一种中文实体关系提取方法及装置
本发明涉及数据挖掘领域,更具体的涉及一种中文实体关系提取方法及装置。
背景技术:
1、作为信息提取的一个关键子任务,实体关系提取任务旨在识别非结构化文本中实体对之间的语义关系,这是通过首先检测命名实体,然后参考预定义的关系类型对它们之间的语义关系进行分类来实现的。下游应用程序可以利用这一思想来提取丰富的语义知识,并提高各种任务的效率,包括但不限于文本摘要、问答系统、阅读理解和知识图谱。
2、除了少数以中文文档和段落为输入的方法外,大多数现有的中文关系提取方法都依赖于句子级文本作为输入。它们可以分为三类:基于字的中文实体关系抽取、基于词的中文实体关系抽取和混合的中文实体关系抽取模型。对于基于字的模型,将字序列输入到模型中,以便从字中有效地提取形态学信息。然而,这种方法有一个局限性,即它不能充分利用词级的语义和语法信息。为此,基于词的模型被提出,这种方法主要将输入文本分割成词序列,以充分学习序列的上下文语义。从理论上讲,这种类型的模型更能胜任中文实体关系抽取任务,但基于词的模型的性能可能会受到分词模糊问题的影响。为了克服上述两种模型的不足,提出了混合的模型。这类模型能够同时利用字级和词级的信息。更确切地说,在来自外部知识库的信息的帮助下,词级信息被动态地融合到字级表示中,从而有效地将词的分割信息注入到语义表示中。这使得它们比基于字和基于词的方法更擅于处理分割问题。
3、然而,混合的中文实体关系抽取模型仍然受到多义词歧义的影响。如果没有外部知识库的帮助,很难从纯文本中学习两种含义。如果对这个多义词有更多的了解,混合模型可以通过获得它的多个含义来消除歧义,并学习更精确的多义词表示,现有技术中,如何为每一种含义分配权重仍然是一项具有挑战性的任务。此外,现有的大多数模型只能利用编码得到的隐藏状态的单向语义表示进行实体关系分类,其它的模型虽然可以考虑双向语义表示,却不能充分融合双向语义信息,导致了分类的不准确。因此,如何设计一个可以充分融合隐藏状态双向语义的分类器也是一个关键问题。
技术实现思路
1、本发明实施例提供一种中文实体关系提取方法及装置,解决现有中文实体关系抽取只能利用编码得到的隐藏状态的单向语义表示进行实体关系分类,导致分类不准确的问题。
2、本发明实施例提供一种中文实体关系提取方法,包括:
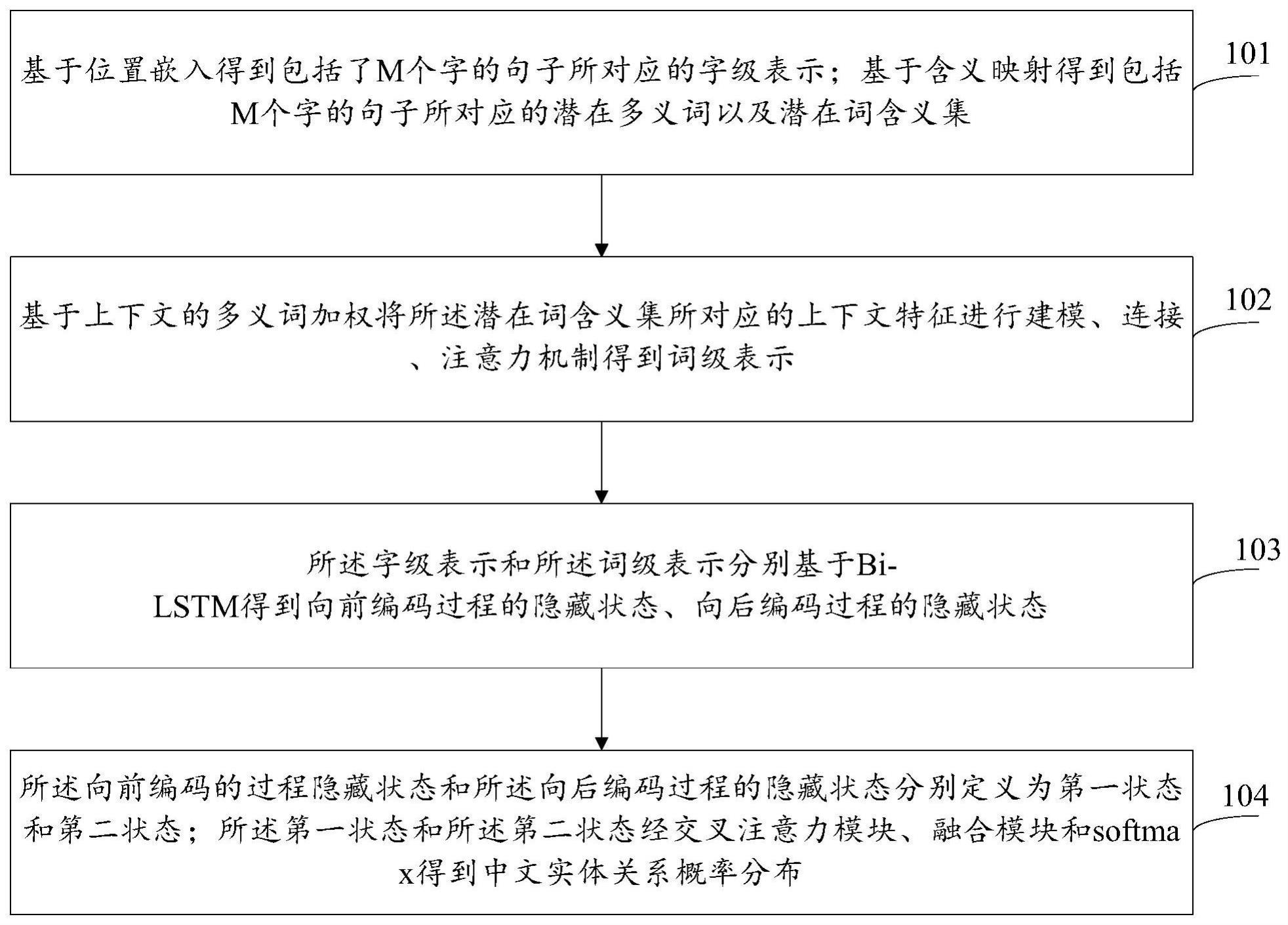
3、基于位置嵌入得到包括了m个字的句子所对应的字级表示;基于含义映射得到包括m个字的句子所对应的潜在多义词以及潜在词含义集;
4、基于上下文的多义词加权将所述潜在词含义集所对应的上下文特征进行建模、连接、注意力机制得到词级表示;
5、所述字级表示和所述词级表示分别基于bi-lstm得到向前编码过程的隐藏状态、向后编码过程的隐藏状态;
6、所述向前编码的过程隐藏状态和所述向后编码过程的隐藏状态分别定义为第一状态和第二状态;所述第一状态和所述第二状态经交叉注意力模块、融合模块和softmax得到中文实体关系概率分布。
7、优选地,所述基于位置嵌入得到包括了m个字的句子所对应的字级表示,具体包括:
8、将包括m个字的句子中的每个字ci映射到dc维度的稠密向量,得到每个字ci的字嵌入:
9、
10、根据每个字与句子的头部实体、尾部实体和所述字嵌入得到每个字的字级表示:
11、
12、其中,表示第i个字c的字嵌入,表示第i个字c的头部实体,表示第i个字c的尾部实体,表示第i个字c的字级表示,ec表示嵌入查找表。
13、优选地,所述基于含义映射得到包括m个字的句子所对应的潜在多义词以及潜在词含义集,具体包括:
14、定义从第b个字开始至第e个字结束的潜在多义词为wb,e,将每个潜在多义词转换为一个向量,得到潜在多义词为wb,e的第k个含义以及每个潜在多义词对应潜在词含义集:
15、
16、
17、其中,esen代表查找表,表示潜在多义词为wb,e的第k个含义,表示潜在多义词为wb,e的潜在含义集。
18、优选地,所述基于上下文的多义词加权将所述潜在词含义集所对应的上下文特征进行建模、连接、注意力机制得到词级表示,具体包括:
19、将潜在多义词为wb,e的左上下文定义为右上下文定义为
20、所述左上下文和所述右上下文经过上下文编码器之后分别得到和所述和所述被连接后得到
21、通过下列公式得到词级表示:
22、
23、
24、
25、
26、其中,表示词级表示,w1、w2、w3和w4是可训练的参数,⊙表示点积运算,表示外积运算,表示潜在多义词为wb,e的潜在含义集。
27、优选地,所述向前编码的过程隐藏状态和所述向后编码过程的隐藏状态分别定义为第一状态和第二状态;所述第一状态和所述第二状态经交叉注意力模块、融合模块和softmax得到中文实体关系概率分布,具体包括:
28、确定所述第一状态对应的第一查询矩阵、第二键矩阵和第二值矩阵为(qf,kb,vb),第二状态对应的第二查询矩阵、第一键矩阵和第一值矩阵为(qb,kf,vf),所述第一状态和(qf,kb,vb)、所述第二状态和(qb,kf,vf)分别经多头注意力子层得到所述第一状态和所述第二状态对应的第一输出状态;
29、基于第一输出状态得到与所述第一输出状态对应的语义向量,所述第一输出状态和所述语义向量经拼接、相机和归一化,得到特征向量;
30、所述特征向量经softmax层得到中文实体关系概率分布。
31、本发明实施例提供一种中文实体关系提取装置,包括:
32、第一得到单元,用于基于位置嵌入得到包括了m个字的句子所对应的字级表示;基于含义映射得到包括m个字的句子所对应的潜在多义词以及潜在词含义集;
33、第二得到单元,用于基于上下文的多义词加权将所述潜在词含义集所对应的上下文特征进行建模、连接、注意力机制得到词级表示;
34、第三得到单元,用于所述字级表示和所述词级表示分别基于bi-lstm得到向前编码过程的隐藏状态、向后编码过程的隐藏状态;
35、第四得到单元,用于所述向前编码的过程隐藏状态和所述向后编码过程的隐藏状态分别定义为第一状态和第二状态;所述第一状态和所述第二状态经交叉注意力模块、融合模块和softmax得到中文实体关系概率分布。
36、优选地,,所述第一单元具体用于:
37、将包括m个字的句子中的每个字ci映射到dc维度的稠密向量,得到每个字ci的字嵌入:
38、
39、根据每个字与句子的头部实体、尾部实体和所述字嵌入得到每个字的字级表示:
40、
41、其中,表示第i个字c的字嵌入,表示第i个字c的头部实体,表示第i个字c的尾部实体,表示第i个字c的字级表示,ec表示嵌入查找表。
42、优选地,,所述第一得到单元,具体用于:
43、定义从第b个字开始至第e个字结束的潜在多义词为wb,e,将每个潜在多义词转换为一个向量,得到潜在多义词为wb,e的第k个含义以及每个潜在多义词对应潜在词含义集:
44、
45、
46、其中,esen代表查找表,表示潜在多义词为wb,e的第k个含义,表示潜在多义词为wb,e的潜在含义集。
47、本发明实施例提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述任意一项所述的中文实体关系提取方法。
48、本发明实施例提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述任意一项所述的中文实体关系提取方法。
49、本发明实施例提供一种中文实体关系提取方法及装置,该方法包括:基于位置嵌入得到包括了m个字的句子所对应的字级表示;基于含义映射得到包括m个字的句子所对应的潜在多义词以及潜在词含义集;基于上下文的多义词加权将所述潜在词含义集所对应的上下文特征进行建模、连接、注意力机制得到词级表示;所述字级表示和所述词级表示分别基于bi-lstm得到向前编码过程的隐藏状态、向后编码过程的隐藏状态;所述向前编码的过程隐藏状态和所述向后编码过程的隐藏状态分别定义为第一状态和第二状态;所述第一状态和所述第二状态经交叉注意力模块、融合模块和softmax得到中文实体关系概率分布。该方法提出了基于上下文感知的双向晶格模型,这是一种端到端的中文实体关系抽取方法,融合了多粒度知识,包括字级、词级和上下文级知识;该方法提出了基于上下文的多义词加权模块,其充分挖掘了上下文知识,并利用得到的上下文知识为多义词的每一种含义赋权;同时,本发明实施例不仅提高了中文实体关系抽取的性能,也提供了一种全新的中文多义词消歧思路,即基于上下文知识的多义词消歧方法。
- 还没有人留言评论。精彩留言会获得点赞!