一种基于分聚类抽取与词向量模型的暗语识别方法与流程
本发明涉及暗语识别领域,具体涉及一种基于分聚类抽取与词向量模型的暗语识别方法。
背景技术:
1、随着互联网的普及和发展,网络安全问题日益突出。一些不法分子通过使用特定词汇、短语、语法结构、隐喻、暗示等方式(以下统称“暗语”)来隐藏真正的意图或含义,给社会安全以及人们的生活不小的影响。
技术实现思路
1、针对现有技术的不足,本发明提供了一种基于分聚类抽取与词向量模型的暗语识别方法,通过建立多级模型快速准确的得到暗语识别结果。
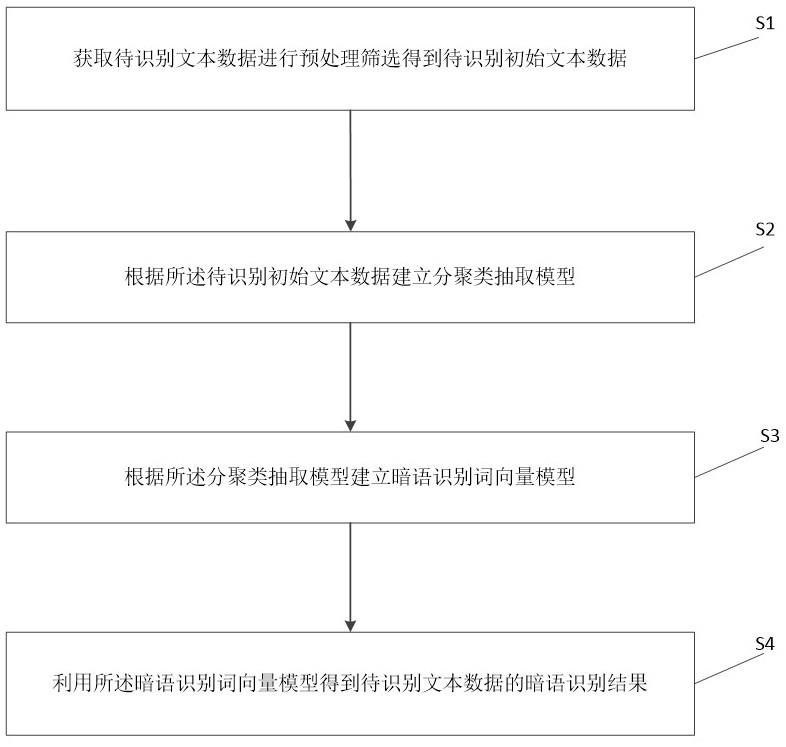
2、为实现上述目的,本发明提供了一种基于分聚类抽取与词向量模型的暗语识别方法,包括:
3、s1、获取待识别文本数据进行预处理筛选得到待识别初始文本数据;
4、s2、根据所述待识别初始文本数据建立分聚类抽取模型;
5、s3、根据所述分聚类抽取模型建立暗语识别词向量模型;
6、s4、利用所述暗语识别词向量模型得到待识别文本数据的暗语识别结果。
7、优选的,所述获取待识别文本数据进行预处理筛选得到待识别初始文本数据包括:
8、获取待识别文本数据;
9、利用所述待识别文本数据进行关键词预处理筛选获取待识别文本重点语义数据;
10、利用所述待识别文本重点语义数据与待识别文本数据作为待识别初始文本数据。
11、进一步的,根据所述待识别初始文本数据建立分聚类抽取模型包括:
12、s2-1、利用所述待识别初始文本数据的待识别文本重点语义数据建立基础分类抽取模型;
13、s2-2、利用所述待识别初始文本数据建立基础聚类抽取模型;
14、s2-3、利用所述基础分类抽取模型与基础聚类抽取模型作为分聚类抽取模型。
15、进一步的,利用所述待识别初始文本数据的待识别文本重点语义数据建立基础分类抽取模型包括:
16、利用所述待识别初始文本数据的待识别文本重点语义数据分别与待识别文本数据建立语义-语句映射集合;
17、利用所述待识别初始文本数据与语义-语句映射集合作为训练集;
18、利用所述训练集基于决策树进行训练得到基础分类抽取模型。
19、进一步的,利用所述待识别初始文本数据建立基础聚类抽取模型包括:
20、s2-2-1、获取待识别初始文本数据对应历史待识别文本重点语义数据与历史待识别文本数据;
21、s2-2-2、利用所述待识别初始文本数据的待识别文本重点语义数据分别与对应历史待识别文本重点语义数据建立重点语义关联映射集合;
22、s2-2-3、利用所述待识别初始文本数据的待识别文本数据与历史待识别文本数据建立综合文本关联映射;
23、s2-2-4、利用所述重点语义关联映射集合作为第一训练集,所述综合文本关联映射建立非正式验证集;
24、s2-2-5、利用所述第一训练集基于聚类算法进行训练得到初始聚类抽取模型;
25、s2-2-6、利用所述非正式验证集代入初始聚类抽取模型得到初始聚类抽取结果;
26、s2-2-7、判断所述初始聚类抽取结果是否均与待识别初始文本数据对应,若是,则输出初始聚类抽取模型作为基础聚类抽取模型,否则,获返回s2-2-1。
27、优选的,根据所述分聚类抽取模型建立暗语识别词向量模型包括:
28、利用所述待识别文本数据基于分聚类抽取模型得到待识别文本数据的分类抽取数据与待识别文本数据的聚类抽取数据;
29、利用所述待识别文本数据的分类抽取数据得到待识别文本数据的分类词汇向量;
30、根据所述待识别文本数据的分类词汇向量与对应待识别文本数据建立暗语识别词向量模型。
31、进一步的,利用所述待识别文本数据的分类抽取数据得到待识别文本数据的分类词汇向量包括:
32、利用所述待识别文本数据的分类抽取数据基于one-hot编码得到初始分类词汇向量;
33、利用所述初始分类词汇向量建立初始分类词汇向量集合;
34、判断所述初始分类词汇向量集合与待识别文本数据是否对应,若是,则根据所述初始分类词汇向量集合建立初始分类词汇向量稀疏矩阵,否则,放弃处理;
35、利用所述初始分类词汇向量稀疏矩阵进行归一化线性处理得到初始分类词汇向量稀疏矩阵的标签结果;
36、判断所述标签结果是否线性,若是,则输出初始分类词汇向量集合作为待识别文本数据的分类词汇向量,否则,放弃处理。
37、进一步的,根据所述待识别文本数据的分类词汇向量与对应待识别文本数据建立暗语识别词向量模型包括:
38、根据所述待识别文本数据的分类词汇向量获取对应历史待识别文本数据的分类词汇向量;
39、利用所述历史待识别文本数据的分类词汇向量与对应暗语识别词建立第二训练集;
40、利用所述待识别文本数据的分类词汇向量作为验证集;
41、利用所述训练集基于word2vec进行训练得到初始暗语识别词向量模型;
42、利用所述验证集代入初始暗语识别词向量模型得到初始暗语识别词输出结果;
43、判断所述初始暗语识别词输出结果与历史待识别文本数据对应暗语识别词是否强相关,若是,则输出初始暗语识别词向量模型作为暗语识别词向量模型,否则,放弃处理。
44、进一步的,利用所述暗语识别词向量模型得到待识别文本数据的暗语识别结果包括:
45、s4-1、利用所述待识别文本数据代入分聚类抽取模型得到待识别文本分聚类结果;
46、s4-2、利用所述待识别文本分聚类结果代入暗语识别词向量模型得到待识别文本暗语识别初始结果;
47、s4-3、利用所述待识别文本暗语识别初始结果进行回溯比对处理得到待识别文本数据的暗语识别结果。
48、进一步的,利用所述待识别文本暗语识别初始结果进行回溯比对处理得到待识别文本数据的暗语识别结果包括:
49、s4-3-1、判断所述待识别文本暗语识别初始结果是否存在对应历史待识别文本暗语识别初始结果,若是,则执行s4-3-2,否则,执行s4-3-3;
50、s4-3-2、判断所述待识别文本暗语识别初始结果对应待识别文本数据与历史待识别文本暗语识别初始结果对应历史待识别文本数据是否强相关,若是,则输出待识别文本暗语识别初始结果作为待识别文本数据的暗语识别结果,否则,执行s4-3-3;
51、s4-3-3、分别利用分聚类抽取模型的训练集与暗语识别词向量模型的训练集建立第一比对集合与第二比对集合;
52、s4-3-4、判断所述待识别文本暗语识别初始结果与第一比对集合是否存在对应,若是,则s4-3-5,否则,所述待识别文本数据的暗语识别结果为不存在;
53、s4-3-5、判断所述待识别文本暗语识别初始结果与第二比对集合是否存在对应,若是,则输出所述待识别文本暗语识别初始结果作为待识别文本暗语识别初始结果,否则,所述待识别文本数据的暗语识别结果为不存在。
54、与最接近的现有技术相比,本发明具有的有益效果:
55、对于初始文本先期进行重点词汇筛选,再建立多级模型,逐步筛选,同时引入线性归一保证模型训练过程的稳定准确,在原有人工标注暗语的基础上,用半监督学习的方式,解决数据人工标注的工作,大大减少人工标注成本,有效提升面向社交言论,针对其言论篇幅短、用于不规范、使用暗语刻意规避平台识别等特征的场景研判准确度问题。
- 还没有人留言评论。精彩留言会获得点赞!