一种基于人工智能的数据分析治理系统及其方法与流程
本发明涉及智能数据分析,更具体地说,本发明涉及一种基于人工智能的数据分析治理系统及其方法。
背景技术:
1、随着数据量的不断地增加和数据类型不断的增多,数据分析已经成为组织决策和业务增长的关键因素,然而数据分析中存在着数据质量、数据安全,以及数据隐私问题,这些问题需要得到有效的治理和管理,同时,人工智能技术的发展使得其可以更好地应用于数据分析领域,提高数据分析的效率和准确性,因此,基于人工智能的数据分析系统及方法成为一种重要的技术手段。
技术实现思路
1、为了克服现有技术的上述缺陷,本发明的实施例提供一种基于人工智能的数据分析治理系统及其方法,通过智能数据分析,以解决上述背景技术中提出的问题。
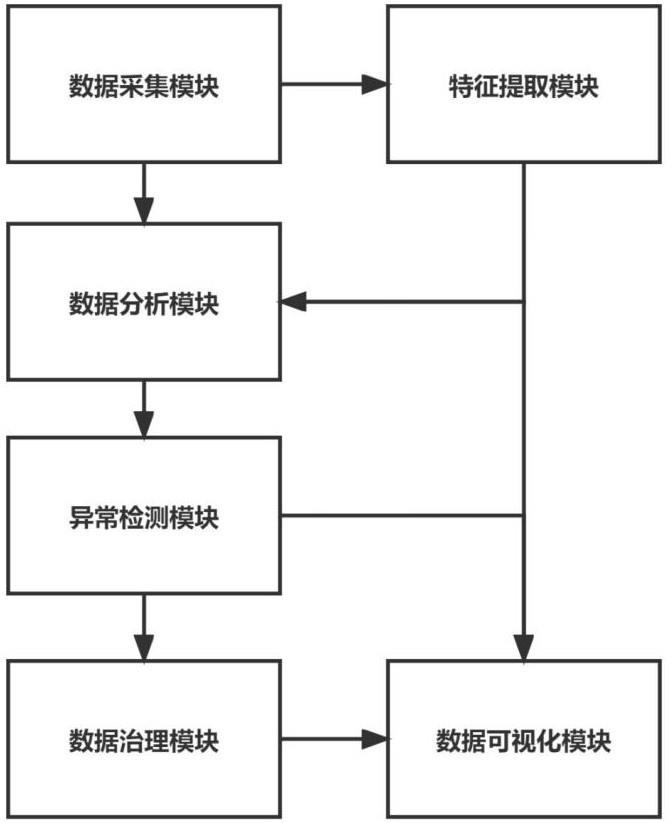
2、为实现上述目的,本发明提供如下技术方案:一种基于人工智能的数据分析治理系统,包括:
3、数据采集模块:用于从多种数据源中采集目标数据,并对目标数据进行清洗和预处理,得到处理之后的目标数据;
4、特征提取模块:利用机器学习和深度学习算法自动提取处理后的目标数据,得到目标数据的有效特征,将有效特征作为目标数据的标签,完成有效数据的特征标记;
5、数据分析模块:通过深度学习算法对完成特征标记的目标数据进行分类,并通过回归技术对分类后的目标数据进行多分类;
6、异常检测模块:通过学习分类后的目标数据的历史记录和行为规律,检测出目标数据的异常波动;
7、数据治理模块:根据目标数据分析结果和异常情况,制定相应的治理策略和措施,包括目标数据质量改进和风险控制;
8、数据可视化模块:提供一个界面,通过该界面将针对目标数据制定的治理策略和措施通过显示屏进行显示,同时提供询问窗口,用户可通过移动端进行询问和查看。
9、作为本发明的进一步改进,所述数据采集模块中的多种数据源包括数据库、文件系统、wep api、lot设备、社交媒体,以及第三方数据供应商。
10、作为本发明的进一步改进,所述数据采集模块对数据进行清洗和预处理,具体的处理步骤为:
11、s1、数据去重:将从多种数据源中提取到的目标数据通过数据清洗工具自定义删除重复性数据;
12、s2、数据过滤:根据预设的规则要求或条件,过滤掉不符合要求的数据,去除缺失值或异常值;
13、s3、数据修正:对于和预设数据不匹配的目标数据,通过数据补全和数据归一化对目标数据进行目标数据修正;
14、s4、数据标准化:对于具有一定范围和分布的数据,通过数学计算将目标数据转化为均值为、标准差为1的标准正态分布;
15、s5、数据转换:根据预设的具体要求,进行目标数据类型转换或特征提取,得到有效目标数据。
16、作为本发明的进一步改进,所述特征提取模块通过深度学习算法中的卷积神经网络构造对提取目标数据进行分类,具体的方式为:
17、将从多个数据源中提取的目标数据图像作为输出样本,通过逐层前向传播,直至输出层输出最终的分类结果,将一幅图像作为输入资料,用6个滤光片在第一卷积层卷积,生成6张特征图,称为c1图像,该6个特征图像是由多个滤波片对输入图像进行卷积得到的图像,所述特征提取模块利用最大池子抽样技术,在s2层上引入2×2尺度滤波,通过对图像的不断抽取与采集,所述图像中的噪声、遮挡、残缺影响将逐步减弱,卷积神经网络一直重复着卷积和下采样操作,直到获得c5层,输入图像被退化为120个单像素大小的特征图像,将120个单像素大小的特征图像与输出层的10个节点以全连接的方式相连,通过分类器将图像进行分类。
18、作为本发明的进一步改进,所述数据分析模块采用回归技术解决多分类问题,具体的方式为:
19、将从多个数据源中提取的目标数据图像中的数据信息作为训练样本,设训练样本集由n个带标签的样本构成,{(),,……,()},类标y取k个不同的值,k>2,对于训练集{(),,……,()}有;
20、针对训练样本x,利用假定函数估计每个类 j的概率,这就是对样本x被划分到每个类别的可能性的估算,所以,假定该函数将会输出一个 k维的矢量,以代表这 k个估算的可能性,矢量元的总和是1,因此假定函数可以被表示为:
21、 ==
22、其中是模型参数,是为了对概率分布进行归一化处理;
23、在回归技术中将样本x分类为类别j的概率为:
24、p()=;通过所述公式输出模型预测结果,对目标数据进行类别的分类。
25、作为本发明的进一步改进,所述异常检测模块通过三倍标准差判别法对目标数据异常波动的检测,具体的检测方式为:
26、将目标样本数据按照从大到小的顺序进行排列编号,记为,通过计算两个数据点之间的绝对值,得到每个数据点之间的距离,通过公式得出目标样本数据的平均值,设目标样本数据的平均值为y,所以目标样本数据的标准差为;其中y为目标样本数据排序后的平均值,n是目标样本数据的数量,由上述公式可知三倍标准差为3y;
27、如果目标样本数据在平均值的正负一倍标准差范围之外,并且在两倍标准差的范围内波动,则视为正常波动,如果目标样本数据在平均值的正负两倍标准差范围之外,并且三倍标准差范围之外,则视为异常波动数据,如果目标样本数据在平均值的正负三倍标准差范围之外,则视为中度异常波动数据。
28、作为本发明的进一步改进,所述数据治理模块对目标数据进行质量改进的方式为:
29、通过数据分析模块对目标数据进行二次分析,找出目标数据所包含的异常情况,根据找出的目标数据异常情况,确定目标数据质量改进的目标,根据确定的目标数据质量改进的目标,制定相应的目标数据质量改进措施,并实施对目标数据的数据清洗、数据校验、数据更新,以及数据备份和储存,同时对目标数据的质量改进措施进行监控和评估,在目标数据质量改进过程中,考虑目标数据可能存在的风险,并制定相应的风险控制措施;
30、所述对改进后的目标数据进行质量评估,具体的方式为:
31、设改进后的目标数据的质量系数为,预设的标准目标数据的质量系数为,将其代入损失函数公式:
32、g(,)=-log()-(1-)log(1-);
33、其中g为损失函数,损失函数越小,则表明所述改进后的目标数据的有效率高;
34、g(,)=;
35、当g(,)=1时,所述数据治理模块判断该目标数据为风险数据,并制定相应的风险控制措施。
36、作为本发明的进一步改进,所述数据可视化模块中用户通过显示屏查看目标数据:
37、用户通过手机移动端、电脑,以及平板电脑查看目标数据,用户可通过关键词对目标数据进行搜索,所述数据可视化模块提供用户自定义界面,用户根据自己的需求查找想要了解的目标数据,所述数据可视化模块提供ai智能服务,当用户无法获得对目标数据的进一步解释时,通过点击ai智能服务按钮,获得ai智能客服的在线回复,所述数据可视化模块通过文字和图像相结合的方式展示目标数据。
38、为实现上述目的,本发明提供如下技术方案:一种基于人工智能的数据分析处理系统及其方法,使用上述的一种基于人工智能的数据分析治理系统,包括以下步骤:
39、s101、数据采集模块通过从数据库、文件系统、wep api、lot设备、社交媒体,以及第三方数据供应商获取目标数据;
40、s102、所述数据采集模块对获取的目标数据通过数据清洗工具进行数据清洗,根据预设的规则要求或条件,过滤掉不符合要求的数据,对于和预设数据不匹配的目标数据,通过数据补全和数据归一化对目标数据进行目标数据修正,对于具有一定范围和分布的数据;
41、s103、通过统计学和机器学习方法对具有有效特征的目标数据进行综合分析,得到分析之后的目标数据,并对目标数据进行分类;
42、s104、将目标样本数据按照从大到小的顺序进行排列编号,通过计算两个数据点之间的绝对值,得到每个数据点之间的距离,通过公式得出目标样本数据的平均值,进而得出三倍标准差,通过三倍标准差判别法对目标数据异常值的检测;
43、s105、通过数据分析模块对目标数据进行二次分析,找出目标数据所包含的异常情况,根据找出的目标数据异常情况,确定目标数据质量改进的目标,并改进,同时对目标数据的改进措施进行监控和评估;
44、s106、用户可通过关键词对目标数据进行搜索,根据用户自己的需求查找想要了解的目标数据。
45、本发明的技术效果和优点:
46、1、自动化数据分析:通过机器学习和自然语言处理技术,自动分析数据并生成数据报告,实现智能化的数据治理,减少数据分析的工作量,提高数据分析的效率。
47、2、实时监测和预测:该系统可以对大量的数据进行实时监测和分析,帮助企业及时发现问题和机会,并提供预测性的决策和支持,通过对历史数据的分析,预测未来的趋势和风险。
48、3、自动化报告生成:基于人工智能的数据分析治理系统可以根据用户需求自动生成各类报告和可视化图表,简化了人工报告的编制过程,提高了工作效率。
- 还没有人留言评论。精彩留言会获得点赞!