基于视觉语义联合的染色体病例级异常提示系统的制作方法
本发明涉及医学人工智能,尤其涉及一种基于视觉语义联合的染色体病例级异常提示系统。
背景技术:
1、染色体核型分析(chromosome karyotyping)是一种用于检测人类染色体是否存在数目及结构异常的技术。然而一名患者的玻片拍摄出来的中期图就有数百张,并且质量参差不齐,一名患者需要分析至少30张中期图像来确定是否存在异常情况(数量异常,结构异常)。这个时候医生对于每一张中期图像都是未知的状态,及其容易出现误诊漏诊。为了减轻专业人员的负担,提高核型分析的效率,一种基于视觉语义联合的染色体病例级异常提示系统被提出,这款系统能够在医生分析之前就给患者病例做初步判断,方便医生具有针对性的分析对应图像。从而提高核型分析的准确性与效率。
2、目前染色体核型分析技术也已出现一些类似的染色体异常分析方法,主要有以下几种方法。
3、基于规则的方法:通过设定染色体长度、中心点位置等规则,判断染色体是否正常。这种方法对染色体结构清晰的图像效果较好,但规则设计困难,对图像效果较差的核型图效果不佳。
4、基于传统机器学习的方法:使用特征工程提取染色体形态、灰度等特征,输入分类模型中进行训练,判断染色体是否正常。这种方法对特征设计敏感,当图像复杂或者分辨率较差时效果较差。
5、基于深度学习的方法:使用卷积神经网络直接对染色体图像进行异常检测训练。这种方法对检测的异常类型局限性较大。具有特定性的,如9号倒位;der(13;15)罗氏易位。这种针对某种特定核型训练出来的检测模型,具有非常大的局限性,只能对于某一类的异常有点提示。因此一款即能病例上提示,又能中期图上提示;并且异常提示类别都不限制的系统更合理更有效。
技术实现思路
1、本发明的目的在于提供一种基于视觉语义联合的染色体病例级异常提示系统,该系统能够以单张中期图为单位进行病例级的异常提示,在系统中病例会有异常标识符号提示,表示此病例很可能是异常病例提醒医生重点关注,并且把对应的中期图也用个异常标识符号标记出来。简单的说就是一个病例的数据在经过分割识别后得到对应的核型图。然后将核型图自动输入至本发明的模型中,得到病例中每张核型图对应的异常信息,最后统计病例中异常信息数量是否满足我们设定的阈值,如若满足则抛出病例异常,并且在病例中显示,从而达到病例提示异常的功能。
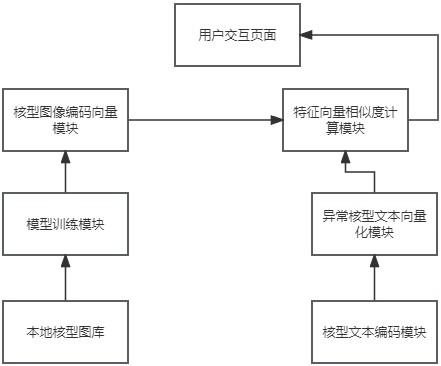
2、本技术提供了一种基于视觉语义联合的染色体病例级异常提示系统,包括:
3、核型图预处理模块,用于对输入的核型图进行染色体的分割,按类别分割,输出24张拼接位置编码的染色体图像;
4、模型离线训练模块,用于训练模型,多线程地调取本地核型图像数据库的数据,并在多块gpu上完成分布式训练;
5、核型图像编码向量模块,用于将染色体核型图编码成一个图像特征向量;
6、核型文本编码模块,用于将异常信息核型文本信息编码成文本特征向量;
7、异常核型文本向量化模块,用于将n种异常核型输入至文本编码器得到异常文本特征向量,构建成一个异常文本向量底库;
8、特征向量相似度计算模块,用于计算图像特征向量与异常文本向量底库的特征相似度计算,输出相似度最高并且判断是否达到设定的阈值,如果达到阈值则输出指定核型,否则不输出核型;
9、用户交互界面,用于显示特征向量相似度计算模块判断出的病例级别异常信息,以及病例中单张中期图的异常信息。
10、具体来说,核型图预处理模块,负责对输入的核型图进行染色体的分割,按类别输出24张分割后的染色体图像,计算全部染色体块的最大尺寸作为标准大小,对每张染色体图像进行255填充,使其达到标准大小,这里的标准大小定义为128*128;
11、核型图像编码向量模块,在整个流程中起到了 connect 视觉信息和语义信息的枢纽作用,借助模型强大的多模态表示能力,提取图像的高级语义特征;不同于单纯的像素级信息,这些语义特征聚焦在染色体的视觉模式上,并与语言概念关联;最后输出的编码向量充分融合了核型图像的视觉和语义信息;这些编码特征可以直接用于异常诊断,也可输入其它诊断模块以提升效果;
12、异常核型文本信息编码器,染色体核型文本库有正常的核型文本和异常核型文本,将n种异常核型文本信息输入至文本编码器得到特征向量,构建成异常文本向量底库;
13、特征向量相似度计算模块,通过计算重构染色体的特征向量与真实图像特征向量之间余弦相似度,核型图像编码向量与异常文本向量底库的向量进行相似度计算;
14、用户交互界面,用于显示病例级别异常信息,以及病例中单张中期图的异常信息,起到直接提示异常识别结果的作用,以及精确定位病例中那几张中期图出来了异常。
15、进一步地,所述核型图中染色体的分割是将染色体按照核型类别分割成块,再将每一块染色体图像的长边调整到标准长度128,然后计算短边的填充量,在短边两侧进行像素值255填充使其与长边128一致;填充公式如下:
16、;
17、式中,h表示标准长度128,h是需要填充的短边大小,pad_h表示短边两侧的填充量。
18、进一步地,所述的核型图预处理模块包括:先按照类别分割成1-22号、x、y染色体共计24个patch,经过线性映射得到24个向量,再给每个向量拼接一个用于记录向量位置的位置编码,然后将这24个向量输入至transformers encoder 编码器得到对应的图像编码向量。
19、进一步地,所述的线性映射是通过卷积、池化、激活操作,以及批量归一化,将24个128*128的patch转化为24个768维的向量。
20、进一步地,所述的批量归一化的调整过程如下:
21、 (1);
22、 (2);
23、 (3);
24、 (4);
25、式中, 为输入patch的均值,表示输入特征图,为patch的方差,为标准化处理后的值,为缩放参数,为平移参数,yi为每个patch归一化后的值,i=[1 2 3……24]。
26、进一步地,所述的本地核型图像数据库的数据来源于数百万张中期图标注了核型分析结果的数据,每张中期图对应一个核型信息文本。
27、进一步地,所述的核型信息文本通过文本编码器将核型文本信息分词,输入至核型编码器,得到核型文本向量;再与核型图像编码向量模块得到的图像编码向量进行对比学习,通过损失函数调整,使图像编码向量和核型文本向量趋向一致,损失函数如下:
28、;
29、式中,q表示图像编码器得到的向量,表示与q匹配的正确的文本向量,k指代的是数据集里类别的数量,而在对比学习里,这个k指的是负样本的数量,上式分母中的sum是在1个正样本和k个负样本上做的,从0到k,所以共k+1个样本,t表示一个超参数,是个标量这里默认值t=1,表示一个样本的损失值。
30、进一步地,所述异常文本向量底库的构建步骤为:预先制作了k+1种异常核型信息,通过标注得到的核型表达式,并将这k+1种核型信息,输入至训练好的bert文本编码器中,得到对应的核型信息的特征向量,最终建立一个向量数为k+1,向量长度为768的核型信息特征向量库。
31、进一步地,所述特征向量相似度计算的过程为:将一个核型图输入至图像编码器中得到一个特征向量q,接着拿到当前的特征向量q与异常文本向量底库的所有向量求余弦相似度,得到特征向量之间的余弦相似度d = [0,1],当d>threshold的时候,表示大于threshold的时候匹配出来的核型文本信息是可信的,小于threshold则反之,其中threshold为一个异常核型是否正确的阈值;相似度计算公式如下
32、;
33、式中,q为核型图特征向量,bj异常文本向量底库核型信息的特征向量。
34、进一步地,所述用户交互界面用箭头指向标识结构异常,圆圈标识数量异常,并对异常的细胞进行文本信息提示。
35、本发明的有益效果:
36、本发明直接输入核型图像无需考虑图像制片水平,更好的图像建模能力:并且根据核型图具有类别先验信息的特征按类别分块,可以更充分表示核型图的全局内容和局部关系;
37、本发明端到端训练:两者可以联合优化,文本编码器可以指导图像编码器学习关注重要特征,直接端到端检测数量异常和结构异常,方法简单有效;并且能够准确提示出哪一种异常;引入语义信息, 输出结果更符合临床表达习惯;
38、本发明解释性强:通过文本描述解释检测结果,能够知道一个病例中是那几张图像出现了疑似几号数量异常几号结构异常,能够让医生或者专业人员快速高效定位此病例是否真的出现的异常,提高可理解性;
39、本发明灵活通用:可以扩展应用到其它病理图像分类检测任务,加入更多模态信息,有利于模型迁移;
40、本发明易于优化:可以继续收集数据、调整模型架构等来迭代改进效果。
- 还没有人留言评论。精彩留言会获得点赞!