一种基于多阶段增强框架的渐进式人脸超分辨率计算方法
本发明属于计算机视觉人脸超分辨率领域,具体涉及一种基于多阶段增强框架的渐进式人脸超分辨率计算方法。
背景技术:
1、智慧城市已成为城市管理中的重要趋势,基于监控视频识别个人身份信息是其关键基础。然而,由于成像环境和角度限制,捕获的面部图像通常具有有限的分辨率。面部超分辨率(fsr),也称为面部幻觉技术,可以从输入低分辨率(lr)图像(或多帧)重建出潜在高分辨率(hr)图像。fsr技术用于有效提高图像的分辨率和质量,这可以改善基于图像内容的视觉任务性能,例如人脸检测、人脸识别和视频监控,可以获得期望的结果。
2、基于卷积神经网络(cnn)的快速发展,各种基于深度学习的图像超分辨率(sr)方法已被提出,并获得了比传统浅层学习方法更优秀的主观和客观重建性能。dong等人首次将三层cnn引入到sr任务领域中,可以构建lr和hr图像之间的端到端映射。yu等人应用生成对抗网络(gan)进行fsr任务,以生成具有更高信息密度的重建图像,这也意味着更生动的视觉效果。随后,zhang等人引入了注意机制,进一步提高了神经网络的表示能力并增强了单幅图像sr性能。最近,kim等人提出了一种边缘和身份保护网络,利用轻量级边缘块和身份信息来最小化重建图像中的失真。此外,wang等人提出了一种新颖的多粒度金字塔注意力网络,充分利用多粒度感知和注意机制来增强重建图像质量。
3、yang等人引入了一种具有新颖感知损失函数的判别性增强生成对抗fsr框架,可以在保留训练梯度的同时重建面部细节。chen等人通过利用从粗糙sr图像提取的面部几何先验(如面部地标热力图和解析图),开发了一种端到端fsr方法,可以获得具有更清晰纹理的重建面部图像。考虑到诸如地标和组合映射等面部先验特征是从粗糙sr图像估计出来的,可能导致不准确性。为解决这个问题,ma等人提出了两个递归网络,分别协作迭代实现面部图像恢复和先验信息估计。jiang等人提出了一个双路径深度融合网络,不需要额外的面孔先验知识。相反,它通过两个单独分支学习全局脸形和局部脸组件。虽然这些方法已经显示出令人满意的表现,在没有精确先验信息情况下准确重建微小脸上身份信息仍然具有挑战性。
技术实现思路
1、本发明的目的在于,提供一种基于多阶段增强框架的渐进式人脸超分辨率计算方法,优化并且提高人脸超分辨率图像的保真度。
2、为解决上述技术问题,本发明的技术方案为:一种基于多阶段增强框架的渐进式人脸超分辨率计算方法,包括以下步骤:
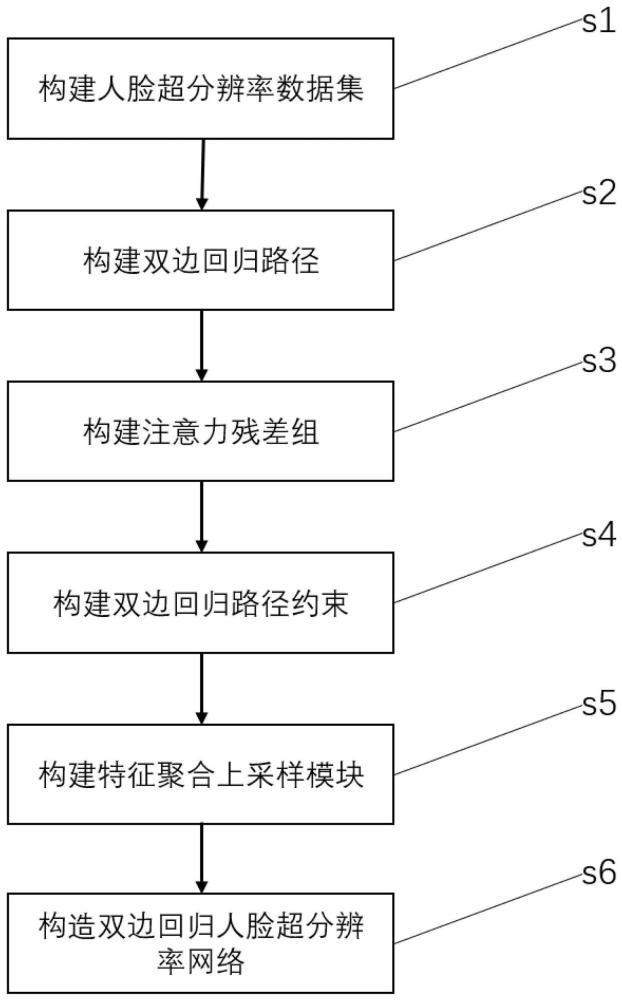
3、s1、构建人脸超分辨率数据集:对人脸高分辨率图像进行下采样得到低分辨率的目标图像,对目标图像进行分块操作得到分块图像,将分块图像统合形成人脸超分辨率数据集;
4、s2、构建双边回归路径:构建用于对低分辨率图像通过级联残差组学习形成超分辨率图像的先验信息分布的低分辨率图像lr至超分辨率图像sr回归路径lr->sr,构建用于探索超分辨率图像重建的特殊先验信息的超分辨率图像sr至低分辨率图像lr回归路径sr->lr;
5、s3、构建注意力残差组:将非池化通道注意力机制、非池化空间注意力机制和像素增强注意力机制均模块化后融合,形成特征融合模块affb,将若干个特征融合模块affb堆叠形成注意力残差组affg,用于提取分块图像中多个维度的特征以及扩展卷积层的视野;
6、s4、构建双边回归路径约束:根据l1范式约束,分别构建lr->sr中×2与×4累加的约束与sr->lr的×2与lr的约束,用于优化重建图像的效果;
7、s5、构建特征聚合上采样模块:构建像素打乱和亚像素卷积,通过自注意力聚集特征图中更多像素的特征以聚合图像的高频细节信息,再构建通道dropout与卷积,用于降低自注意力中冗余的细节信息,得到具有高频细节信息的超分辨率图像;
8、s6、构造双边回归人脸超分辨率网络:融合双边回归路径、注意力残差组和双边回归路径约束,形成双边回归人脸超分辨率网络,将分块图像输入双边回归人脸超分辨率网络中,输出人脸超分辨率图像。
9、s2中低分辨率图像lr至超分辨率图像sr回归路径lr->sr表示为:
10、
11、其中,为第i个特征图,i为执行次数,i∈{1,2…,n};haffg(·)表示为特征融合组,其包含若干个注意力特征融合模块affb;和分别表示为上采样操作和人脸超分辨率上采样尺度;
12、构建超分辨率图像sr至低分辨率图像lr回归路径sr->lr以限制低分辨率图像lr至超分辨率图像sr回归路径lr->sr的解空间,其表示为:
13、
14、其中,为人脸低分辨率图像,表示×2i倍的人脸重建图像,表示为leakyrelu激活函数;解释为人脸高分辨率图像经过卷积、leakyrelu和卷积下采样得到人脸低分辨率图像
15、s3中非池化通道注意力机制的计算公式表示为:
16、mcna=ζ(conv(δ(conv(xh×w×c))))
17、
18、其中,conv(·)为3×3卷积,ζ和δ分别表示为sigmoid和relu激活函数,xh×w×c表示为输入的张量,mcna为注意力分数图,fcna为非池化通道注意力输出的特征。
19、s3中非池化空间注意力机制的计算公式表示为:
20、
21、其中,fsna表示为非池化空间注意力输出的特征,表示为逐元素乘法,表示为1×1卷积,fgroup表示为分组卷积。
22、s4中结合l1范式约束,通过添加损失函数优化重建图像;其中,lr->sr的损失函数定义为:
23、
24、其中,llr→sr为lr->sr的损失函数,n表示为上采样因子,表示×2i倍的人脸重建图像,表示为与相同分辨率的高分辨率图像;
25、sr->lr的损失函数定义为:
26、
27、其中,lsr→lr表示为sr->lr回归路径的损失函数,是通过经过下采样生成的人脸低分辨率图像;
28、双边回归路径的损失函数ltotal表示为:
29、ltotal=llr→sr+λlsr→lr
30、其中,λ表示为损失函数参数。
31、s5中自注意力的计算公式为:
32、
33、其中,attention(q,k,v)表示为通过自注意力机制求得的注意力特征图;q为查询,k为键,v为值,均为经过像素打乱得到的特征;
34、softmax(·)为softmax函数,用于求出注意力分布得分,dl表示为通道数,t表示为转置。
35、s5中通道dropout与卷积公式为:
36、f(x)=dropout2d(conv(attention(q,k,v)))
37、其中,dropout2d(·)为通道dropout,f(x)为输出的高频信息图。
38、s1中下采样的方法为:通过双三次插值法对人脸数据集celeba、ffhq、lfw图片和bicubic进行下采样处理。
39、还提供一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一项所述方法的步骤。
40、还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一项所述方法的步骤。
41、与现有技术相比,本发明的有益效果为:
42、本发明通过设计一个双边回归回归网络来学习和指导面部细节关键像素的恢复;其次本发明设计了一个新的cna和sna,不包含池化层以避免面部结构信息的二次损失,并通过融合具有不同注意力的三个原始特征来指导面部图像重建。本发明在公共数据集上进行广泛实验能够显示出明显优于现有方法的优势。
- 还没有人留言评论。精彩留言会获得点赞!