基于虚拟对象的视频生成方法、装置及电子设备与流程
本发明涉及智能交互,尤其涉及一种基于虚拟对象的视频生成方法、装置及电子设备。
背景技术:
1、虚拟对象是指通过计算机技术生成的数字化形象,例如可以是数字人、数字化动物或数字化卡通角色等。目前,包括虚拟主播、虚拟客服、虚拟医生、虚拟老师、虚拟法官、虚拟动漫人物和虚拟偶像等虚拟对象已在各行各业中得到推广和应用。虚拟对象的应用能切实提高行业的服务效率,降低服务的综合成本,并能提升服务体验以及增加服务时间等。
2、在实际应用中,用户与虚拟对象在进行交流互动时,虚拟对象的形象表达不尽如人意。例如,用户向虚拟对象输入信息后,虚拟对象响应于用户的输入信息,输出的语音和面部动画不同步,导致虚拟对象在表达时的逼真度较低。
技术实现思路
1、本发明提供一种基于虚拟对象的视频生成方法、装置及电子设备,用以解决现有技术中虚拟对象输出的语音和面部动画不同步,导致虚拟对象在表达时的逼真度较低的缺陷,实现提高虚拟形象在表达时的逼真度的目的。
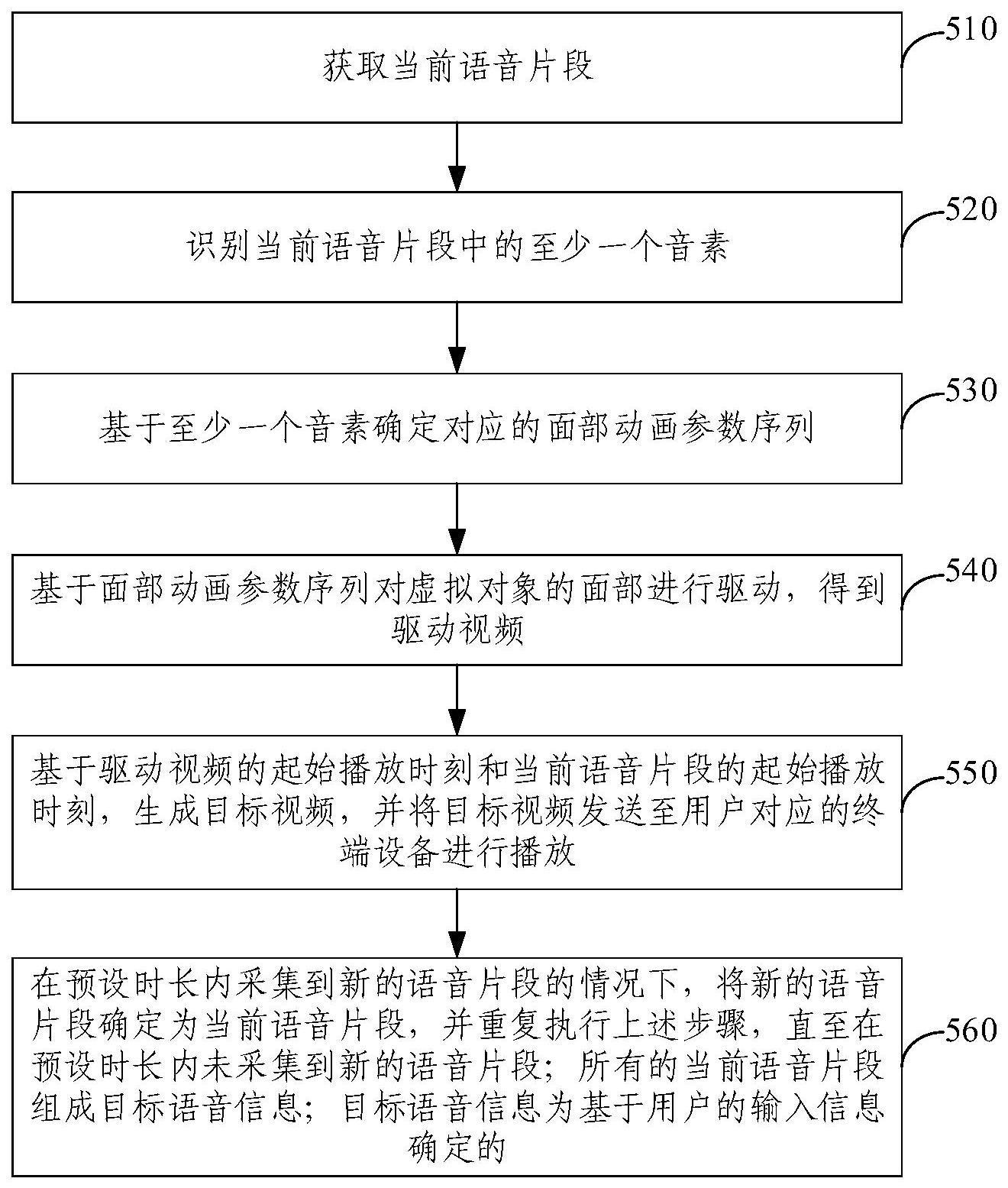
2、本发明提供一种基于虚拟对象的视频生成方法,包括:
3、获取当前语音片段;
4、识别所述当前语音片段中的至少一个音素;
5、基于所述至少一个音素确定对应的面部动画参数序列;
6、基于所述面部动画参数序列对所述虚拟对象的面部进行驱动,得到驱动视频;
7、基于所述驱动视频的起始播放时刻和所述当前语音片段的起始播放时刻,生成目标视频,并将所述目标视频发送至用户对应的终端设备进行播放;
8、在预设时长内采集到新的语音片段的情况下,将所述新的语音片段确定为所述当前语音片段,并重复执行上述步骤,直至在所述预设时长内未采集到新的语音片段;所有的所述当前语音片段组成目标语音信息;所述目标语音信息为基于所述用户的输入信息确定的。
9、根据本发明提供的一种基于虚拟对象的视频生成方法,所述方法还包括:
10、在基于渲染数据库从所述当前语音片段和所述当前语音片段之前的所有语音片段中,提取到至少一个目标关键词的情况下,确定所述目标关键词对应的目标渲染方式;所述渲染数据库中存储有关键词和渲染方式的对应关系;
11、基于所述目标渲染方式对所述虚拟对象的对应部位进行渲染。
12、根据本发明提供的一种基于虚拟对象的视频生成方法,所述基于所述面部动画参数序列对所述虚拟对象的面部进行驱动,包括:
13、对所述当前语音片段和所述当前语音片段之前的所有语音片段进行语义理解,得到语义理解结果;
14、基于所述语义理解结果确定情绪类型;
15、基于所述面部动画参数序列对所述虚拟对象的口唇进行驱动,并控制所述虚拟对象执行所述情绪类型对应的面部动作。
16、根据本发明提供的一种基于虚拟对象的视频生成方法,所述基于所述驱动视频的起始播放时刻和所述当前语音片段的起始播放时刻,生成目标视频,包括:
17、获取配置信息;所述配置信息中包括目标音色;
18、将所述当前语音片段中的音色替换为所述目标音色,得到目标语音片段;
19、基于所述驱动视频的起始播放时刻和所述目标语音片段的起始播放时刻,生成所述目标视频。
20、根据本发明提供的一种基于虚拟对象的视频生成方法,所述基于所述驱动视频的起始播放时刻和所述当前语音片段的起始播放时刻,生成目标视频,包括:
21、在所述用户的输入信息为方言语音信息的情况下,获取所述方言语音信息对应的目标方言类型;
22、将所述当前语音片段转换为所述目标方言类型对应的方言语音片段;
23、基于所述驱动视频的起始播放时刻和所述方言语音片段的起始播放时刻,生成所述目标视频。
24、根据本发明提供的一种基于虚拟对象的视频生成方法,所述目标语音信息为基于如下方式得到的:
25、将所述用户的输入信息输入至大语言模型中,得到所述大语言模型输出的所述输入信息对应的文本应答信息;
26、对所述文本应答信息进行语音转换,得到所述目标语音信息。
27、根据本发明提供的一种基于虚拟对象的视频生成方法,所述识别所述当前语音片段中的至少一个音素,包括:
28、对所述当前语音片段进行语义理解,得到语义文本;
29、将所述语义文本与敏感词库中的各敏感词进行匹配;
30、在匹配失败的情况下,识别所述当前语音片段中的至少一个音素。
31、本发明还提供一种基于虚拟对象的视频生成装置,包括:
32、获取单元,用于获取当前语音片段;
33、识别单元,用于识别所述当前语音片段中的至少一个音素;
34、确定单元,用于基于所述至少一个音素确定对应的面部动画参数序列;
35、驱动单元,用于基于所述面部动画参数序列对所述虚拟对象的面部进行驱动,得到驱动视频;
36、生成单元,用于基于所述驱动视频的起始播放时刻和所述当前语音片段的起始播放时刻,生成目标视频,并将所述目标视频发送至用户对应的终端设备进行播放;
37、所述确定单元,还用于在预设时长内采集到新的语音片段的情况下,将所述新的语音片段确定为所述当前语音片段,并重复执行上述步骤,直至在所述预设时长内未采集到新的语音片段;所有的所述当前语音片段组成目标语音信息;所述目标语音信息为基于所述用户的输入信息确定的。
38、本发明还提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述基于虚拟对象的视频生成方法。
39、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述基于虚拟对象的视频生成方法。
40、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述基于虚拟对象的视频生成方法。
41、本发明提供的基于虚拟对象的视频生成方法、装置及电子设备,该方法获取当前语音片段,并识别当前语音片段中的至少一个音素。基于至少一个音素确定对应的面部动画参数序列,基于面部动画参数序列对虚拟对象的面部进行驱动,得到驱动视频,该驱动视频中包括了虚拟对象的面部动画。基于该驱动视频的起始播放时刻和当前语音片段的起始播放时刻,生成目标视频,并将目标视频发送至用户对应的终端设备进行播放。该目标视频是基于驱动视频的起始播放时刻和当前语音片段的起始播放时刻生成的,因此,可以通过控制驱动视频的起始播放时刻和当前语音片段的起始播放时刻,对齐虚拟对象的面部动画和当前语音,使面部表情和语音同步,有效避免二者不同步的情况,能提高虚拟对象表达时的逼真度。另外,每当在采集到当前语音片段时,会基于该当前语音片段对应的音素确定面部动画参数序列,从而对虚拟对象的面部进行驱动,也即可以基于实时采集的语音片段对虚拟对象进行驱动,使得各个当前语音片段与面部动画均是同步的,能使虚拟对象表达时的逼真度得到提升。
- 还没有人留言评论。精彩留言会获得点赞!