推荐方法、模型训练方法、装置、设备及可读存储介质与流程
本发明涉及计算机应用,特别是涉及一种推荐方法、模型训练方法、装置、设备及可读存储介质。
背景技术:
1、个性化文本智能推荐系统,作为一种知识传递的助手、产生用户粘性的基础设施、增加用户点击率,不仅可以作为大型互联网公司的后台核心技术模块,也可以与搜索引擎融合或者作为单独的系统有效帮助用户可以在大量的文档中找到它们最感兴趣的描述,从而缓解信息过载问题,扩充视野。
2、现有的,大多数神经网络推荐方法,主要集中在设计各种巧妙的神经网络来编码文本和用户的表示,其中核心模块是文本编码器、用户编码器和相似性度量。虽然这些神经网络推荐方法可以实现个性化的文本推荐,但是,受神经网络模型本身的限制,推荐效果仍然无法满足用户需求。
3、综上所述,如何有效地解决文本个性化推荐等问题,是目前本领域技术人员急需解决的技术问题。
技术实现思路
1、本发明的目的是提供一种推荐方法、装置、设备及可读存储介质,将个性化文本智能推荐任务转换为基于多模板提示学习的掩码预测任务,从而推荐给用户感兴趣的内容。
2、为解决上述技术问题,本发明提供如下技术方案:
3、一种推荐方法,包括:
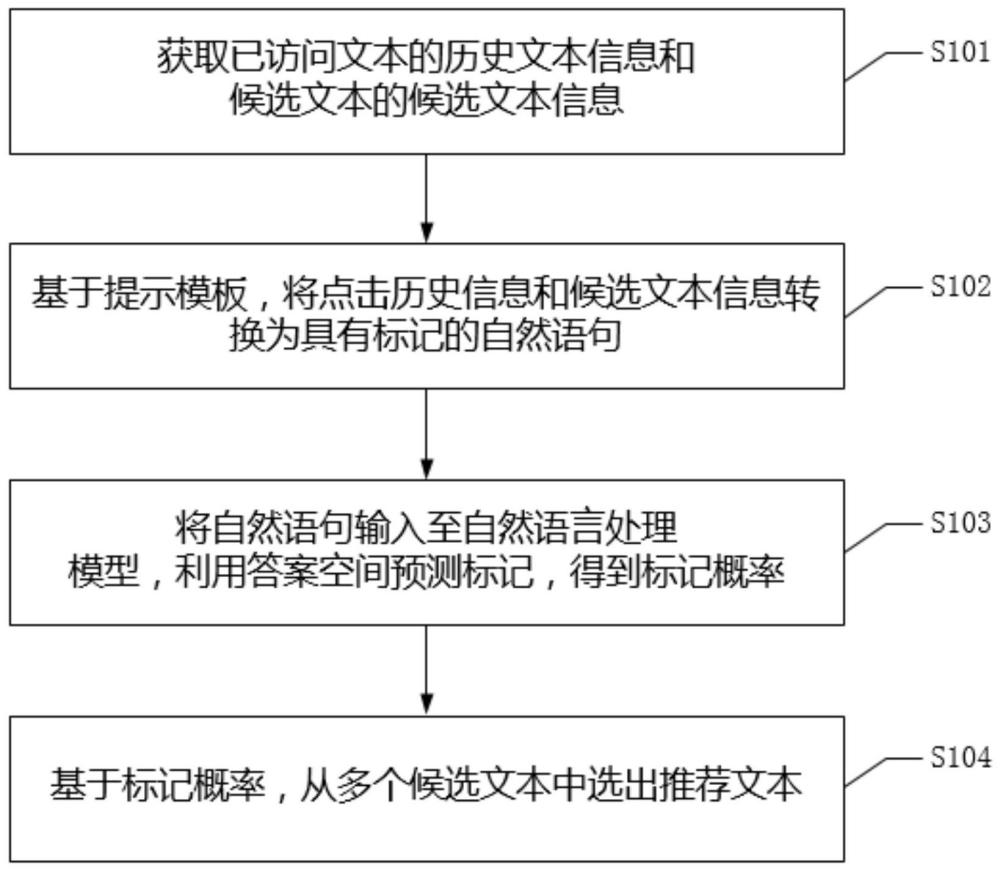
4、获取已访问文本的历史文本信息和候选文本的候选文本信息;
5、将所述历史文本信息和所述候选文本信息输入提示模板,得到回答词;
6、从所述回答词中选出标记,并将所述历史文本信息、所述候选文本信息和所述标记转换为自然语句;
7、将所述自然语句输入至自然语言处理模型,利用答案空间预测所述标记,得到标记概率;
8、基于所述标记概率,从多个所述候选文本中选出推荐文本。
9、优选地,获取已访问文本的历史文本信息,候选文本的候选文本信息,包括:
10、读取各个所述已访问文本的历史标题;
11、连接各个所述历史标题,得到所述历史文本信息;
12、读取所述候选文本的候选标题,并将所述候选标题确定为所述候选文本信息。
13、优选地,连接各个所述历史标题,得到所述历史文本信息,包括:
14、利用分割符号连接各个所述历史标题的单词序列,得到所述历史文本信息。
15、优选地,将所述历史文本信息和所述候选文本信息输入提示模板,得到回答词,包括:
16、将所述历史文本信息和所述候选文本信息输入离散提示模板进行完形填空,得到回答词。
17、优选地,将所述历史文本信息和所述候选文本信息输入离散提示模板进行完形填空,得到回答词,包括:
18、将所述历史文本信息和所述候选文本信息输入至多种所述离散提示模型进行完形填空,得到多个所述回答词。
19、优选地,将所述历史文本信息和所述候选文本信息输入离散提示模板进行完形填空,得到回答词,包括:
20、将所述历史文本信息和所述候选文本信息输入至语义相关提示模型进行语义相关性预测,得到与语义相关的回答词。
21、优选地,将所述历史文本信息和所述候选文本信息输入离散提示模板进行完形填空,得到回答词,包括:
22、将所述历史文本信息和所述候选文本信息输入至情感提示模型进行用户情感预测,得到用户情感相关的回答词。
23、优选地,将所述历史文本信息和所述候选文本信息输入离散提示模板进行完形填空,得到回答词,包括:
24、将所述历史文本信息和所述候选文本信息输入至用户行为提示模型进行用户行为预测,得到用户行为相关的回答词。
25、优选地,将所述历史文本信息和所述候选文本信息输入离散提示模板进行完形填空,得到回答词,包括:
26、将所述历史文本信息和所述候选文本信息输入至推荐效果提示模型进行推荐效果预测,得到推荐效果相关的回答词。
27、优选地,将所述历史文本信息和所述候选文本信息输入所述提示模板,得到回答词,包括:
28、将所述历史文本信息和所述候选文本信息输入具有随机虚拟词的连续提示模板,得到所述回答词。
29、优选地,将所述历史文本信息和所述候选文本信息输入所述提示模板,得到回答词,包括:
30、将所述历史文本信息和所述候选文本信息输入具有随机虚拟词的混合提示模板,得到所述回答词。
31、优选地,从所述回答词中选出标记,包括:
32、将所述回答词中的肯定回答词确定为所述标记。
33、优选地,将所述自然语句输入至自然语言处理模型,利用答案空间预测所述标记,得到标记概率,包括:
34、利用所述自然语言处理模型,将所述自然语句中的标签映射到预训练语言模型词汇表中的答案词,并预测所述答案词的概率;
35、将所述答案词的概率,确定为对应标记的标记概率。
36、优选地,基于所述标记概率,从多个候选文本中选出推荐文本,包括:
37、累加所述候选文本的标记概率,得到该候选文本的排序分数;
38、基于所述排序分数,从多个所述候选文本中选出所述推荐文本。
39、优选地,累加所述候选文本的标记概率,得到该候选文本的排序分数,包括:
40、累加所述候选文本同类提示模板输出的标记概率,得到所述排序分数。
41、优选地,累加所述候选文本的标记概率,得到该候选文本的排序分数,包括:
42、累加所述候选文本不同类提示模板输出的标记概率,得到所述排序分数。
43、优选地,基于所述排序分数,从多个所述候选文本中选出所述推荐文本,包括:
44、基于所述排序分数对多个所述候选文本进行排序,并将排序分数最大的候选文本确定为所述推荐文本。
45、优选地,还包括:
46、向客户端发送所述推荐文本。
47、一种模型训练方法,包括:
48、获取已访问文本的历史文本信息和候选文本的候选文本信息,以及所述候选文本被推荐后是否被访问的真实标签;
49、基于提示模板,将所述历史文本信息和所述候选文本信息转换为具有标记的自然语句;
50、将所述自然语句输入至待训练自然语言处理模型,利用答案空间预测所述标记,得到标记概率;
51、基于所述标记概率和所述真实标签,计算当前自然语言处理模型的损失值,并基于所述损失值对当前自然语言处理模型进行调优,直到完成训练,以便在如上述方法中使用训练得到的自然语言处理模型。
52、一种推荐装置,包括:
53、信息获取模块,用于获取已访问文本的历史文本信息和候选文本的候选文本信息;
54、提示转换模块,用于将所述历史文本信息和所述候选文本信息输入提示模板,得到回答词;从所述回答词中选出标记,并将所述历史文本信息、所述候选文本信息和所述标记转换为自然语句;
55、标记预测模块,用于将所述自然语句输入至自然语言处理模型,利用答案空间预测所述标记,得到标记概率;
56、推荐选定模块,用于基于所述标记概率,从多个所述候选文本中选出推荐文本。
57、一种电子设备,包括:
58、存储器,用于存储计算机程序;
59、处理器,用于执行所述计算机程序时实现上述推荐方法的步骤,或执行所述计算机程序时实现上述模型训练方法的步骤。
60、一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述推荐方法的步骤,或所述计算机程序被处理器执行时实现上述模型训练方法的步骤。
61、应用本发明实施例所提供的方法,获取已访问文本的历史文本信息和候选文本的候选文本信息;将历史文本信息和候选文本信息输入提示模板,得到回答词;从回答词中选出标记,并将历史文本信息、候选文本信息和标记转换为自然语句;将自然语句输入至自然语言处理模型,利用答案空间预测标记,得到标记概率;基于标记概率,从多个候选文本中选出推荐文本。
62、在本发明中,在获取了历史文本信息和候选文本信息之后,可以将历史文本信息和候选文本信息输入到提示模板中,从而得到回答词。然后,再从回答词中选出标记,并将历史文本信息、候选文本信息和标记转换为自然语句。然后,再将自然语句输入至自然语言处理模型,从而利用答案空间预测标记,并获得标记概率,最终,基于标记概率,从多个候选文本中选出推荐文本。
63、可见,在本发明中,通过提示模型,可以将历史文本信息和候选文本信息转换为具有标记的自然语句,可以充分利用真实世界大规模语料库的语言信息,并将个性化文本智能推荐任务转换为基于多模板提示学习的掩码预测任务,从而推荐给用户感兴趣的内容。
64、相应地,本发明实施例还提供了与上述推荐方法相对应的模型训练方法、推荐装置、设备和可读存储介质,具有上述技术效果,在此不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!