一种基于HER和ICM实现的改进DDPG策略方法
本发明涉及深度学习,具体涉及基于her和icm实现的改进ddpg策略方法。
背景技术:
1、深度强化学习在游戏、机器人控制、自动驾驶、金融、资源管理、自然语言处理和医疗等领域有着广泛的应用。深度强化学习实现的策略方法有助于提升智能体的自主决策能力、适应性和学习能力,实现高级策略和复杂行为,解决稀疏奖励问题,并支持多智能体协作。
2、申请公布号为cn116533249a的专利文献公开了一种基于深度强化学习ddpg的机械臂控制方法,申请公布号为cn116321057a的专利文献公开了一种基于深度强化学习ddpg的车辆群智感知用户招募方法。上述的深度强化学习算法,在某些方面存在一些不完善之处:
3、1)稀疏奖励问题的挑战:在许多情况下,智能体只有在达到目标或完成任务时才接收到正向奖励信号,而在其他时间步上接收到的奖励信号较少或为零;
4、2)探索效率低的问题:在许多情况下,环境中存在大量未知的状态和动作组合,但传统的奖励信号可能无法有效引导智能体去探索这些未知领域。这使得智能体难以有效地发现新的、有价值的信息。
5、因此提出一种基于her和icm实现的改进ddpg策略方法,从经验样本和探索方案入手,针对ddpg存在的上述问题进行优化。
技术实现思路
1、本发明的目的是为了解决传统ddpg算法存在的奖励稀疏导致智能体学习缓慢和探索效率过低导致样本覆盖面窄的技术问题,而提出的一种基于her和icm实现的改进ddpg策略方法。
2、为了解决上述技术问题,本发明采用的技术方案如下:
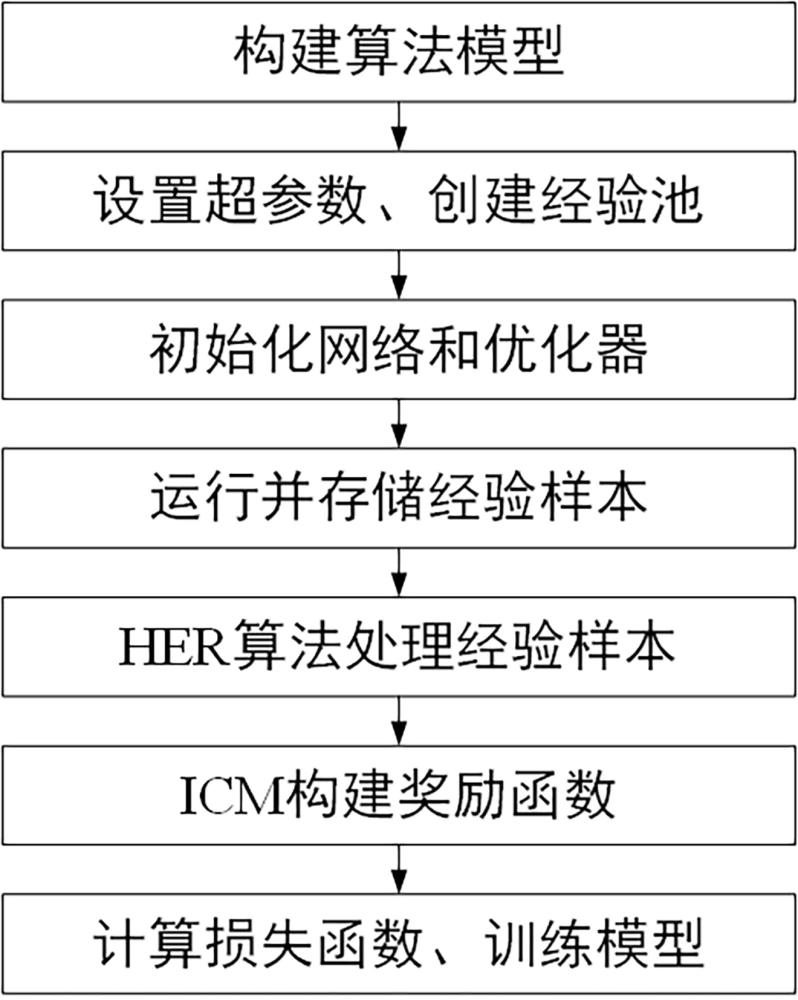
3、一种基于her和icm实现的改进ddpg策略方法,它包括以下步骤:
4、步骤1)创建实验环境并构建ddpg、her和icm的模型;
5、步骤2)设置训练参数并创建经验池;
6、步骤3)初始化网络和优化器;
7、步骤4)模型在环境中运行训练,并存储状态、动作和奖励等信息到经验池中;
8、步骤5)使用her算法处理经验池中的样本生成新的样本;
9、步骤6)使用icm计算奖励并整合奖励;
10、步骤7)计算损失函数,使用梯度下降法更新网络参数训练模型;
11、通过以上步骤实现ddpg策略。
12、在步骤1)中,具体包括以下步骤:
13、1-1)构建基础算法ddpg模型,其中包括critic网络、actor网络和学习函数;critic网络用于估计状态-动作的q值,提供动作的价值信息;actor网络用于根据状态选择动作,优化策略以获得最大累积奖励;
14、critic网络、actor网络通过三层全连接层进行构建,全连接层的计算如式(1)所示:
15、ai=fi(wi×ai-1+bi) (1)
16、其中,ai表示第i层的激活输出结果,fi是第i层的激活函数,wi是第i层的权重矩阵,ai-1是第i-1层的输出结果,bi是第i层的偏置向量;
17、1-2)构建icm网络模型,包括前向模型和逆向模型;前向模型通过状态和动作预测下一状态,逆向模型通过状态和下一状态预测执行的动作;前向模型和逆向模型的网络部分同样根据全连接进行构建;
18、前向模型的计算如式(2)所示:
19、
20、其中,f为前向网络模型,st为当前观测状态,at为当前的动作,f(st,at)表示前向模型的输出,为预测的下一个状态;
21、逆向模型的计算如式(3)所示:
22、
23、其中,g为逆向网络模型,st为当前观测状态,st+1为下一状态,g(st,st+1)表示逆向模型的输出,为预测的动作;
24、1-3)构建her算法所需计算函数,包括重新计算奖励函数如式(4)所示、新目标产生函数。
25、在步骤2)中,具体包括以下步骤:
26、2-1)设置超参数,包括训练轮数、每轮步数、学习样本大小、学习率、经验池大小、her新目标数目;训练轮数为游戏运行次数;每轮步数为每次游戏运行最长步长,若步数耗尽游戏还未结束则强制结束,判定为失败;学习样本大小为每次学习时抽取经验样本数量;学习率为学习效率;经验池大小为经验池可存放经验样本数量,样本数量满了释放早期经验样本,先进先出;her新目标数目为需要选取的新目标个数,用于新经验样本的奖励计算;
27、2-2)创建经验池用于存储当前状态、奖励、动作、下一状态、终止信息;经验池分为总经验池和临时经验池,总经验池用于存储所有经验样本,临时经验池用于存储每一轮的经验样本组用于her算法计算,每轮结束清空临时经验池。
28、在步骤4)中,具体包括以下步骤:
29、4-1)重置实验环境,训练开始前重置环境参数和临时经验池;
30、4-2)通过ddpg选择动作,智能体在环境中按照得到的动作运行,将运行得到的下一状态、动作、奖励、是否结束和当前状态信息存入经验池中。
31、在步骤5)中,具体包括以下步骤:
32、5-1)her算法通过从每轮临时经验池的末尾经验样本中随机选取几例经验的状态作为新目标;
33、5-2)临时经验池中的每一条经验根据新目标和奖励函数重新计算奖励,将重新计算的奖励替换掉初始经验样本中的奖励值后得到新的经验样本,并将新经验样本存入经验池中;算法结构如图2;重新计算奖励的计算如式(4)所示:
34、r(st,at,sg)=r+λ(-α·distance(st,sg)) (4)
35、其中,当前状态为st,执行的动作为at,目标状态为sg.distance表示状态之间的欧几里德距离,α是一个正系数,用于调整虚拟奖励的幅度,通常情况下,α的值需要根据问题的特性进行调整,r表示初始经验样本中的奖励值,λ表示影响因子,r(st,at,sg)表示重新计算后的奖励值。
36、在步骤6)中,具体包括以下步骤:
37、6-1)icm算法结构如图3,当经验池中的经验数据的数量达到设定数额开始训练,提取经验池中的经验,icm算法的前向模型根据经验数据中的状态和动作,预测出下一状态;
38、6-2)对预测的下一状态和经验数据中的下一状态计算得到预测loss;
39、6-3)根据loss计算得到icm_reward,icm_reward的计算如式(5)所示:
40、
41、其中,ricm表示icm内在奖励,||…||2表示向量的平方范数,表示预测的下一个状态,st+1表示下一个状态;表示预测的动作,at表示经验样本中的动作;β,(1-β)分别代表前向模型和逆向模型的影响因子;
42、将icm_reward加入到经验样本的reward中得到最终训练用reward,最终奖励值的计算如式(6)所示:
43、r=rexp+σ·ricm (6)
44、其中,r表示最终训练用reward,rexp表示经验样本中的reward,ricm表示icm的内在奖励,σ为超参数,控制内在奖励的影响因子。
45、在步骤7)中,具体包括以下步骤:
46、7-1)计算critic网络的均方误差损失,损失函数的计算如式(7)所示:
47、
48、其中,q(s,a;θ)为当前状态s下采取动作a的q值,由神经网络参数θ计算得到,r为式(6)计算得到的奖励值,γ是折扣因子,用于衡量未来奖励的重要性,s′是执行动作a后的新状态,θ~是目标网络的参数,用于计算目标状态s′下的q值,在训练过程中,通过最小化损失函数来更新神经网络的参数θ,使得q值逐渐逼近最优的q值函数;
49、7-2)计算actor网络的策略梯度损失,损失函数的计算如式(8)所示;
50、
51、其中,n是批次大小,si是状态,μ(si)是actor网络在状态si时选择的动作,q(si,μ(si)是critic网络对于状态si和actor网络选取的动作的预测值,通过计算这两个部分的损失,ddpg算法将会分别更新critic网络和actor网络的参数,以使得critic网络的值函数逼近真实回报,actor网络的策略逐步改进以获得更高的累积回报,在训练过程中,网络参数会根据损失函数的梯度方向进行微小的调整,以达到优化的目标。
52、与现有技术相比,本发明具有如下技术效果:
53、1)本发明使用her算法通过事后经验回放技术将失败的经验转换为价值更高的训练信号。引入事后经验回放技巧,旨在将未能达到的目标状态替换为已达到的状态,从而将失败的经验转化为有用的训练信号,加速学习过程。该方法在每个训练回合中,不仅使用当前目标状态,还使用替代目标状态进行训练,有助于智能体学习更多策略以适应环境变化。
54、2)本发明使用icm算法通过内在好奇心模块提高模型的探索效率。icm算法引入“内在好奇心模块”,根据当前观测状态和动作预测下一个状态并与实际状态比较,从而激发智能体的主动探索。
55、这些方法共同提升了学习效率,使智能体更好地应对复杂情境和未知环境。
- 还没有人留言评论。精彩留言会获得点赞!