一种基于大语言模型的知识图谱生成式问答方法及系统与流程
本发明涉及知识图谱,特别是一种基于大语言模型的知识图谱生成式问答方法及系统。
背景技术:
1、智能问答如今已成为人们解决问题、快速获取相关信息的一种重要方式。问答系统是一种对用户使用自然语言提出的问题能够尽可能快速、准确回答的程序,目前最普遍的智能问答技术是基于深度学习构建的预训练模型,其核心是通过语义理解识别问题意图,再基于知识库检索相关答案。相较于传统的问答数据库,知识图谱更直观的展示了数据关系与数据特征,因此各领域通过构建特定领域知识图谱,将其作为智能问答的主要数据来源库。
2、知识图谱可以看作是知识的结构化表示,由三元组(头实体、关系、尾实体)构成,表示两实体之间的关系,知识图谱问答主要是通过子图查询、语义相似匹配的方法实现问答,但目前仍存在以下不足:
3、一是问题泛化能力差,知识图谱问答过程中需要识别问题实体、问题关系,将其关联图谱节点,匹配相关三元组,从而检索答案;若问题较泛化,则会存在无法将问题实体、关系成功匹配子图的情况,无法检索答案。
4、二是问题局限性大,知识图谱问答是基于三元组的实体名称和实体关系返回答案,因此仅支持对图谱节点的关联关系和属性相关内容提问,其他内容则无法回答。
5、三是图谱推理能力弱,当前知识图谱问答不具备推理能力,无法通过图谱子图内容进行多跳推理或统计。
6、因此,本发明提供了一种基于大模型的知识图谱问答方法、装置及系统,问答过程中准确理解问题意图,基于知识图谱数据生成问题答案。
技术实现思路
1、鉴于此,本发明提供一种基于大语言模型的知识图谱生成式问答方法及系统,能够通过用户输入问题,解析问题并提取关键要素,基于知识图谱检索子图作为问答知识库,再利用子图信息与问句构建模型提示语句,大语言模型最终生成问题答案。
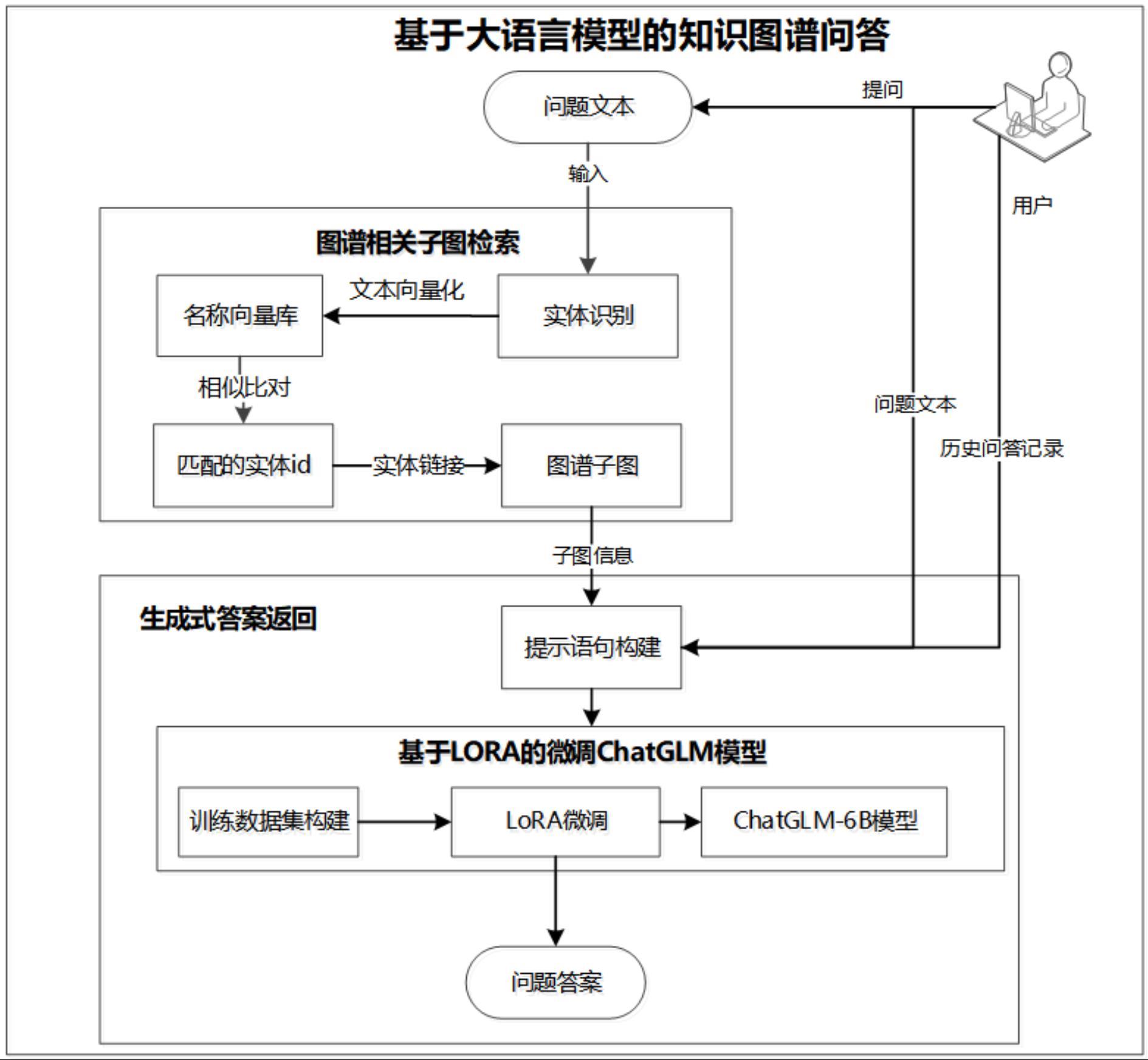
2、本发明公开了一种基于大语言模型的知识图谱生成式问答方法,其包括:
3、步骤1:构建大语言模型微调训练数据,训练数据包括提示语句、问题集和答案集;其中,提示语句包括提示模版和实例数据;
4、步骤2:基于lora微调大语言模型;
5、步骤3:通过子图检索策略为经lora微调后的大语言模型提供问答知识库;
6、步骤4:将经lora微调后的大语言模型作为问答推理模型,将问题文本输入问答推理模型,问答推理模型基于步骤3提供的问答知识库,生成问题答案。
7、进一步地,所述步骤1包括:
8、步骤11:构建训练数据的问题集和答案集:
9、通过获取领域知识图谱的三元组结构数据,调用基于bert预训练模型生成图谱单跳、多跳类问题集和答案集,令图谱三元组triple=[node1,rel,node2],其中,node1为头实体,rel为关系边,node2为尾实体,预训练模型输入为[node1,rel],模型根据[node1,rel],输出问题quest,同时node2为问题答案answer,自动构建一批问题与答案数据;
10、步骤12:构建训练数据的提示语句:
11、通过领域知识图谱获取结构化的实例数据:标注出图谱数据的实体和关联三元组信息,令知识图谱数据x={name:name,k1:v1,k2:v2,...,kn:vn},设x为知识图谱中一个实体节点的关系数据,name为节点名称,kn为节点的属性或关系边名称,vn为节点对应的属性值或关系边相连节点名称;将图谱数据x转换为列表数据x`=[[name,k1,v1],[name,k2,v2],...,[name,kn,vn]],x`即是模型训练数据的实例数据;
12、再面向知识图谱问答任务构建提示模版p;将实例数据添加至提示模版即生成模型训练的提示语句prompt。
13、进一步地,所述步骤2包括:
14、步骤21:将lora模型参数拆分两部分:预训练权重w∈rd*d和finetune增量权重δw∈rd*d,w为冻住的预训练权重,δw为微调过程中产生的权重更新量;设输入为x,输出为h,则有h=wx+δwx;训练过程中,固定预训练权重w,采用a和b两个低秩矩阵近似表示δw,即h=wx+bax,a∈rr*d,b∈rr*d,对a采用高斯初始化,对b采用零初始化,训练过程中对低秩矩阵a和b进行训练,只保存低秩矩阵部分作为模型权重;
15、步骤22:将步骤1的训练数据进行tokenizer处理,设置训练参数,加载chatglm-6b模型,启动微调训练,保存训练过程中损失值loss最低的模型权重;
16、模型微调结束后,利用部分训练数据验证模型效果,将训练完成的矩阵乘积ba与原本固定的权重矩阵w相加作为新的模型区中矩阵,即h=(w+ba)x,将权重矩阵h作为新权重参数替换最初预训练模型语言模型参数,利用模型的测试结果res1与训练前模型测试作对比res0,对比指标采用问答平均准确率acc;
17、若res1>res0,则模型微调效果提升,可将其作为后续图谱问答的推理模型;若res1<res0,则重新调整训练参数,重复步骤21和步骤22,直至微调后模型测试结果优于训练前结果。
18、进一步地,所述对比指标采用问答平均准确率acc,计算方式为:
19、
20、
21、其中,n为测试样本总数量,xi为测试集中问题qi的预测答案,若预测答案与标准答案相同,则取值为1,反之,取值为0;ti为测试集中问题qi返回答案所需时长。
22、进一步地,所述步骤3包括:
23、步骤31:构建垂直领域知识图谱数据库和实体名称向量库;将结构化的实体-关系-实体和实体-属性-属性值三元组数据批量导入图谱库,知识图谱构建完成后,按标签检索实体节点,利用transe方法将实体名称转换为文本向量,将文本向量与节点id分别保存于向量库中;
24、步骤32:利用信息抽取模型uie完成实体识别任务:使用uie框架时,需要先建立一个目标查询实体列表,通过对知识图谱中的节点进行筛选,将目标实体提取出来,并构建对应的ac自动机模型;在得到文本数据并进行命名实体识别之后,判断抽取的实体是否是目标实体;
25、步骤33:将步骤32中识别出的目标实体转换为文本向量x1,利用余弦相似度将文本向量x1分别与步骤31构建的名称向量库中所有向量进行相似对比,最终从向量库中返回与文本向量x1余弦相似度最大的向量和节点id;
26、步骤34:实体链接将实体指称项链接到知识库中对应实体至知识图谱节点,基于步骤33返回的节点id信息,在候选知识图谱中找到对应的节点描述;以该图谱节点为中心,检索与其存在关系边连接的所有图谱数据,作为子图返回,为后续问答提供数据支撑。
27、进一步地,在所述步骤31中:
28、transe方法将知识图谱中的关系定义为头实体e1到尾实体e2的映射转换:当给定一个头实体entity1时,根据知识图谱中的关系表示预测出相应的尾实体entity2;同样地,根据关系表示和尾实体来预测出头实体;实体间的关系表示为:r=e1-e2,同时认为当实体共现句的特征表示向量si与目标关系向量r相似度越高时,该共现句能正确表达目标关系的可能性越大,其注意力权重i也越高。
29、进一步地,在所述步骤32中,判断抽取的实体是否是目标实体,包括:
30、通过ac自动机直接判断文本中需要查找的实体;或者是,
31、先将目标实体列表转化成词向量表,抽取得到的实体也转换成词向量,将抽取实体的词向量和表中词向量进行对比,判断在目标实体列表中是否有与抽取实体语义相同的实体;如果有,则将抽取实体加入后续的知识抽取工作中,基于此实现实体的模糊抽取;
32、信息抽取模型uie的输入包括schema和text两个参数;其中,schema为抽取实体类型,text为待抽取文本。
33、进一步地,在所述步骤34中:
34、给定一个包含一组识别提及m={m1,m2,…,mn}的规则文本s,实体链接系统的目标是找到一个映射,将每个提及mi链接到目标实体ei,目标实体ei是指知识库中明确页面,或者预测没有对应的图谱中当前提及的实体,在实体消歧之前,对于每个提及mi,潜在候选实体oi∈{ei1,ei2,…,eik},首先由候选实体从指定图谱中选择,每个候选在知识图谱中拥有一个对应的描述dij,作为支持描述;其中k是用于修剪候选集的预定义参数。
35、进一步地,所述步骤4包括:
36、步骤41:输入问题文本quest后,根据提问场景设置uie模型所需schema列表,返回问题实体entity,基于步骤3子图检索方法,返回问题相关子图信息kg;
37、步骤42:结合步骤41的问题信息、问题实体、图谱子图信息,构建问答提示语句prompt;
38、步骤43:模型推理,输入步骤42中的prompt和history,第一次模型输入时,history为空,用于保存用户问答对话记录;最终大语言模型生成是纯字符串格式,经过正则匹配分词、结构化拼装后,返回问题答案。
39、本发明还公开了一种适用于上述所述的基于大语言模型的知识图谱生成式问答方法的系统,所述系统包括:
40、构建模块,用于构建大语言模型微调训练数据,训练数据包括提示语句、问题集和答案集;其中,提示语句包括提示模版和实例数据;
41、微调模块,用于基于lora微调大语言模型;
42、提供模块,用于通过子图检索策略为经lora微调后的大语言模型提供问答知识库;
43、生成模块,用于将经lora微调后的大语言模型作为问答推理模型,将问题文本输入问答推理模型,问答推理模型基于提供的问答知识库,生成问题答案。
44、由于采用了上述技术方案,本发明具有如下的优点:
45、1.本发明提出了基于知识图谱数据的大模型生成式问答方法,大模型不再仅根据问题文本生成答案,而是将图谱信息与问题共同构建为模型提示语句,生成问题答案,从而保证答案更准确、可溯源。
46、2.本发明较传统的知识图谱问答方法更具问题泛化能力,泛化能力主要体现在问题理解与可回答的问题类型两方面。问题理解方面,大语言模型相比传统的图谱问答模型具备更强的语义理解能力,满足用户更口语化、更自然化的提问;可回答问题类型方面,传统的图谱问答方法仅支持回答图谱关系、属性相关内容,无法针对节点包含的具体内容进行回答,而大模型支持对图谱节点、关系、属性包含的所有内容进行提问,突破了图谱结构限制。
47、3.本发明较传统的知识图谱问答方法更具推理、统计分析能力,传统的知识图谱问答具备单跳、多跳问答能力,不具备推理、统计功能,仅针对具体场景制定一系列问答策略和规则实现推理或统计,一旦业务场景更改方法便不再适用,不具备泛化能力;而大模型本身具备较强语义理解能力,能理解复杂问题并明确提问意图,具备思维链推理能力,能基于提供的知识图谱数据进行推理分析,具备多跳推理、统计分析等增量式能力。
- 还没有人留言评论。精彩留言会获得点赞!