮的对话内容;
34、所述监督学习实现对话管理的初步模型表示为:
35、p(at|dh,,qt)=softmax(w·[dh;qt])
36、其中,p(at|qh,qt)表示预测的动作概率分布,w表示模型参数,[dh;qt]表示对话历史编码特征和当前对话内容的连接;
37、所述自学习算法通过强化学习框架来更新对话管理模型:
38、
39、所述主动规划对话内容、提升多轮连贯度和可控性表示为:
40、qt+1=planner(dh,qt,at)
41、其中,qt+1表示第t+1轮的对话内容,planner表示主动规划策略,dh表示对话历史的编码特征,qt表示第t轮的对话内容,at表示第t轮的动作。
42、优选的,所述s3包括以下步骤:
43、s31:构建金融知识图谱;
44、s32:构建应用命名实体识别模型;
45、s33:将金融知识图谱和实体识别应用于人工智能会话交互算法模型的训练和推理。
46、优选的,所述s31包括:
47、所述金融知识图谱包括实体节点和关系边的定义,其中用实体集合e表示金融领域的各种实体包括公司、指标、术语,用关系集合r表示实体之间的关系包括上下游关系、同类关系,用邻接矩阵a来表示图的关系,具体的:
48、
49、其中aij表示实体i和实体j之间是否存在关系;
50、所述s32包括:
51、在命名实体识别过程中,使用条件随机场crf模型来进行实体的识别;给定一段文本序列t,定义一个状态序列s,其中si表示在位置i是否为一个命名实体;ner模块算法公式如下:
52、
53、其中,z(t)是归一化因子,n是文本序列的长度,k是特征函数的数量,λj是特征权重,fj(i,t,s)是第j个特征函数,表示位置i处的特征与状态s的关系;
54、所述s33包括:
55、将专业知识纳入人工智能会话交互算法模型,提高系统对金融问题的理解和准确性;包括:结合实体识别结果和知识图谱信息,对问题和回答进行匹配和推理;使用知识图谱和实体识别结果来增强人工智能会话交互算法模型的理解能力;计算问题中的实体与知识图谱中实体的关联度,然后基于关联度来进行问题与回答的匹配;
56、关联度(ei,ej)=相似度(ei,ej)×权重(ej)
57、其中,ei和ej分别表示问题中的实体和知识图谱中的实体,相似度(ei,ej)表示实体之间的相似度,权重(ej)表示知识图谱中实体的权重;再选择具有最高关联度的实体来进行问题与回答的匹配和推理。
58、一种金融问答算法的生命周期管理平台,所述平台用于对金融问答算法进行管理,所述管理包括算法模型的生成、测试、部署、监控及更新;所述系统生命周期管理平台包括:
59、图数据库,便于用户存储模型参数、数据集信息和实体关系,实现高效的查询和检索功能;
60、可视化的操作和配置界面,用于配置算法模型超参数、选择数据集以及设置监控指标;自动化的模型更新和版本控制机制,用于定期检测数据集的变化,监控算法模型的性能,根据配置参数自动存放模型重新训练以及部署,从而保证算法模型处于最优状态。
61、本发明的有益效果包括:
62、a.多源多角度的自动化数据收集。
63、b.预训练语言模型的迁移学习与轻量化模型设计:本发明结合了预训练语言模型的迁移学习、注意力机制的rnn或transformer模型以及轻量化模型设计;通过预训练语言模型的迁移学习和模型轻量化技术,加快模型训练速度和推理效率;同时,引入注意力机制,模型能够自动关注重要信息并进行加权处理,提升了问答系统对问题和回答之间的关联性的理解和表达能力;此外,采用知识蒸馏技术,将复杂模型的知识转移给简化的模型,实现模型的快速构建和轻量化。
64、c.应用注意力机制的序列到序列模型:通过采用序列到序列(seq2seq)模型,并引入注意力机制,模型能够自动关注问题和回答之间的重要信息并进行加权处理;这种算法模型的整合提升了问答系统对问题和回答之间关联性的理解和表达能力。
65、d.金融问答场景结构化匹配:使用命名实体识别(ner)+类目预测(意图识别)
66、+bert4keras实现k-bert;本发明构建了金融知识图谱,并应用实体识别模型,如命名实体识别(ner),识别金融领域相关的实体;通过将知识图谱和实体识别应用于问答算法模型的训练和推理过程中,系统能够更准确地理解金融领域的专有名词、术语和实体,提升了问答系统在金融领域的准确性和效果。
67、e.一体化的系统生命周期管理平台:本发明设计并实现了一体化的系统生命周期管理平台,涵盖了模型的生成、测试、部署、监控和更新等环节;通过引入自动化的模型更新和版本控制机制,以及可视化的用户界面,本发明使得金融问答系统的管理更加便捷和高效;该平台结合图数据库的应用,提供高效的模型管理、知识查询和推理能力;这种创新的系统生命周期管理平台促进了系统的稳定性、可靠性和可扩展性。
- 还没有人留言评论。精彩留言会获得点赞!