一种基于UMAP数据降维的相似度度量迁移学习方法
本发明涉及机械加工,具体一种基于umap数据降维的相似度度量迁移学习方法。
背景技术:
1、镍基高温合金在高温下具有良好的抗氧化、抗腐蚀、抗蠕变性能以及优异的疲劳寿命,适合作为整体涡轮盘材料。然而,良好的物理、机械性能意味着较差的切削加工性能,镍基高温合金切削过程中切削力大、加工表面质量不高、刀具磨损快,刀具在加工过程中到达磨钝标准会导致整体涡轮盘加工精度不足,甚至报废。
2、为了防止刀具在加工过程中到达磨钝标准,传统方法是在刀具到达使用寿命前提前让机床停机并进行换刀,这种方法会导致刀具浪费严重,刀具平均使用寿命为刀具寿命的50%~80%。
3、通过光学图像法或人工判断法监测刀具磨损状态需要对机床停机操作,违背了自动化、无人化的智能制造理念,且耗费大量人力和时间。人工智能的出现,推动了刀具磨损实时监测的发展,通过人工神经网络、支持向量机、隐马尔科夫构建的刀具监测模型逐渐应用于实际加工中。
4、然而,在新工艺条件下,基于原有工艺条件下的数据建立的预测模型准确度降低,模型失效,而重新训练预测模型则缺乏足够的带标签样本。
技术实现思路
1、本发明的目的是为了提供一种基于umap(uniform manifold approximation andprojection)数据降维的相似度度量迁移学习方法,采用迁移学习方法,构建新的损失函数评价目标域与源域之间的分布差异,从而实现预测模型在新工艺条件下的复用。
2、为实现上述技术目的,本发明采取的技术方案为:
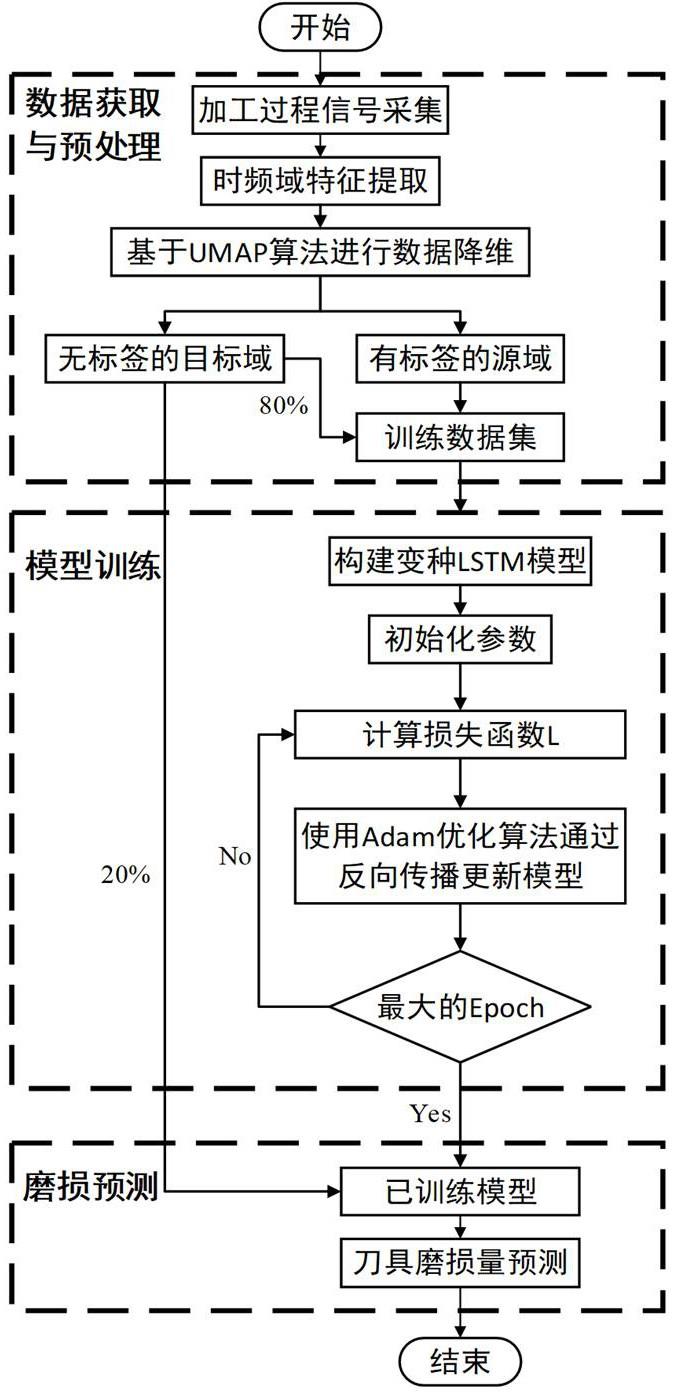
3、一种基于umap数据降维的相似度度量迁移学习方法,所述相似度度量迁移学习方法包括以下步骤:
4、s1,采集四种不同工况下的包括铣削加工电流和振动信号在内的加工过程信号;四种不同工况包括源工况和三种变工况;通过三维视频显微镜采集源工况下不同加工过程信号对应的刀具磨损量;
5、s2,对四种不同工况的加工过程信号进行数据清洗,将清洗后的加工过程信号进行时域特征、频域特征以及小波分解的时频域信号特征提取,再对提取的数据特征进行降维;源工况降维后的特征向量与其对应的刀具磨损量构成有标签的源域;三种变工况降维后的特征向量构成无标签的目标域;
6、s3,将无标签的目标域分成两部分,其中一部分无标签的目标域与有标签的源域构成训练数据集,导入相似度迁移学习模型中进行训练,得到训练完成的刀具磨损量预测模型;将另一部分的无标签的目标域导入训练完成的刀具磨损量预测模型,预测得到刀具磨损量。
7、进一步地,步骤s1中,三种变工况包括变切削速度工况、变进给量工况和变切深工况。
8、进一步地,步骤s2中,令采集得到的源工况下的刀具磨损量为,对加工过程信号中的无效值和异常值进行清洗;将清洗后的加工过程信号进行时域特征、频域特征以及小波分解的时频域信号特征提取,提取出第i个加工过程信号的m个特征构成特征向量,n个样本构成特征向量集合,对x进行降维得到特征向量集合;
9、降维过程具体包括:
10、s21,设计条件概率函数以描述高维样本点、两两之间的分布关系:
11、
12、其中,为特征向量到首个最近邻特征向量的距离,是特征向量最近邻特征向量的直径,表示特征向量与特征向量之间的欧式距离;;
13、s22,构建条件概率函数来描述低维样本点两两之间的分布关系:
14、
15、其中,和均为超参数,通过调节和以调整映射后低维数据的聚拢程度;
16、s23,对条件概率函数和条件概率函数进行对称化处理:
17、;
18、;
19、式中,和分别为给定条件 i和 j下,x和y事件发生的概率;
20、s24,构造损失函数二进制交叉熵,通过梯度下降法求解的最小值,令高维样本点之间的关系和低维样本点之间的关系趋近相似,得到降维后的特征向量集合,其中向量y的维度小于m;损失函数二进制交叉熵的公式为:
21、。
22、进一步地,步骤s2中,源工况降维后的特征向量与其对应的刀具磨损量构成有标签的源域;三种变工况降维后的特征向量分别构成无标签的目标域:、以及;
23、式中,和分别为源工况条件下的第i个加工过程信号对应的降维后的特征向量以及相应的刀具磨损量;为源工况条件下的采样总数;、和分别为三种变工况条件下的第i个加工过程信号对应的降维后的特征向量;、和分别为三种变工况条件下的采样总数。
24、进一步地,步骤s3中,所述相似度迁移学习模型基于变体lstm模型构建得到;
25、所述变体lstm模型的遗忘门的计算公式为:
26、;
27、所述变体lstm模型的增加门的计算公式为:
28、;
29、所述变体lstm模型的输出门的计算公式为:
30、;
31、所述变体lstm模型的正向传播过程为:
32、计算:
33、;
34、计算:
35、;
36、计算:
37、。
38、其中,其中为sigmoid函数,表示t-1时刻的输出,表示t时刻的输入,表示t时刻的输出,和表示遗忘门训练所需的参数,和表示增加门训练所需的参数,和表示输出门训练所需的参数,和表示计算训练所需的参数,为当前细胞状态,为上一时刻细胞状态;、和分别表示遗忘门、增加门和输出门的t时刻的输出;表示当前时间步t的细胞状态的候选值。
39、进一步地,步骤s3中,所述相似度迁移学习模型的损失函数为:
40、
41、式中,为源域数据的刀具磨损预测损失函数,,和为源工况下的第i个刀具磨损量的测量值和预测值;为源域和目标域数据特征之间的coral损失,,为特征向量维度;和分别为源域和目标阈特征协方差矩阵,为均方举证的frobenius范数;为源域和目标域之间的相似性度量,;为相似度迁移学习模型的预测输出,y为降维后的特征向量,为预测输出的期望,z表示k事件发生,为正则化参数,为数据种类,d为数据分布;和分别为域适应和相似性度量的权重系数。
42、进一步地,步骤s3中,经过adam优化算法多次迭代反馈,使损失函数l收敛到最优,得到训练完成的刀具磨损量预测模型;
43、第t次迭代的迭代公式为:
44、
45、
46、
47、
48、
49、
50、其中,表示一阶动量项,表示一阶矩估计的指数衰减率,取值0.9,表示一阶动量修正值,表示二阶动量项,表示二阶矩估计的指数衰减率,取值0.999,表示二阶动量修正值,表示的t次方,表示的t次方;表示第t次迭代的权重,表示第t次迭代的梯度值;表示学习率;为超参数,用于防止为零。
51、进一步地,步骤s3中,将无标签的目标域按照80%和20%的比例划分成两部分,其中,比例为80%的无标签的目标域与有标签的源域构成训练数据集。
52、与现有技术相比,本发明的有益效果如下:
53、本发明的基于umap数据降维的相似度度量迁移学习方法,采用迁移学习方法,构建新的损失函数评价目标域与源域之间的分布差异,从而实现预测模型在新工艺条件下的复用。
- 还没有人留言评论。精彩留言会获得点赞!