一种模型蒸馏方法、装置、存储介质和电子设备与流程
本技术涉及神经网络技术,特别涉及一种模型蒸馏方法、装置、存储介质和电子设备。
背景技术:
1、近年来,预训练大模型技术蓬勃发展,不管在自然语言处理任务还是计算机视觉任务上都表现出远超传统cnn模型的强大性能和跨领域泛化能力。在实际应用中,模型的样本采集场景与应用场景往往存在一定的差异,而不同场景样本之间的域偏移凸显出模型泛化能力的重要性。模型的性能一般会随着训练数据的增加而增强,从域泛化(domaingeneralization)的角度来看,训练样本的领域数量增加可以使模型积累更多的通识经验,从而提升新领域下的泛化能力。但是在实际应用中,多领域样本的采集和标定成本较高,实施起来十分复杂,探索高效低成本的领域扩张方法是提升模型泛化能力的重要研究方向。
技术实现思路
1、本技术提供一种模型蒸馏方法、装置、存储介质和电子设备,能够自动对训练样本域进行扩张,并基于扩张后的多领域的样本进行蒸馏处理,从而提高模型在多场景的泛化能力。
2、为实现上述目的,本技术采用如下技术方案:
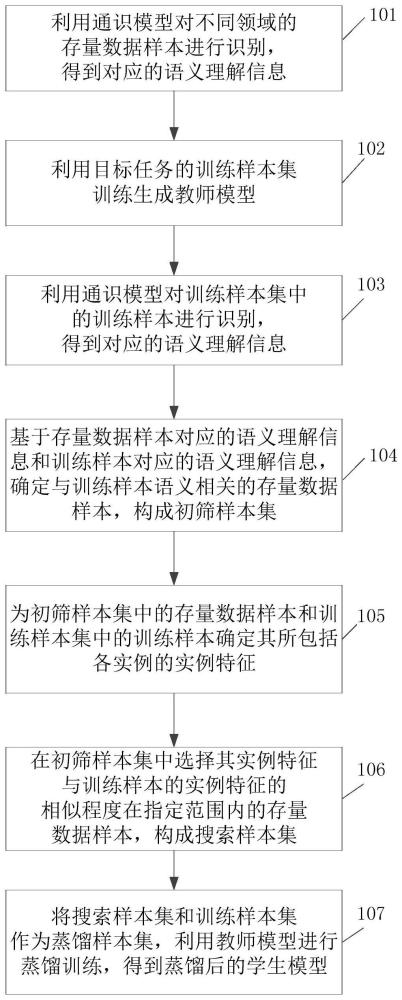
3、一种模型蒸馏方法,包括:
4、利用通识模型对不同领域的存量数据样本进行识别,得到对应的语义理解信息;
5、利用目标任务的训练样本集训练生成教师模型;
6、利用所述通识模型对所述训练样本集中的训练样本进行识别,得到对应的语义理解信息;
7、基于所述存量数据样本对应的语义理解信息和所述训练样本对应的语义理解信息,确定与所述训练样本语义相关的存量数据样本,构成初筛样本集;
8、为所述初筛样本集中的存量数据样本和所述训练样本集中的训练样本确定其所包括各实例的实例特征;
9、在所述初筛样本集中选择其实例特征与所述训练样本的实例特征的相似程度在指定范围内的存量数据样本,构成搜索样本集;
10、将所述搜索样本集和所述训练样本集作为蒸馏样本集,利用所述教师模型进行蒸馏训练,得到蒸馏后的学生模型。
11、较佳地,在利用目标任务的训练样本集生成教师模型时进一步生成初始学生模型;
12、在所述构成搜索样本集之后、所述利用所述教师模型进行蒸馏处理之前,该方法进一步包括:
13、基于所述教师模型和所述初始学生模型训练生成数据生成模型,以使所述教师模型对所述数据生成模型得到的生成数据样本的理解与所述初始学生模型对所述数据生成模型得到的生成数据样本的理解之间的差异超过设定的程度;将所述搜索样本集中的存量数据样本和/或所述训练样本集中的训练样本以及各样本的类别信息输入所述数据生成模型,得到生成数据样本,构成生成样本集合;
14、在利用所述教师模型进行蒸馏处理时,进一步将所述生成样本集合并入所述蒸馏样本集。
15、较佳地,所述数据生成模型的损失函数为其中,所述为所述数据生成模型得到的生成数据样本,为所述教师模型对所述生成数据样本进行处理后得到的输出,所述为所述初始学生模型对所述生成数据样本进行处理后得到的输出,为所述目标任务模型训练的损失函数,i为所述生成数据样本的索引。
16、较佳地,所述语义理解信息包括样本中各实例的自然语义理解和位置信息;
17、在确定与所述训练样本语义相关的存量数据样本时,基于所述语义理解信息中的所述自然语义理解进行。
18、较佳地,所述为所述初筛样本集中的存量数据样本和所述训练样本集中的训练样本确定其所包括各实例的实例特征,包括:
19、基于所述存量数据样本和所述训练样本中各实例的语义理解信息的位置信息,提取各实例对应的图像块,再对相应的图像块进行特征提取,得到相应实例的实例特征。
20、较佳地,所述在所述初筛样本集中选择其实例特征与所述训练样本的实例特征的相似程度在设定范围内的存量数据样本构成搜索样本集,包括:
21、对所述训练样本的各实例的实例特征进行聚类,得到多个聚类中心;
22、计算所述初筛样本集中存量数据样本的各个实例的实例特征与每个聚类中心的距离,选择实例特征的距离最小的前ks个存量数据样本构成搜索样本集。
23、较佳地,所述选择距离最小的前ks个存量数据样本,包括:
24、在所有实例特征与所有聚类中心的距离中,选择距离最小的前ks个存量数据样本;
25、或者,
26、对于每个聚类中心,在所有实例特征与该聚类中心的距离中,选择距离最小的前或个存量数据样本,n为聚类中心的个数。
27、较佳地,所述利用所述教师模型进行蒸馏处理,包括:
28、利用所述教师模型对所述蒸馏样本集中的样本进行处理,得到相应样本的伪标签,将所述初始学生模型或未训练的学生模型作为当前学生模型;
29、在每次蒸馏训练中,将蒸馏样本集中的本次蒸馏训练使用的样本分别输入所述教师模型和所述当前学生模型;
30、将所述教师模型主干的各层处理后的输出特征分别与所述当前学生模型主干的各层处理后的输出特征进行比较,生成中间层特征蒸馏损失;
31、将所述教师模型处理后的响应输出分别与所述当前学生模型处理后的响应输出进行比较,生成响应输出蒸馏损失;
32、基于所述中间层特征蒸馏损失、所述响应输出蒸馏损失和所述当前学生模型的目标任务的损失函数,确定所述当前学生模型本次训练得到的蒸馏训练损失;
33、基于所述蒸馏训练损失更新所述当前学生模型的参数,并基于更新后的当前学生模型进行下一次蒸馏训练,直到达到蒸馏训练结束条件。
34、一种模型蒸馏装置,包括:离线数据处理单元、初始训练单元、数据搜索单元和蒸馏训练单元;
35、所述离线数据处理单元,用于利用通识模型对不同领域的存量数据样本进行识别,得到对应的语义理解信息;
36、所述初始训练单元,用于利用目标任务的训练样本集训练生成教师模型;
37、所述数据搜索单元,用于利用所述通识模型对所述训练样本集中的训练样本进行识别,得到对应的语义理解信息;基于所述存量数据样本对应的语义理解信息和所述训练样本对应的语义理解信息,确定与所述训练样本语义相关的存量数据样本,构成初筛样本集;为所述初筛样本集中的存量数据样本和所述训练样本集中的训练样本确定其所包括各实例的实例特征;在所述初筛样本集中选择其实例特征与所述训练样本的实例特征的相似程度在指定范围内的存量数据样本,构成搜索样本集;
38、所述蒸馏训练单元,用于将所述搜索样本集和所述训练样本集作为蒸馏样本集,利用所述教师模型进行蒸馏训练,得到蒸馏后的学生模型。
39、较佳地,所述初始训练单元在利用目标任务的训练样本集生成教师模型时进一步生成初始学生模型;
40、在所述数据搜索单元和所述蒸馏训练单元之间,该装置进一步包括:
41、数据生成单元,用于基于所述教师模型和所述初始学生模型训练生成数据生成模型,以使所述教师模型对所述数据生成模型得到的生成数据样本的理解与所述初始学生模型对所述数据生成模型得到的生成数据样本的理解之间的差异超过设定的程度;将所述搜索样本集中的存量数据样本和/或所述训练样本集中的训练样本以及各样本的类别信息输入所述数据生成模型,得到生成数据样本,构成生成样本集合;
42、在所述蒸馏训练单元中,进一步将所述生成样本集合作为蒸馏样本集。
43、较佳地,在所述数据生成单元中,所述数据生成模型的损失函数为其中,所述为所述数据生成模型得到的生成数据样本,为所述教师模型对所述生成数据样本进行处理后得到的输出,所述为所述初始学生模型对所述生成数据样本进行处理后得到的输出,为所述目标任务模型训练的损失函数,i为所述生成数据样本的索引。
44、较佳地,所述语义理解信息包括样本中各实例的自然语义理解和位置信息;
45、在所述数据搜索单元中,确定与所述训练样本匹配的存量数据样本时,基于所述语义理解信息中的所述自然语义理解进行。
46、较佳地,在所述数据搜索单元中,所述为所述初筛样本集中的存量数据样本和所述训练样本集中的训练样本确定其所包括各实例的实例特征,包括:
47、基于所述存量数据样本和所述训练样本中各实例的语义理解信息的位置信息,提取各实例对应的图像块,再对相应的图像块进行特征提取,得到相应实例的实例特征。
48、较佳地,在所述数据搜索单元中,所述在所述初筛样本集中选择其实例特征与所述训练样本的实例特征的相似程度在设定范围内的存量数据样本构成搜索样本集,包括:
49、对所述训练样本的各实例的实例特征进行聚类,得到多个聚类中心;
50、计算所述初筛样本集中存量数据样本的各个实例的实例特征与每个聚类中心的距离,选择距离最小的前ks个存量数据样本构成搜索样本集。
51、较佳地,在所述数据搜索单元中,所述选择距离最小的前ks个存量数据样本,包括:
52、在所有实例特征与所有聚类中心的距离中,选择距离最小的前ks个存量数据样本;
53、或者,
54、对于每个聚类中心,在所有实例特征与该聚类中心的距离中,选择距离最小的前或个存量数据样本,n为聚类中心的个数。
55、较佳地,在所述蒸馏训练单元中,所述利用所述教师模型进行蒸馏处理,包括:
56、利用所述教师模型对所述蒸馏样本集中的样本进行处理,得到相应样本的伪标签,将所述初始学生模型或未训练的学生模型作为当前学生模型;
57、在每次蒸馏训练中,将蒸馏样本集中的本次蒸馏训练使用的样本分别输入所述教师模型和所述当前学生模型;
58、将所述教师模型主干的各层处理后的输出特征分别与所述当前学生模型主干的各层处理后的输出特征进行比较,生成中间层特征蒸馏损失;
59、将所述教师模型处理后的响应输出分别与所述当前学生模型处理后的响应输出进行比较,生成响应输出蒸馏损失;
60、基于所述中间层特征蒸馏损失、所述响应输出蒸馏损失和所述当前学生模型的目标任务的损失函数,确定所述当前学生模型本次训练得到的蒸馏训练损失;
61、基于所述蒸馏训练损失更新所述当前学生模型的参数,并基于更新后的当前学生模型进行下一次蒸馏训练,直到达到蒸馏训练结束条件。
62、一种计算机可读存储介质,其上存储有计算机指令,所述指令被处理器执行时可实现上述任一项所述的模型蒸馏方法。
63、一种电子设备,该电子设备至少包括计算机可读存储介质,还包括处理器;
64、所述处理器,用于从所述计算机可读存储介质中读取可执行指令,并执行所述指令以实现上述任一项所述的模型蒸馏方法。
65、由上述技术方案可见,本技术中,利用通识模型对不同领域的存量数据样本进行识别,得到对应的语义理解信息,以引入大量多领域的存量数据。利用通识模型对用于进行教师模型训练的训练样本进行处理,得到训练样本的语义理解信息;基于存量数据样本和训练样本的语义理解信息,选择与训练样本在语义理解上相匹配的存量数据样本构成初筛样本集,从而实现对大量存量数据的初筛。接下来,确定初筛样本集和训练样本集中的样本所包括各实例的实例特征,进而在初筛样本集中选择其实例特征与训练样本的实例特征的相似程度在指定范围内的存量数据样本,构成搜索样本集,用于进行蒸馏处理。通过上述方式,可以在多个不同领域的大量存量数据中,选择与训练样本语义相关、特征相似的存量数据参与蒸馏处理,从而快速低成本地扩充目标任务的训练样本,极大地扩张训练样本域,有效提升蒸馏后的学生模型在多场景下的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!