基于跨模态语义与混合反事实训练的检索方法与流程
本发明涉及智能安防系统中的视频图像检索,尤其是一种基于跨模态语义与混合反事实训练的检索方法。
背景技术:
1、要获取多模态检索的组合表示,现有的方法主要依赖于全局语义和局部特征的跨模态交互和融合操作,或者依赖于参考图像和来自其相应编码器的查询文本的简单分离/级联特征学习方案。然而这种组合方式无法捕捉底层的信息特征和顶层的抽象语义之间的内在关系,从深层理解的角度来看:
2、(i)具有描述性短语但没有对查询进行全局语义理解的图像区域的详细局部特征。
3、(ii)抽象全局语义是从编码器的层次顺序中不断增加的抽象中学习到的,但缺乏植根于不同局部位置的具体属性。
4、简单地考虑上述特征利用率,而不对全局-局部组合进行适当建模,可能会导致解退化。
技术实现思路
1、本发明要解决的技术问题是提供一种基于跨模态语义与混合反事实训练的检索方法,能够解决现有技术的不足,提高图像检索准确度。
2、为解决上述技术问题,本发明所采取的技术方案如下。
3、一种基于跨模态语义与混合反事实训练的检索方法,包括以下步骤:
4、a、建立多颗粒的视觉表示模块和全局-局部文本嵌入模块,用于获取参考图像ir、目标图像it和不同层次的查询文本tq的特征表示;
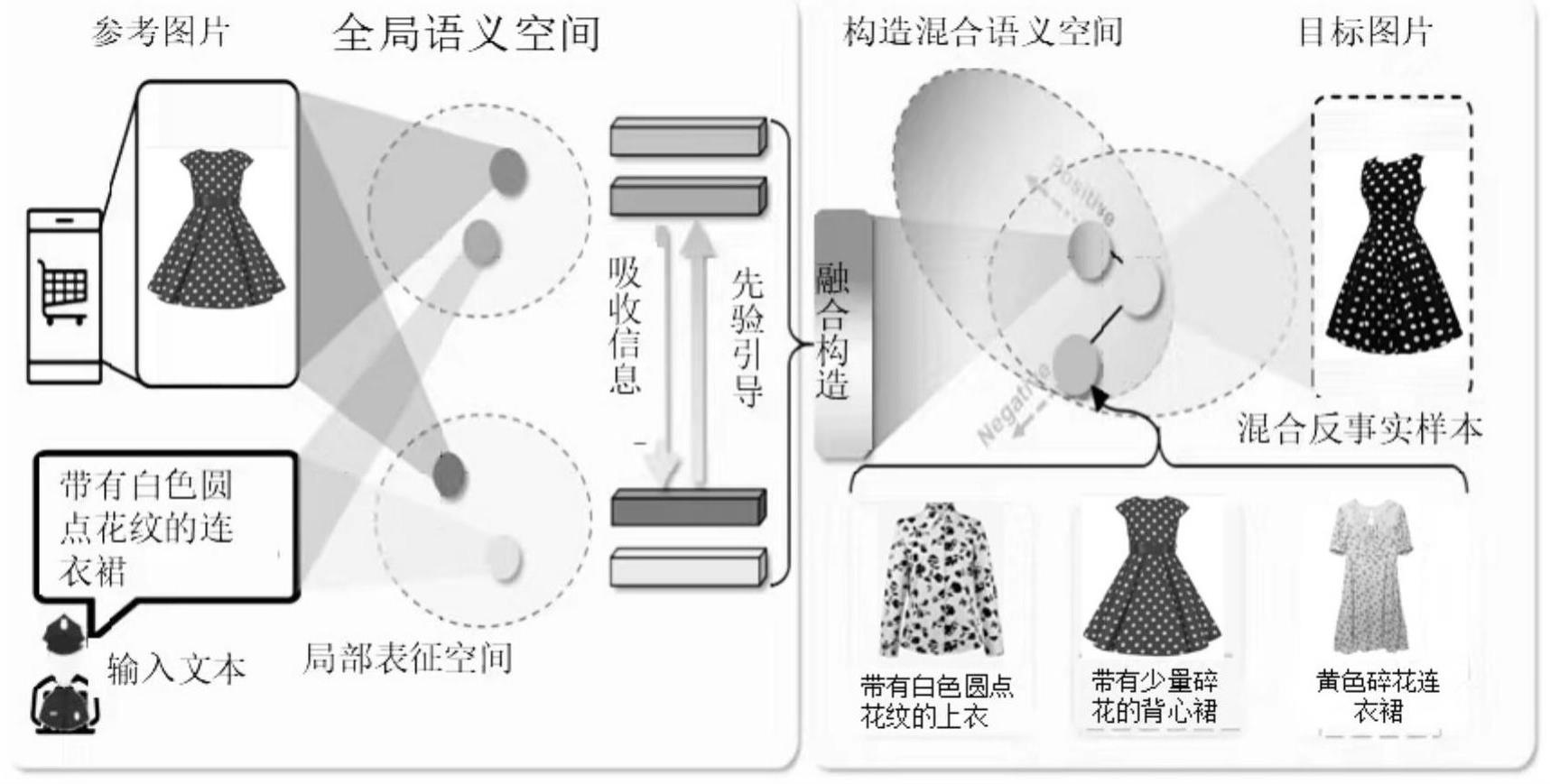
5、b、建立跨模态表征修改模块和表征吸收合成模块,构成自下向上的跨模态语义合成模块,在三级级联推理中对视觉语言表征进行建模;
6、c、构建混合反事实样本;
7、d、建立局部特征模块、全局-局部特征吸收模块和全局语义模块;利用表征吸收合成模块,对全局-局部组合进行建模,使设计的基于变换器的修改和吸收块能够从底层的局部特征到顶层的全局语义跨层捕获不同尺度、不同模态的局部-全局信息;从自下而上的分层组合中推导出的最终复合表示,根据文本修饰符的不同,捕获参考图像中的隐式视觉修改和保存;
8、e、学习匹配对m((ir,tq),it)多种模态的组合检索,再加入θ参数化激励,最后学习的图像文本复合表示与目标真值图像的视觉表示唯一对齐,如下式所示,
9、
10、其中,θ表示参数化激励,k(·,·)表示求相似度求解,φ(·)和ψ(·)分别为合成编码器和图像编码器;
11、f、使用损失函数对检索结果进行评判。
12、作为优选,步骤a中,
13、多颗粒视觉表示模块使用视觉转换器来生成图像视觉内容的判别表示;视觉转换器的浅层提取包含基本句法信息,深层的视觉转换器提取更复杂的语义信息,为进一步提高特征的质量,利用线性投影将提取的特征映射到全局语义表示;
14、全局局部文本嵌入模块使用bert将查询文本tq标记成m个子词标记序列,然后将特殊标记位置[cls]和[end]前置到文本子词标记序列中,将查询文本分为局部词嵌入和全局句子嵌入;对于局部词嵌入,第一层的词嵌入输出为随着bert的推进,上下文标记与自注意力交互是分多步进行,则bert最后一层表示给定文本中标记词嵌入的全局信息,将这些标记词嵌入表示连接起来形成全局句子嵌入
15、作为优选,步骤b中,
16、跨模态表征修改模块由一个自注意层、一个双向交叉注意层和一个软注意层组成;为了自我发现学习转换所必须的潜在区域到区域关系,将参考模态r的嵌入rr∈rnk×d和查询模态q的嵌入rq∈rmk×d,此模块学习以参考表征r和查询表征q为条件的组合嵌入,通过选择性抑制和突出查询模式获得的rr,从而实现对图像检索的学习更加有效,将以上输入到一个具有层归一化和残差链接的自注意层中,如下式所示,
17、
18、其中,ln和表示为层归一化和残差连接,psa表示金字塔池化注意力操作,msa表示多头自注意力操作,j(·)则判断输入是否为可视化模态函数v,自注意查询得到了参考和查询模态的自参与表示形式;
19、msa自注意力捕获了用于特征转换的非局部相关性,在自注意力的基础上,引入金字塔池化交叉注意力csa,通过层归一化和残差连接的双向交叉共关注,得到和如下式所示,
20、
21、
22、利用软注意力,对进行处理挖掘学习后的和在图像转换和保存方面的潜在关系,最终的交叉模态组成为:
23、
24、其中,soaq→r(·)是软注意力操作;
25、表征吸收合成模块包含一个自注意力层和一个残差注意层,按层次顺序构建;用于从局部特征空间吸收有意义的信息,然后创建一个信息组合,以增强后续查询目标匹配的鲁棒性;局部和全局级别的表征,分别为rl∈rnc×dc和rg∈rnc×dc,表征吸收合成模块实现从rl中吸收有意义和有区别的信息,这些信息作为rg生成合成表征的先验知识指导;吸收过程如下,
26、
27、在自注意建模之后,利用和生成中间嵌入,全局语义表示获得较高的权重,且作为组合生成的先验指导,然后通过残差注意力机制,知道需求方询问有意义的信息,如下式所示,
28、
29、其中,[·,·]表示串联运算,tl表示非线性变换;
30、融合嵌入进行残差连接的层归一化。并输入到前馈层,得到最终的吸收特征表示rac,这种组合表示rac从局部特征中吸收有用的知识,提高了查询匹配目标的精度,
31、
32、其中,
33、作为优选,步骤d中,
34、局部特征模块利用跨膜态表示修正模块在局部和学习局部特征组合
35、全局-局部特征吸收模块从局部特征组合吸收有意义和具有鉴别的信息,这些信息从局部特征层到对后续合成-目标匹配的鲁棒性起到事先指导作用,利用表征吸收合成模块推导全局-局部吸收组合的潜在嵌入;
36、全局语义组合模块从视觉域和语言域建模最终组合通过聚合中间表示的基本语义和查询文本全局语义潜在向量来更新该流的输出。
37、作为优选,步骤f中,损失函数由双向三元损失、重构损失和域对齐损失构成;
38、双向三元损失从二度提取的对比负样本中,构建输入查询和目标图像的细粒度查询-目标对应关系,确保组成的语义匹配和具有高相似度的目标表示,双向三元损失定义如下,
39、ltri(x,y,m)=max(0,||x+-y||2-||x--y||2+m)
40、lbid(cque,ctar,m,ma)=λqltri(cque,ctar,m)+λiltri(ctar,cque,ma)
41、其中,x+和x-为正样本和负样本,λq和λi为权重超参数,||·||2为l2距离,和sqt分别表示cque和ctar的语义相似度,α自适应边缘值ma的超参数,sqt接近0时,ma得最大值,否则为最小值,从而达到反事实训练的自适应效果;
42、重构损失lres约束了cque视觉和语言的映射,由rimg和rtext表示,分别与潜在嵌入ctar和对齐,目的通过重构规范和加强组合嵌入中文本和图像的平衡利用,
43、
44、其中,λimg和λtext为预训练超参数;
45、域对齐损失则是进一步学习组合域和目标图像域的细粒度语义对应关系,这里使用最优传输ot来对齐不同域的表示分布,以弥补他们之间的差距。首先计算合成域和目标域特征分布之间的代价矩阵cm,其次将每个特征以不同权重分类给来自另一个模态的特征,完成对应关系的预测,利用wasserstein distance将合成域和目标域对应,wasserstein distance和对齐损失如下式所示,
46、
47、lali=λawd(c,t)
48、采用上述技术方案所带来的有益效果在于:
49、(i)提出模态表征修改模块和表征吸收合成模块,隐式的自下而上语义合成建模。这一步的关键思想是,通过利用不同编码器层的互补全局局部表示,实现自下而上的视觉表示间的互补协同,从而达到有选择性的修改相关图像特征,并确保保留未更改的特征,这对于准确的检索方法至关重要。
50、(ii)一种即插即用的混合反事实训练策略(注:这里提出的是混合反事实而不是反事实)。该策略旨在促进检索模型构建细粒度的查询-目标对应关系,以实现鲁棒图像检索。该策略可作为一个即插即用组件,以提高检索模型的查询敏感能力。具体是构建图像独立、文本独立和上下文保存的三种新的不同类型的反事实样本。这种混合样本实现了明确的双向对应学习机制,有助于建立组合查询与期望图像的一对一匹配,降低了模型对相似查询的预测不确定性。
51、(iii)设计一种自下而上跨模态语义合成和分层组合推理,合并跨粒度语义更新学习和理解复合图像文本表示,从隐式自底向上的视觉表示合成和显式细粒度的查询目标结构相对应两个新的视角出发,逐渐消化来自视觉和语言的信息流,达到解决基于内容的图像检索的挑战性任务。该组合可以根据文本修饰符的不同,有效捕获隐含视觉修改和保存,从而达到优于现有图像检索技术的效果。
- 还没有人留言评论。精彩留言会获得点赞!