基于反馈强化的多模态知识生成方法及装置
本发明属于知识生成任务的,具体涉及一种基于反馈强化的多模态知识生成方法及装置。
背景技术:
1、目前基于人类反馈的模型微调方法主要为基于人类反馈的强化学习的单模态语言模型微调方法。基于人类反馈的强化学习的单模态语言模型微调方法目前只针对语言模型,将人工偏好的知识融入语言模型的训练之中,以此构造一个带有人类偏好的文本生成模型。在微调的过程中,采用强化学习的方法,通过对模型的输出结果进行评估,以及对人类反馈信息的分析,来指导语言模型的优化和调整。这种方法可以提高模型的性能和稳定性,同时也可以加强语言模型对人类语言的理解。基于人类反馈的强化学习的单模态语言模型微调方法可以学习语言模态的人类反馈信息,但是语言模型只能接受文本输出,生成文本知识,具有模态唯一的限制。而为了更加贴合人类的感知方式,要求模型同时接受语言和视觉的输入。此外,为了符合人类的需求,特定的领域任务中,需要模型生成语言知识和视觉知识。多模态知识生成旨在将不同模态的信息进行融合,并按照任务需求生成图像和文本内容。在多模态模型知识生成任务中引入人类反馈,并设计强化学习算法对模型进行微调是一项还待解决的难题。
技术实现思路
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于反馈强化的多模态知识生成方法及装置,在多模态模型知识生成任务中,引入关于多模态知识的人类反馈,设计训练奖励回报模型学习人类反馈,再使用内外探索的强化学习算法对多模态预训练模型进行微调,通过学习能够使其生成内容与人类偏好对齐。
2、为了达到上述目的,本发明采用以下技术方案:
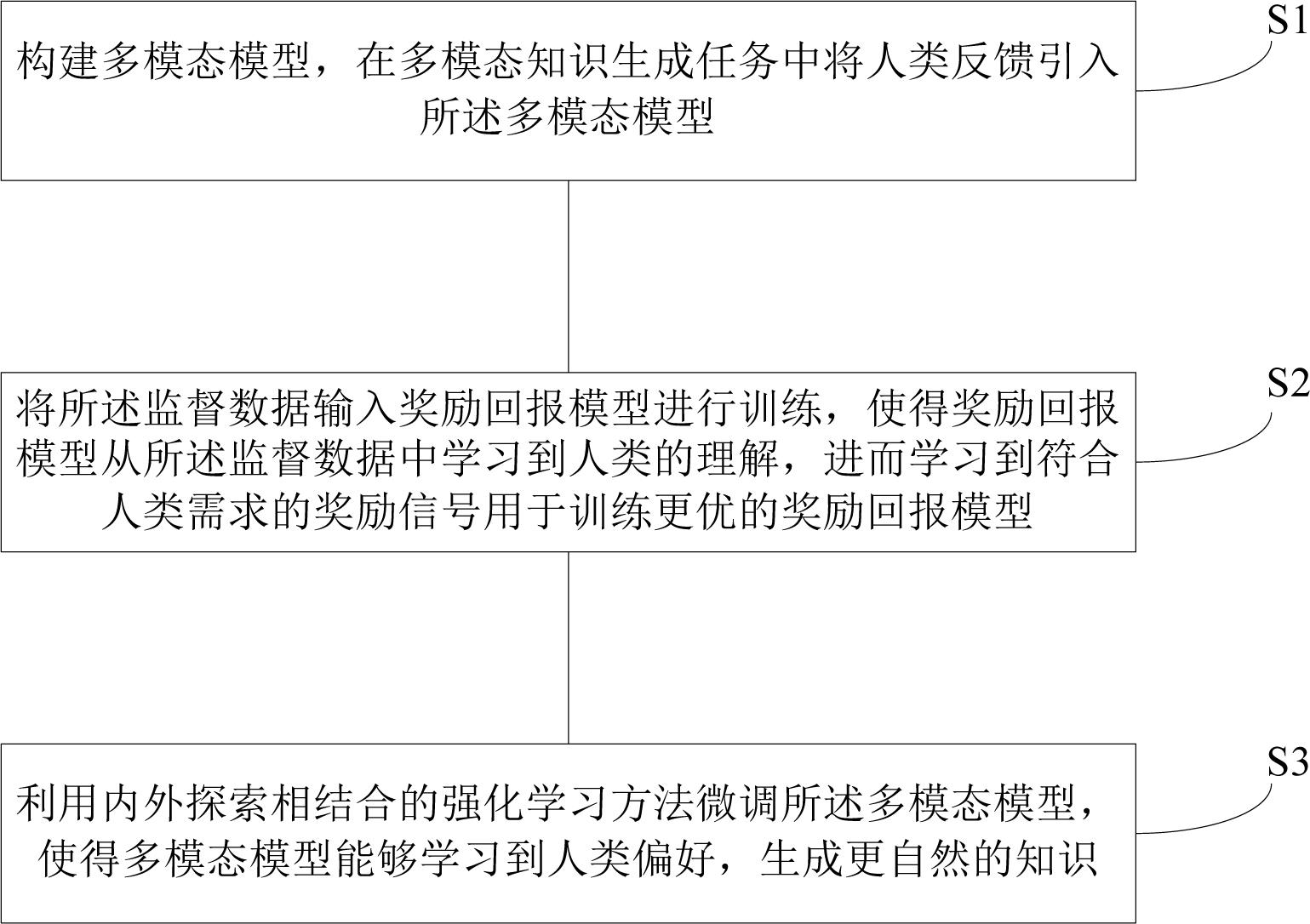
3、第一方面,本发明提供了一种基于反馈强化的多模态知识生成方法,包括下述步骤:
4、构建多模态模型,所述多模态模型的输入为文本信息和图像信息;在多模态知识生成任务中将人类反馈引入所述多模态模型,所述人类反馈为基于排序的人工打分机制,即为多模态模型的输出结果排序打分并进行标注,形成的监督数据用于训练预先设立的奖励回报模型;
5、将所述监督数据输入奖励回报模型进行训练,使得奖励回报模型从所述监督数据中学习到人类的理解,进而学习到符合人类需求的奖励信号用于训练更优的奖励回报模型;基于多模态排序的排序损失、模态间的分布损失及对比学习的相似度损失更新所述奖励回报模型;所述多模态排序的排序损失用于表征奖励回报模型对于多模态模型输出的k个答案在排序打分中靠前的答案给出更高的分数值;所述对比学习的相似度损失用于表征生成的同一组图-文多模态数据之间的相似性;所述模态间的分布损失用于表征多模态模型的多个输出在标注排序中位序的一致性;
6、利用内外探索相结合的强化学习方法微调所述多模态模型,使得多模态模型能够学习到人类偏好,生成更自然的知识;所述内外探索具体为:对于图像信息,使用内在奖励对于图像的生成进行激励,对于文本信息则采用样本层面的外在奖励,使得文本信息匹配图像信息;所述强化学习方法是在每一步生成过程中,根据当前的状态和策略,选择一个动作并执行,然后根据执行后的结果获得一个奖励信号,所述奖励信号用于调整多模态模型的策略。
7、作为优先的技术方案,所述多模态模型包括第一文本编码器、第一图像编码器、第一文本解码器和第一图像解码器,将文本信息和图像信息作为多模态模型的输入,第一文本编码器提取文本特征,得到第一文本编码,第一图像编码器提取图像特征,得到第一图像编码,再通过融合模型对齐文本和图像空间,最后通过第一图像解码器和第一文本解码器分别生成图像和文本。
8、作为优先的技术方案,所述奖励回归模型包括第二文本编码器和第二图像编码器,将多模态模型生成的图像和文本作为奖励回归模型的输入,经过第二图像编码器得到第二图像编码,经过第二文本编码器得到第二文本编码,然后在rm linear处引入人类反馈,得到最终的奖励回报模型的损失。
9、作为优先的技术方案,所述基于多模态排序的排序损失函数定义如下:
10、;
11、其中, x代表从微调数据集中采样出来的prompt, y代表图像打分分布, z代表文本打分分布,代表对于该prompt打分人员给出的排序序列中更好的答案,则代表排序序列中排序低的答案,代表奖励回报模型,其中θ是模型参数,d是数据集,k是每个batch中样本的数目;
12、所述基于模态间的分布损失函数定义如下:
13、;
14、其中, y代表图像打分分布, z代表文本打分分布,由于优化目标是最小化图像标注序列分布与文本标注序列分布之间的差异,所以这分布损失与目标优化方向一致;
15、所述对比学习的相似度损失函数定义如下:
16、;
17、其中 s( q i ,k i)是图像 q i和文本 k i的匹配分数,( q i ,k i)是匹配的图文对, s( q i ,k m)是图像 q i和文本 k m的匹配分数,在实现中把奖励模型分数最高的一对数据作为匹配的图文对。
18、作为优先的技术方案,所述奖励回报模型的训练过程如下:
19、从预训练数据集中采样prompt样本输入进预训练多模态模型,输出k个答案的文本和图像;
20、打分人员分别为文本和图像进行排序打分,形成排序标签数据用于训练奖励回报模型;
21、利用打分人员的标注数据,以回归监督的方式训练奖励回报模型,使得奖励回报模型对于图像与文本输出的奖励值序列与打分人员标注的排序序列一致。
22、作为优先的技术方案,所述利用强化学习微调多模态模型,具体为:
23、构建分布式强化学习训练框架,包括行动者、工作者、经验缓冲池和全局学习者,所述行动者负责与奖励回报模型交互,决策则由工作者负责,不同的行动者交互的奖励回报模型完全独立,工作者负责一定数量的行动者,当从行动者处获得信息后,工作者内置的前向智能体决策网络进行决策后将动作传递给行动者从而让行动者与奖励回报模型进行下一步的交互;但是,工作者中的前向智能体决策网络并不参与训练,而是定期从全局学习者中的训练网络中同步参数;所述经验缓冲池用于将行动者与奖励回报模型完成一轮交互后产生的轨迹数据存放,以用于给全局学习者训练使用;所述经验缓冲池内置的选择模块用于计算外在奖励的产生,即为每个轨迹数据计算优先级以及重要性因子;所述全局学习者不断的从中采样批量数据进行训练,并定期的将最近的网络参数通过共享内存同步给工作者中的智能体决策网络;
24、所述外在奖励是基于样本数据在探索空间内的优先级和样本数据的重要性因子计算得到;所述优先级用于计算样本数据在探索空间内的优先等级,优先级越大则说明样本数据的可利用价值越高,越应该多使用该样本训练模型从而加强模型的拟合能力;所述重要性因子则代表了该样本的重要性程度,从多方面权衡了样本的重要性,具体为利用次数、产生轮数差、累积折扣分数和文本长度;
25、所述内在奖励用于使得设立的内在奖励模型在图像空间中产生更多样的奖励信号丰富的图像内容。
26、作为优先的技术方案,所述内在奖励模型包括目标模块和预测模块;
27、所述目标模块是一个随机初始化并且固定参数的神经网络,接收图像输入后,输出一个分数奖励值,并且在确保图像输入不变的情况下,输出值是固定的;
28、所述预测模块用于计算当前图像输入的不确定性程度,即预测模块接收和目标模块相同的图像输入,输出一个分数奖励值,该分数奖励值随着神经网络的训练会发生变化。
29、第二方面,本发明提供了一种基于反馈强化的多模态知识生成系统,应用于所述的基于反馈强化的多模态知识生成方法,包括多模态模型构建模块、奖励回报模型训练模块以及多模态模型微调模块;
30、所述多模态模型构建模块,用于构建多模态模型,所述多模态模型的输入为文本信息和图像信息;在多模态知识生成任务中将人类反馈引入所述多模态模型,所述人类反馈为基于排序的人工打分机制,即为多模态模型的输出结果排序打分并进行标注,形成的监督数据用于训练预先设立的奖励回报模型;
31、所述奖励回报模型训练模块,用于将所述监督数据输入奖励回报模型进行训练,使得奖励回报模型从所述监督数据中学习到人类的理解,进而学习到符合人类需求的奖励信号用于训练更优的奖励回报模型;基于多模态排序的排序损失、模态间的分布损失及对比学习的相似度损失更新所述奖励回报模型;所述多模态排序的排序损失用于表征奖励回报模型对于多模态模型输出的k个答案在排序打分中靠前的答案给出更高的分数值;所述对比学习的相似度损失用于表征生成的同一组图-文多模态数据之间的相似性;所述模态间的分布损失用于表征多模态模型的多个输出在标注排序中位序的一致性;
32、所述多模态模型微调模块,用于利用内外探索相结合的强化学习方法微调所述多模态模型,使得多模态模型能够学习到人类偏好,生成更自然的知识;所述内外探索具体为:对于图像信息,使用内在奖励对于图像的生成进行激励,对于文本信息则采用样本层面的外在奖励,使得文本信息匹配图像信息;所述强化学习方法是在每一步生成过程中,根据当前的状态和策略,选择一个动作并执行,然后根据执行后的结果获得一个奖励信号,所述奖励信号用于调整多模态模型的策略。
33、第三方面,本发明提供了一种电子设备,所述电子设备包括:
34、至少一个处理器;以及,
35、与所述至少一个处理器通信连接的存储器;其中,
36、所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的基于反馈强化的多模态知识生成方法。
37、第四方面,本发明提供了一种计算机可读存储介质,存储有程序,所述程序被处理器执行时,实现所述的基于反馈强化的多模态知识生成方法。
38、本发明与现有技术相比,具有如下优点和有益效果:
39、本发明首次将具有人类反馈知识的强化学习方法应用于多模态知识生成任务中,解决了多模态知识生成任务缺乏人类反馈监督的不足,并引入基于内外探索相结合的强化学习微调技术,有效缓解多奖励稀疏问题。在面向特定领域的多模态生成任务中,首先引入人类对生成内容的评估信息,训练奖励回报模型,然后通过强化学习微调多模态模型,引导模型学习人类偏好,生成符合人类需求的结果。
40、本发明设计基于人类反馈的强化学习的多模态模型微调方法,在多模态模型知识生成任务中,引入关于多模态知识的人类反馈,设计训练奖励回报模型学习人类反馈,再使用内外探索的强化学习算法对多模态预训练模型进行微调。本方法主要尝试解决多模态模型引入人类反馈的强化学习算法的研究空缺,提升多模态模型知识生成的自然性、有效性和无害性。
- 还没有人留言评论。精彩留言会获得点赞!