加速卡负载均衡调度方法、装置、通信设备及存储介质与流程
本技术涉及数据处理领域,特别涉及一种加速卡负载均衡调度方法、装置、通信设备及存储介质。
背景技术:
1、近些年伴随人工智能技术的发展,特别是深度学习领域,越来越多的新技术开应用于人们的生产、生活中。目前,ai已经在金融、医疗、工业制造及安防等等众多个领域实现了技术落地,而且应用场景也越来越丰富,引发了各个行业的深刻变革。未来ai的发展将是技术与产业的结合,实现ai技术赋能各行各业,解决痛点、创造价值、降本增效。
2、当前人工智能的大爆发正是由深度学习引起。深度学习就是用深度神经网络来自动学习对象特征,然后让深度神经网络具备识别对象的能力。而图像识别作为深度学习应用(如cnn,rnn)的重要方向,应用已越来越广泛。在智能驾驶、人脸识别、医学影像识别、工业质检等领域也都有较成熟的应用。
3、现实生产中,各种深度学习模型推理都是在ai芯片加速卡中完成,芯片加速卡是作为ai计算的算力基础存在(其中gpu卡是应用较多的一种)。实际应用中,单卡算力是有限的,当需要处理较多模型时往往需要多个加速卡一起工作,特别是针对边缘场景,但每个模型运行于哪一张卡中,需要人工指定,模型数量较多时,人工指定就会造成每个加速卡的使用频次不一致,其中一些卡一直使用,一些出现闲置,进一步造成各卡使用寿命不同,降低加速卡的使用效率,最终影响整机的整体性能。
技术实现思路
1、本技术实施例的目的在于提供一种加速卡负载均衡调度方法、装置、通信设备及存储介质,具体技术方案如下:
2、在本技术实施的第一方面,首先提供了一种加速卡负载均衡调度方法,所述方法包括:
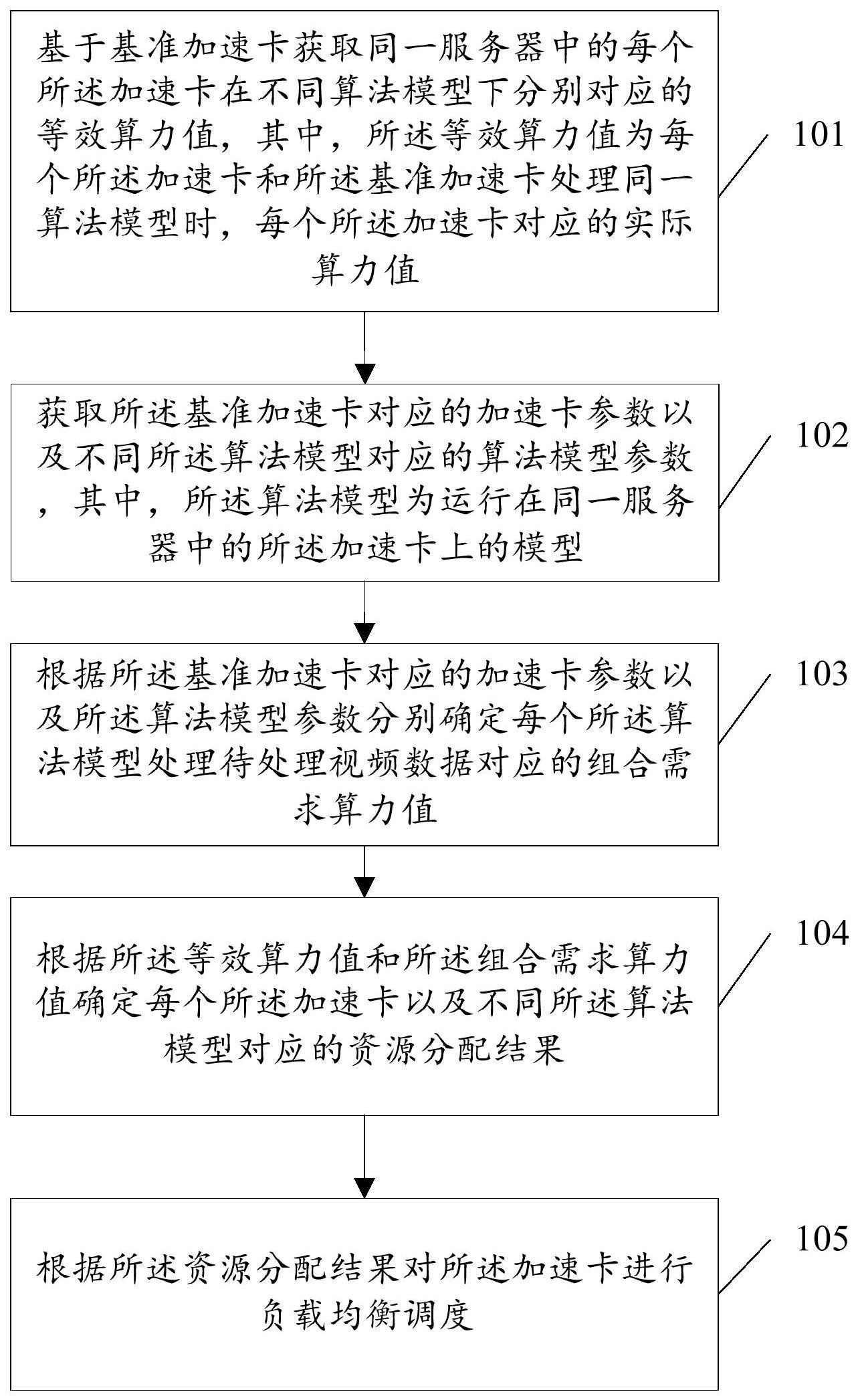
3、基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值;
4、获取所述基准加速卡对应的加速卡参数以及不同所述算法模型对应的算法模型参数,其中,所述算法模型为运行在同一服务器中的所述加速卡上的模型;
5、根据所述基准加速卡对应的加速卡参数以及所述算法模型参数分别确定每个所述算法模型处理待处理视频数据对应的组合需求算力值;
6、根据所述等效算力值和所述组合需求算力值确定每个所述加速卡以及不同所述算法模型对应的资源分配结果;
7、根据所述资源分配结果对所述加速卡进行负载均衡调度。
8、可选地,在所述基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值的步骤之前,所述方法包括:
9、确定算法调度引擎启动;
10、获取当前加速卡数量、模型数量以及视频接入数量;
11、判断所述加速卡数量、模型数量以及视频接入数量是否存在变化;
12、若否,则对视频数据进行业务分析,直至检测到新的
13、若是,则执行后续步骤,其中,所述后续步骤包括:基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值;
14、在所述根据所述等效算力值和所述组合需求算力值确定每个所述加速卡以及不同所述算法模型对应的资源分配结果的步骤之后,所述方法包括:
15、根据所述资源分配结果更新算力资源配置表,其中,所述算力资源配置表用于将资源分配结果反馈至所述算法调度引擎,以使所述算法调度引擎重新启动。
16、可选地,所述根据所述等效算力值和所述组合需求算力值确定每个所述加速卡以及不同所述算法模型对应的资源分配结果包括:
17、根据所述等效算力值和所述组合需求算力值基于装箱算法进行建模,得到算力资源分配模型;
18、基于所述算力资源分配模型确定每个所述加速卡对应的资源分配结果。
19、可选地,所述基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值包括:
20、基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值。
21、可选地,所述等效算力值通过以下公式生成:
22、
23、其中,f为任意一个所述加速卡在同一算法模型下对应的等效算力值,tk为任意一个所述加速卡在同一算法模型同一像素下单张图片推理时间,fb为所述基准加速卡对应的算力,tb为所述基准加速卡在同一算法模型同一像素下单张图片推理时间。
24、可选地,所述加速卡参数包括算力特性,所述基准加速卡对应的加速卡参数包括在给定参数时实验获取的目标算力值,所述算法模型参数包括算法模型类别、算法模型规模、推理图片精度、视频数量、模型数量以及每路视频处理帧数中至少一种;
25、所述根据所述基准加速卡对应的加速卡参数以及所述算法模型参数分别确定每个所述算法模型处理待处理视频数据对应的组合需求算力值包括:
26、根据所述给定参数时实验获取的目标算力值,以及,不同所述算法模型对应的算法模型类别、算法模型规模、推理图片精度、视频数量、模型数量以及每路视频处理帧数分别进行加权计算,得到每个所述算法模型处理待处理视频数据对应的组合需求算力值。
27、可选地,所述组合需求算力值通过以下公式生成:
28、
29、其中,其中,fc为每个所述算法模型处理待处理视频数据对应的组合需求算力值,τ表示由基准加速卡在给定参数mx,sx,fx实验获取的目标算力值,wc为每个所述算法模型和待处理视频数据组成的组合对应的组合权重,vc为算力效率。
30、在本技术实施的第二方面,还提供了一种加速卡负载均衡调度装置,所述装置包括:
31、第一获取模块,用于基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值;
32、第二获取模块,用于获取所述基准加速卡对应的加速卡参数以及不同所述算法模型对应的算法模型参数,其中,所述算法模型为运行在同一服务器中的所述加速卡上的模型;
33、第一确定模块,用于根据所述基准加速卡对应的加速卡参数以及所述算法模型参数分别确定每个所述算法模型处理待处理视频数据对应的组合需求算力值;
34、第二确定模块,用于根据所述等效算力值和所述组合需求算力值确定每个所述加速卡以及不同所述算法模型对应的资源分配结果;
35、调度模块,用于根据所述资源分配结果对所述加速卡进行负载均衡调度。
36、可选地,所述装置还包括:
37、确定模块,用于确定算法调度引擎启动;
38、第三获取模块,用于获取当前加速卡数量、模型数量以及视频接入数量;
39、第一判断模块,用于判断所述加速卡数量、模型数量以及视频接入数量是否存在变化;
40、第二判断模块,用于若否,则对视频数据进行业务分析;
41、第三判断模块,用于若是,则执行后续步骤,其中,所述后续步骤包括:基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值;
42、更新模块,用于根据所述资源分配结果更新算力资源配置表,其中,所述算力资源配置表用于将资源分配结果反馈至所述算法调度引擎,以使所述算法调度引擎重新启动。
43、所述第二确定模块包括:
44、第一确定子模块,用于根据所述等效算力值和所述组合需求算力值基于装箱算法进行建模,得到算力资源分配模型;
45、第二确定子模块,用于基于所述算力资源分配模型确定每个所述加速卡对应的资源分配结果。
46、可选地,所述第一获取模块包括:
47、第一获取子模块,用于取基准加速卡在处理同一算法模型时对应的基准算力值;
48、根据所述基准算力值和不同算法模型对同一服务器中的每个所述加速卡分别进行等效算力效果评估,得到每个所述加速卡在不同算法模型下对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值。
49、可选地,所述基准加速卡对应的加速卡参数包括在给定参数时实验获取的目标算力值,所述算法模型参数包括算法模型类别、算法模型规模、推理图片精度、视频数量、模型数量以及每路视频处理帧数中至少一种;
50、所述第一确定模块包括:
51、第三确定子模块,用于根据所述给定参数时实验获取的目标算力值,以及,不同所述算法模型对应的算法模型类别、算法模型规模、推理图片精度、视频数量、模型数量以及每路视频处理帧数分别进行加权计算,得到每个所述算法模型处理待处理视频数据对应的组合需求算力值。
52、在本技术实施的第三方面,还提供了一种通信设备,包括:收发机、存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序;
53、所述处理器,用于读取存储器中的程序实现如第一方面任一所述的加速卡负载均衡调度方法。
54、在本技术实施的第四方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机实现如第一方面任一所述的加速卡负载均衡调度方法。
55、本技术实施例提供的加速卡负载均衡调度方法,基于基准加速卡获取同一服务器中的每个所述加速卡在不同算法模型下分别对应的等效算力值,其中,所述等效算力值为每个所述加速卡和所述基准加速卡处理同一算法模型时,每个所述加速卡对应的实际算力值;获取所述基准加速卡对应的加速卡参数以及不同所述算法模型对应的算法模型参数,其中,所述算法模型为运行在同一服务器中的所述加速卡上的模型;根据所述基准加速卡对应的加速卡参数以及所述算法模型参数分别确定每个所述算法模型处理待处理视频数据对应的组合需求算力值;根据所述等效算力值和所述组合需求算力值确定每个所述加速卡以及不同所述算法模型对应的资源分配结果;根据所述资源分配结果对所述加速卡进行负载均衡调度。即本技术实施例中,可以应用于在边缘服务器/微服务器存在多种加速卡的场景下,首先对各加速卡进行等效算力评估,获取不同加速卡对应的等效算力值,然后依据每个不同加速卡的加速卡参数和算法模型参数获取每种算法组合(算法模型与视频的组合)所需算力,即组合需求算力值,最后把加速卡提供的算力资源(等效算力值)、各模型及视频组合所需的组合需求算力值进行处理得到合理的算力资源分配,以达到ai推理用时最少、推理等待时间最少的目的,实现整机推理效率最优,消除人工配置导致用卡不均衡的问题。并且,针对初始部署加速卡资源不够,后续再添加ai加速卡的场景,可以实现动态负载均衡,省去人工再配置的环节,只需简单安装即可。
- 还没有人留言评论。精彩留言会获得点赞!