排放数据造假检测方法、装置及系统和存储介质与流程
本发明涉及环境监测与保护,特别是涉及一种排放数据造假检测方法、装置及系统和存储介质。
背景技术:
1、在线监测数据的造假与造假检测是一场攻防战。在企业现有的造假方法中,通常是基于基本的理化手段,或者是对在线数据进行篡改。
2、基于理化手段的造假,例如滤芯浸泡碱液、拔管抽空气等手段,往往有着更规律化的对应表征,识别方法相对更明确,例如视频识别等,在此不做阐述。
3、而篡改数据的手段,也即是本发明主要所针对的造假手段,过去通常以基于人工总结显著数据表征的方法和基于污染物原始数据建立bp神经网络的方法进行识别。在企业方运用一定的数理基础、造假手段升级以后,篡改数据的方法往往可以变得更不容易被察觉。
4、现有方法的说明及其不足:
5、1)基于人工总结显著数据表征的方法
6、在长久的工作中,经验丰富的工程师往往能察觉到企业数据中不合理的部分。其可被数学手段描述的规律,在被经验丰富的工程师总结出来以后,无疑可以通过自动识别的手段置入系统中。
7、这种方法主要的问题在于,极大地依赖工程师的人工经验,不可避免地有不稳定和不易描述的部分,而且人力物力消耗较大。
8、2)基于污染物原始数据建立bp神经网络的方法
9、具体指一种对污染物排放数据原始数据直接建立bp网络做回归模型的做法。
10、这种方法的主要问题在于,使用实时的污染源排污口各类分值作为输入来计算预测污染源分值和指标计算下的实际污染源分值,实际污染源分值和神经网络预测污染源分值,可能是依照同一个数学关系运作的,在二者有着共同的假输入的情况下,可能会有着近似的假输出。该方法使用bp神经网络建立回归模型,拟合的是各类分值映射到污染源分值的关系,在已有明确的映射关系的情况下,神经网络很可能也就是纯粹地拟合了“各类分值评估指标以传统计算方法得到实际污染源分值”的过程。在这批数据已经造假、也就是输入条件本身即是假的条件下,神经网络和传统的标准计算方法,未必能在判别造假这一点上拉开区别。
11、这个过程类似于一个用神经网络求解一元二次方程的过程,即使结构复杂,但最后参数矩阵如果训练得足够好、拟合得足够好,拟合的也只是那一个可以用简洁的初等函数表达的数学关系而已。反而如果模型结果与传统计算方法结果不同,很有可能是模型学习得不到位造成的,而不是真正识别到了造假。在模型描述一个更复杂的、通常被传统数学手段验证为难以表达为简洁的数学过程的关系时,神经网络才更能起到效果。
技术实现思路
1、提供了本发明以解决现有技术中存在的上述问题。因此,需要一种排放数据造假检测方法、装置及系统和存储介质,以至少解决如下问题:
2、1、基于人工总结显著数据表征的方法,极大地依赖工程师的人工经验,因此不可避免地有不稳定和不易描述的部分。也因此,人力、物力消耗更大、成本更高,更难以形成规范化、可推广、可复现的做法。
3、2、基于污染物原始数据建立bp神经网络的方法虽然脱离了上一种方法的误区,但是用模型描述的数学关系,在解决问题上存在一定误区。
4、本发明主要是在统计分析的方法和神经网络的方法上发展而来。
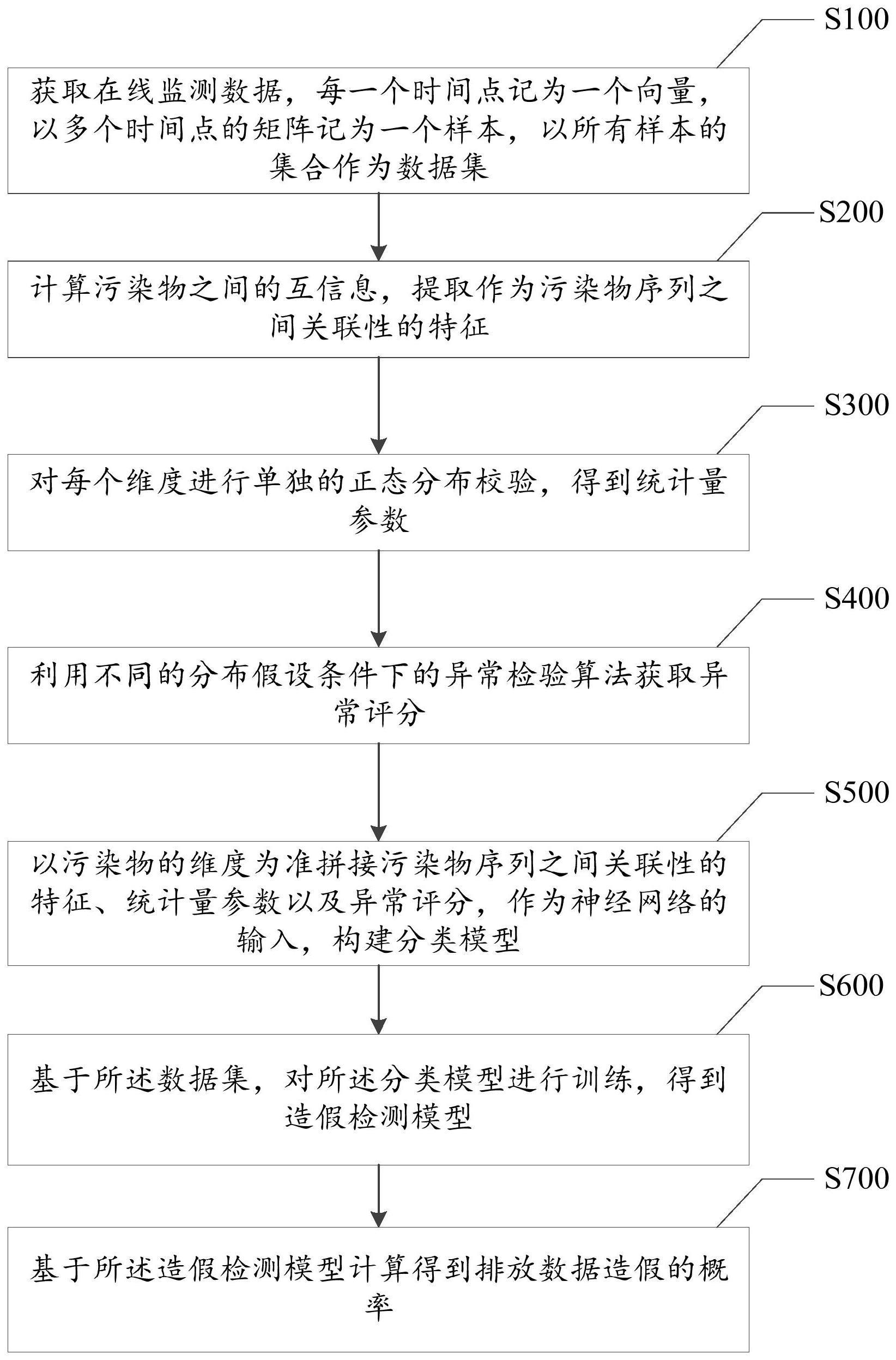
5、根据本发明的第一方案,提供了一种排放数据造假检测方法,所述方法包括:
6、获取在线监测数据,所述在线监测数据包括生产状态数据以及多种污染物的排放数据,每一个时间点记为一个向量z,z={z1,z2…zn},其中zn表示第n个污染物的排放数据,n为污染物的种类数量,以多个时间点的矩阵a记为一个样本,以所有样本的集合作为数据集;
7、计算污染物之间的互信息,提取作为污染物序列之间关联性的特征;
8、对每个维度进行单独的正态分布校验,得到统计量参数,所述维度对应每种污染物的多个时间点的序列;
9、利用不同的分布假设条件下的异常检验算法获取异常评分;
10、以污染物的维度为准拼接污染物序列之间关联性的特征、统计量参数以及异常评分,作为神经网络的输入,构建分类模型;
11、基于所述数据集,对所述分类模型进行训练,得到造假检测模型;
12、基于所述造假检测模型计算得到排放数据造假的概率。
13、进一步地,通过如下公式计算污染物之间的互信息:
14、
15、gain(t,x)=enrropy(t)-entropy(t,x)
16、其中,e(s)表示污染物的信息熵,i表示污染物的种类,c表示污染物的种类数量,pi表示第i个污染物的边际概率密度函数,gain(t,x)表示两个污染物之间的互信息,entropy(t)表示两个污染物中的一个污染物的信息熵,entropy(t,x)表示两个污染物中的另一个污染物的信息熵。
17、进一步地,所述对每个维度进行单独的正态分布校验,得到统计量参数,具体包括:
18、kolmogorov-smirnov检验,公式如下:
19、
20、其中,dn表示正态分布检验的统计量,sup表示一组距离中的上确界,x表示单种参与检验的污染物数据,fn(x)表示由x得到的实际分布的累积概率,f(x)表示要服从的理论分布的累积概率;
21、anderson-darling检验,公式如下:
22、
23、其中,z表示正态分布检验的统计量,n表示单种参与检验的污染物的数据量,w(x)表示权重函数,f(x)表示理论分布密度函数。
24、进一步地,所述利用不同的分布假设条件下的异常检验算法获取异常评分,具体包括:
25、对每个维度使用静态宽度直方图进行区间划分获取异常评分:
26、
27、在实际计算中,这个公式也会等价于如下公式:
28、
29、其中,hbos(p)表示histogram-based outlier score方法下计算出的异常评分,d表示单种参与计算的污染物的数据量,histi(p)表示直方图分箱归一化后的频率(相对数量);
30、通过马氏距离计算异常值获取异常评分:
31、
32、其中,表示mahalanobis距离测度,xi表示某一样本点的值,表示总体的均值;
33、利用二叉搜索树结构来迭代地计算推定为异常值的样本,计算异常值分数:
34、
35、其中
36、其中,ψ表示从x所属的数据集中抽取的数据的个数,c(ψ)表示在ψ个数据点下的平均高度,s(x,ψ)表示异常得分,h(ψ-1)是由(ψ-1)计算得到的谐波数(harmonic number),h(x)表示一个数据点x的高度即从树的根节点需要经历几条边才能到达叶子节点。
37、进一步地,对于以正态分布为假设前提条件、而数据检验又未能通过正态分布检验的,先经过正态分布变换再计算异常评分。
38、进一步地,所述分类模型包括self-attention结构、rnn结构以及luongattention结构,所述以污染物的维度为准拼接污染物序列之间关联性的特征、统计量参数以及异常评分,作为神经网络的输入,构建分类模型具体包括:
39、对所述污染物序列之间关联性的特征、统计量参数以及异常评分分别使用self-attention结构计算每个block的输出;
40、对多个self-attention的结果以逻辑关系构建含有先后次序的rnn结构计算输出;
41、以luong attention结构计算rnn结构的输入和输出的加权结果,经由两层隐含层的mlp结构计算每种污染物在对应序列中异常的概率。
42、进一步地,所述基于所述数据集,对所述分类模型进行训练,得到造假检测模型,具体包括:
43、从所述数据集中抽取预设比例的正样本,更改正样本中超过污染物标准的数值、使所述数值降低到离污染物标准较远的欧式距离,标记为负样本,生成的负样本与原始真实样本集作为总的数据集;
44、将所述总的数据集划分为训练集、测试集、验证集;
45、基于所述训练集和所述测试集,使用不同随机种子开启神经网络训练,每个随机种子下取训练效果最好的一个模型所对应的模型参数;所述训练效果根据测试集正确率来确定,所述测试集正确率是每种污染物计算出来的造假概率大于等于0.5计为预测造假,与真实标签相对比,得到的准确率;
46、以各个模型参数分别配置分类模型,通过验证集对比以验证集效果最好的一个模型作为造假检测模型。
47、根据本发明的第二技术方案,提供一种排放数据造假检测装置,所述装置包括:
48、数据获取模块,被配置为获取在线监测数据,所述在线监测数据包括生产状态数据以及多种污染物的排放数据,每一个时间点记为一个向量z,z={z1,z2…zn},其中zn表示第n个污染物的排放数据,n为污染物的种类数量,以多个时间点的矩阵a记为一个样本,以所有样本的集合作为数据集;
49、特征计算模块,被配置为计算污染物之间的互信息,提取作为污染物序列之间关联性的特征;
50、参数计算模块,被配置为对每个维度进行单独的正态分布校验,得到统计量参数,所述维度对应每种污染物的多个时间点的序列;
51、异常评分获取模块,被配置为利用不同的分布假设条件下的异常检验算法获取异常评分;
52、分类模型构建模块,被配置为以污染物的维度为准拼接污染物序列之间关联性的特征、统计量参数以及异常评分,作为神经网络的输入,构建分类模型;
53、模型训练模块,被配置为基于所述数据集,对所述分类模型进行训练,得到造假检测模型;
54、造假检测模块,被配置为基于所述造假检测模型计算得到排放数据造假的概率。
55、根据本发明的第三技术方案,提供一种排放数据造假检测系统,所述系统包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序以实现如上所述的方法。
56、根据本发明的第四技术方案,提供一种存储有指令的非暂时性计算机可读存储介质,当所述指令由处理器执行时,执行如上所述的方法。
57、根据本发明各个方案的排放数据造假检测方法、装置及系统和存储介质,其至少具有以下技术效果:
58、由于本发明综基于多种异常分布的结果进行二次建模,具备多种优势。首先,本发明考虑到了多种统计学假设前提条件,对实际使用中不同的数据分布情况具备适应性。其次,本方法使用深度学习模型描述的是一个复杂数学关系,企业很难找到对抗这个数学关系的数据生成方法。此外,这项方法在推理阶段是可以部署在服务器上、连接数据库自动运行的,仅需要少量人力、物力。
- 还没有人留言评论。精彩留言会获得点赞!