面向数据库管理系统的日志数据的正则表达式匹配方法
本发明涉及数据库管理,尤其涉及一种面向数据库管理系统的日志数据的正则表达式匹配方法。
背景技术:
1、随着电子设备的普及,互联网相关行业的发展,现如今的数据量呈现指数级的增长,数据库管理系统随着数据量的增加也在不断的发展。在数据库管理系统的运行过程中,为保证数据库管理系统的正确、高效的运行会伴随着产生大量的日志数据以便于数据库管理系统在发生错误时能快速定位错误位置、快速恢复其功能。数据库管理系统的日志数据以规模庞大,数据相似度高为特点,因此经常利用正则表达式对数据库管理系统的日志数据进行管理,如何对数据库管理系统的日志数据进行高效的正则表达式匹配越来越成为一个问题。
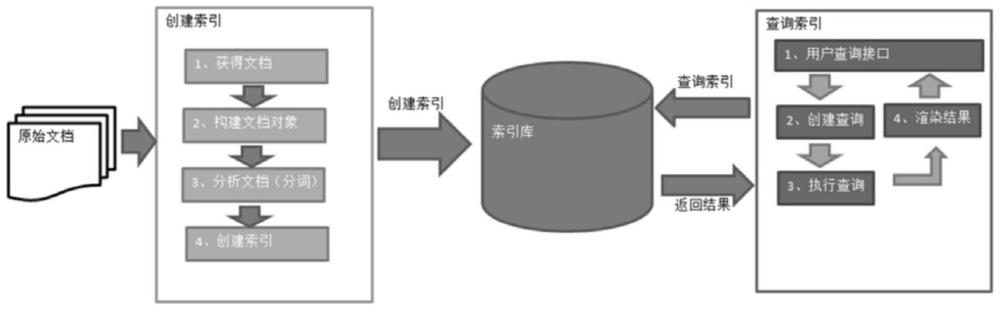
2、目前主流的搜索引擎的框架是lucene、solr、elasticsearch等,这些框架都是以lucene框架为内核,其架构如图1所示。lucene框架是非常成熟的、开源的纯java语言的全文索引检索工具包。它提供了一个简单却强大的应用程序接口,能够做全文索引和搜索。它是一个全文检索引擎的架构,包括了查询引擎和索引引擎,以及部分文本分析引擎。lucene框架的优点是高性能,丰富的功能,灵活的架构,开源的社区。lucene框架的缺点是内存占用较高,索引更新不实时,不支持分布式,不支持复杂的聚合和分析。
3、目前主流的搜索引擎的框架都是以lucene框架为内核,因此存在一些共同的问题:
4、(1)lucene框架的索引结构十分复杂,lucene框架的索引结构分为多层(segment->document->field->term),因此使用起来十分的复杂;
5、(2)lucene框架生成了正排索引、倒排索引等多种类型的索引,es中为提升查询速度生成了多种冗余索引,因此使用时索引占用空间十分庞大,使用起来十分厚重;
6、(3)lucene框架的索引结构中储存了很多在查询过程中无用的信息,因此索引消耗了很多不需要消耗的内存空间;
7、(4)lucene框架的正则表达式匹配算法只支持单token的正则表达式匹配而不支持跨token的正则表达式匹配,因此在使用时会出现不分漏解的情况,使用起来限制性较强。
8、由于以上缺陷,会或多或少的导致时间上、空间上的浪费。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种面向数据库管理系统的日志数据的正则表达式匹配方法,充分利用数据库管理系统的日志数据相似性的特点的,在大规模数据上,利用给定的正则表达式,查询出全部满足该正则表达式的匹配结果。
2、为解决上述技术问题,本发明所采取的技术方案是:面向数据库管理系统的日志数据的正则表达式匹配方法,包括以下步骤:
3、步骤1:获取数据库管理系统的大量相似日志数据,对大量相似日志数据建立前缀树和后缀树;
4、步骤1.1:建立前缀树:即字典树,用于快速查找单词;在前缀树的每一个叶子节点挂上倒排列表用于作为单词的索引;
5、步骤1.2:建立后缀树:类似于前缀树,不同于前缀树的是该字典树的建立是通过从后向前遍历日志数据得到的;在后缀树的每一个叶子节点挂上倒排列表用于作为单词的索引;
6、步骤1.3:增加或删除日志数据时,对前缀树后缀树索引进行某些结构的更改,用来保证该索引的正确性;
7、增加索引:在前缀树或后缀树对应节点增加指向该日志数据的指针;
8、删除索引:在前缀树或后缀树对应节点删除指向该日志数据的指针;
9、更新索引:先在前缀树或后缀树对应节点删除指向该日志数据的指针再在对应节点增加指向该日志数据的指针;
10、步骤2:当正则表达式到来时对正则表达式建立有限状态自动机;
11、步骤2.1:对正则表达式创建语义树;
12、步骤2.2:通过语义树创建其对应的图结构的有限状态自动机;
13、步骤3:利用有限状态自动机将正则表达式切割成前缀正则表达式路径和后缀正则表达式路径;
14、步骤3.1:通过有限状态自动机的起点向后走n个节点,此路径所经历的字符的组合即为正则表达式的前缀,即前缀正则表达式路径;
15、步骤3.2:通过有限状态自动机的终点向前走n个节点,此路径所经历的字符的组合即为正则表达式的后缀,即后缀正则表达式路径;
16、其中,前缀正则表达式路径:用于表示匹配目标正则表达式的词组所必须包含的前缀字母组合;
17、后缀正则表达式路径:用于表示匹配目标正则表达式的词组所必须包含的后缀字母组合;
18、步骤4:利用切割后的前缀正则表达式路径和后缀正则表达式路径分别在前缀树和后缀树上进行查找获得一系列前缀路径倒排列表和后缀路径倒排列表;
19、步骤4.1:将每一个日志数据从前到后进行q长度的滑动窗口的子串提取,并在前缀树上找到每一个子串所对应的节点,将该日志数据的出现为止插入到该节点的倒排列表中,获得前缀路径倒排列表;
20、步骤4.2:将每一个日志数据从后到前进行q长度的滑动窗口的子串提取,并在后缀树上找到每一个子串所对应的节点,将该日志数据的出现为止插入到该节点的倒排列表中,获得后缀路径倒排列表;
21、步骤5:对步骤4中获取的以正则表达式前缀为前缀的日志的出现位置列表和以正则表达式后缀为后缀的日志的出现位置列表进行归并操作得出与该正则表达式匹配的字符可能出现的位置;
22、对找到的获取的以正则表达式前缀为前缀的日志的出现位置列表和以正则表达式后缀为后缀的日志的出现位置列表进进行归并操作,得到日志数据中匹配该正则表达式的单词可能出现的全部位置;
23、采用基于计划树的方式进行归并,即通过衡量倒排列表的长度选择一个最优的顺序对倒排列表进行归并;
24、步骤6:利用有限状态自动机对与正则表达式匹配的字符可能出现的位置上的各词与正则表达式进行匹配并返回结果。
25、采用上述技术方案所产生的有益效果在于:本发明提供的面向数据库管理系统的日志数据的正则表达式匹配方法,通过对正则表达式进行分割,通过前缀路径、后缀路径、前缀树、后缀树等结构快速筛选大规模日志数据中能够匹配所给出正则表达式的单词的位置,从而降低了正则查询的时间。
26、本发明方法充分利用了数据库管理系统的日志数据的特点,即规模大、数据相似性较高,由于数据库管理系统的日志数据的这种特点,会使得前缀树和后缀树占用的空间量大大下降。从而可以使得在浪费较小空间的代价下能够达到较大的速度的提升。
27、对于本发明方法相较于传统正则表达式匹配算法所增加的正则表达式分割操作,使用的是传统正则表达式匹配算法也要使用的有限状态自动机(nfa),在该步骤并未额外增加内存空间的消耗。
28、在本发明的倒排索引归并中,采用了一种基于计划树的归并方法,相较于传统的暴力归并,本发明的算法对归并顺序进行了重新排列,从而减少归并比较次数而达到归并阶段时间消耗的减少。
29、综上,本发明方法充分利用了数据库管理系统的日志数据的相似度较高的特点,利在数据相似度高的条件下,利用可以大幅度减少内存空间占用量的结构前缀树、后缀树对算法速度进行提高。在这种机制下,更够以较小的内存空间为代价来获得较大的查询速度的提升。
- 还没有人留言评论。精彩留言会获得点赞!