人体关键点生成方法及装置、计算机可读存储介质、终端与流程
本发明涉及人体关键点生成,尤其涉及一种人体关键点生成方法及装置、计算机可读存储介质、终端。
背景技术:
1、随着人工智能技术的发展,生成式人工智能(artificial intelligencegenerated content,aigc)已经成为当前最热门的研究课题。其中,元宇宙仍是非常重要的应用方向之一。随着算力和技术的发展,各种和元宇宙相关的增强现实(augmentedreality,ar)和虚拟现实(virtual reality,vr)设备被不断推出。而在这些设备中,人物形象都是不可缺少的一环。无论是虚拟人物形象还是真实人物形象都会涉及到大量生成任务。当前主流的人物形象生成技术通常包含两个任务,其一是基于驱动音频生成人体关键点;其二是基于已获得的人体关键点生成人物形象。研究如何准确地生成人体关键点,对于提高后续生成的人物形象的质量至关重要。
2、现有技术中,大多数人体关键点生成任务并没有针对人脸区域和非人脸区域(也称为躯体区域)进行区分,而是对这两大区域执行统一的生成任务。例如,直接将驱动音频输入训练好的模型,由模型统一输出包含人脸区域和躯体区域的完整人体关键点。
3、然而,由于人脸区域与音频的相关性,和躯体区域与音频的相关性并不相同。具体而言,人脸区域的表现状态(例如,表情、口型等)与音频的语义和韵律(例如,节奏、音速、音强等)都具有较强相关性,而躯体区域的表现状态(例如,手势动作)与音频相关性较弱,具体体现在不同个性的人在说同一段话时,可能采取不同风格的手势动作。因此现有技术针对人脸关键点和躯体关键点采用统一生成任务,可能导致最终获得的人体关键点的准确性和稳定性不足。
技术实现思路
1、本发明实施例解决的技术问题是如何提高生成的人体关键点的准确性和稳定性。
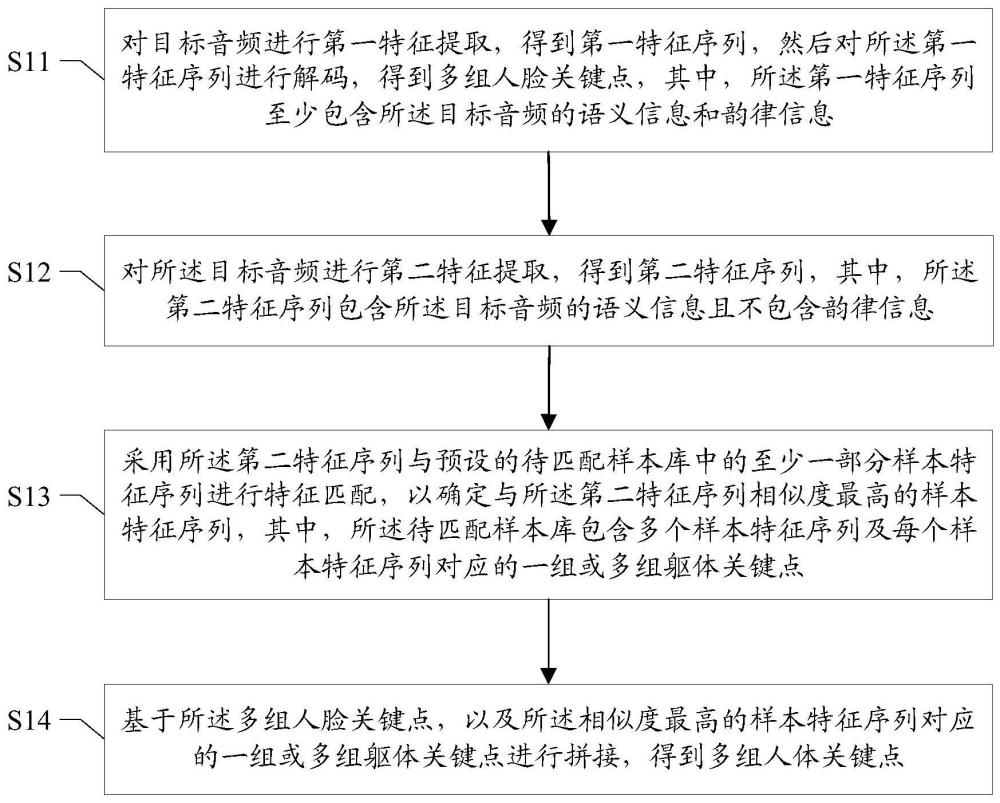
2、为解决上述技术问题,本发明实施例提供一种人体关键点生成方法,所述人体关键点包含人脸关键点和躯体关键点,所述方法包括以下步骤:对目标音频进行第一特征提取,得到第一特征序列,然后对所述第一特征序列进行解码,得到多组人脸关键点,其中,所述第一特征序列至少包含所述目标音频的语义信息和韵律信息;对所述目标音频进行第二特征提取,得到第二特征序列,其中,所述第二特征序列包含所述目标音频的语义信息且不包含韵律信息;采用所述第二特征序列与预设的待匹配样本库中的至少一部分样本特征序列进行特征匹配,以确定与所述第二特征序列相似度最高的样本特征序列,其中,所述待匹配样本库包含多个样本特征序列及每个样本特征序列对应的一组或多组躯体关键点;基于所述多组人脸关键点,以及所述相似度最高的样本特征序列对应的一组或多组躯体关键点进行拼接,得到多组人体关键点。
3、可选的,在采用所述第二特征序列与预设的待匹配样本库中的至少一部分样本特征序列进行特征匹配之前,所述方法还包括:获取说话者说话过程的样本视频,并从中提取样本音频和样本图像序列;对所述样本音频进行特征提取,以得到多个样本特征序列;对于至少一部分样本特征序列,从所述样本图像序列中确定与每个所述样本特征序列时序对齐的多帧样本图像;从与每个所述样本特征序列时序对齐的多帧样本图像中,选取一帧或多帧样本图像进行躯体关键点识别,得到该样本特征序列对应的一组或多组躯体关键点;采用所述至少一部分样本特征序列及其各自对应的一组或多组躯体关键点,构建所述待匹配样本库。
4、可选的,采用下述方式确定所述至少一部分样本特征序列:确定每个样本特征序列对应的原始样本文本;从所述多个样本特征序列中,选取原始样本文本列入预设文本集合的样本特征序列,作为所述至少一部分样本特征序列。
5、可选的,从与每个所述样本特征序列时序对齐的多帧样本图像中,选取一帧或多帧样本图像进行躯体关键点识别,包括:从与每个所述样本特征序列时序对齐的多帧样本图像中,选取时序最前的一帧样本图像以及时序最后的一帧样本图像分别进行躯体关键识别。
6、可选的,基于所述多组人脸关键点,以及所述相似度最高的样本特征序列对应的一组或多组躯体关键点进行拼接,包括:如果所述相似度最高的样本特征序列对应的躯体关键点组的总组数,小于所述多组人脸关键点的总组数,则基于所述相似度最高的样本特征序列对应的一组或多组躯体关键点进行插值处理,得到与所述多组人脸关键点在时序上一一对齐的多组躯体关键点;基于预设的标准间距,对每组人脸关键点及其时序对齐的躯体关键点组进行拼接;其中,所述标准间距用于表示每组人脸关键点中预设的基准人脸关键点位置及其时序对齐的躯体关键点组中预设的基准躯体关键点位置之间的间距。
7、可选的,所述对目标音频进行第一特征提取,得到第一特征序列,然后对所述第一特征序列进行解码,得到多组人脸关键点,包括:确定人脸关键点生成模型,所述人脸关键点生成模型包括:音频特征提取子模型和解码子模型;将所述目标音频输入所述音频特征提取子模型进行第一特征提取,得到所述第一特征序列;将所述第一特征序列输入所述解码子模型,得到所述多组人脸关键点。
8、可选的,所述音频特征提取子模型包括第一子模型和第二子模型;将所述目标音频输入所述音频特征提取子模型进行第一特征提取,包括:将所述目标音频输入所述第一子模型进行初步特征提取,得到初步特征序列;将所述初步特征序列输入所述第二子模型进行特征再提取,得到所述第一特征序列;其中,所述第一特征序列中的第一特征的维度小于所述初步特征序列中的初步特征的维度。
9、可选的,所述确定人脸关键点生成模型,包括:构建初始化模型,所述初始化模型包括预训练的第一子模型、待优化的第二子模型以及预训练的解码子模型;采用训练音频构建训练数据集,以及采用所述训练音频对应的训练图像的人脸关键点作为标注数据,对所述初始化模型进行迭代训练,以得到所述人脸关键点生成模型;其中,迭代训练过程中,仅优化所述待优化的第二子模型的参数。
10、本发明实施例还提供一种人体关键点生成装置,包括:人脸关键点生成模块,用于对目标音频进行第一特征提取,得到第一特征序列,然后对所述第一特征序列进行解码,得到多组人脸关键点,其中,所述第一特征序列至少包含所述目标音频的语义信息和韵律信息;特征提取模块,用于对所述目标音频进行第二特征提取,得到第二特征序列,其中,所述第二特征序列包含所述目标音频的语义信息且不包含韵律信息;躯体关键点生成模块,用于采用所述第二特征序列与预设的待匹配样本库中的至少一部分样本特征序列进行特征匹配,以确定与所述第二特征序列相似度最高的样本特征序列,其中,所述待匹配样本库包含多个样本特征序列及每个样本特征序列对应的一组或多组躯体关键点;关键点拼接模块,用于基于所述多组人脸关键点,以及所述相似度最高的样本特征序列对应的一组或多组躯体关键点进行拼接,得到多组人体关键点。
11、本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行上述人体关键点生成方法的步骤。
12、本发明实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述人体关键点生成方法的步骤。
13、与现有技术相比,本发明实施例的技术方案具有以下有益效果:
14、由于人体的躯体区域与音频的相关性,与人体的人脸区域与音频的相关性并不一致。具体而言,人脸区域的表现状态(例如,表情、口型等)与音频的语义、韵律(例如,节奏、音速、音强等)都具有较强相关性,因此可以通过模型训练学习到目标音频与人脸关键点之间的相关性规律。然而,对于躯体区域,其与音频的相关性相较而言更弱,因为不同个性的人在说同一段话时可能采取不同风格的躯体动作,例如,个性张扬的人手势幅度较大,个性内敛的人手势幅度小甚至无手势,因此,难以通过模型训练学习到音频与躯体关键点之间的相关性规律。
15、基于上述原理,在本发明实施例中,对于人脸区域和躯体区域进行区分。一方面,分别采取不同方式对目标音频进行特征提取,得到包含不同信息的第一特征序列和第二特征序列,其中,第一特征序列至少包含目标音频的语义信息和韵律信息,用于解码获得人脸关键点;第二特征序列包含所述目标音频的语义信息且不包含韵律信息,用于获得躯体关键点。另一方面,对于躯体关键点的获得方法,并非通过常规模型训练与生成方式,而是通过与预设的待匹配样本库进行特征匹配的方式,其中,待匹配样本库包含的样本特征序列与躯体关键点组之间的对应关系是预先确定且固定不变的,并且各组躯体关键点通常来源于说话者的实际样本图像,具有更强的稳定性和可预期性。
16、由此,相较于现有技术采用经过训练的模型统一生成人脸关键点和躯体关键点可能效果不佳,本实施方案有助于获得既能准确表达音频语义、韵律的人脸关键点,又能准确表达音频语义且具备更加稳定的躯体动作的躯体关键点,最终获得准确、高质量的完整人体关键点。
- 还没有人留言评论。精彩留言会获得点赞!