基于多模态融合鸟瞰图的复杂道路目标检测方法
本发明涉及目标检测技术,具体涉及一种基于多模态融合鸟瞰图的复杂道路目标检测方法。
背景技术:
1、随着城市交通的不断发展和智能化水平的提升,车辆检测技术在智能交通系统中发挥着越来越重要的作用。车辆检测是指在交通场景中,利用计算机视觉技术自动识别和定位车辆的过程,是自动驾驶、交通监控、智能交通管理等领域的基础性任务之一。然而,由于现实交通场景的复杂性和多样性,传统的车辆检测方法面临着一系列挑战。
2、传统的车辆检测方法主要依赖于单一传感器数据,例如图像数据或点云数据。然而,单一传感器的数据存在着各自的局限性。图像数据在处理车辆遮挡、光照变化和天气影响等方面容易受到限制,而点云数据则难以处理细小车辆和车辆边界信息。因此,为了克服这些限制并提高车辆检测的准确性和鲁棒性,学术界和工业界开始探索将多传感器数据进行融合的方法。
3、在城市复杂路况中,车辆检测任务面临着多样化的场景,例如交通流量大、车辆多样性、遮挡等问题。目前,已有一些使用图像或点云数据进行车辆检测的方法,然而单模态的数据采集方式难以满足在复杂路况进行检测的需求。基于图像的检测方法对于遮挡和光照等因素较为敏感,而基于点云的方法则难以有效区分车辆与其他道路物体,且点云数据本身存在数据稀疏和噪声问题。
4、因此,如何充分融合图像和点云的信息,以提高车辆检测的准确性和鲁棒性,成为当前研究的热点和难点问题。目前已有相关技术方案,如下:
5、专利cn114155414a提出一种新型特征层数据融合的方法,该方法通过将激光雷达采集的点云投影到不同视图提取特征,结合相机图像的多尺度特征,叠加融合两类信息,同时,添加额外的点云和图像信息,最终将这些特征拼接融合。但是,该技术方案需要人工设置锚框尺寸与iou阈值等参数辅助模型进行回归计算,同时引入大量人工先验知识,容易存在误差检测精度不高。
6、专利cn114663514b提出一种基于多模态稠密融合网络的物体6d姿态估计方法,该方法利用rgb图像和点云信息,通过卷积神经网络提取表面特征,并与物体几何特征进行局部模态融合;通过多层感知机融合全局模态,进而进行实例分割和关键点处理,得到目标关键点,将物体的rgb图像和点云输入网络进行训练,并在待测场景中输入以获得物体的6d姿态估计结果。
7、专利cn116486368a提出一种自动驾驶场景下的多模态融合三维目标鲁棒检测方法,步骤包括:获取点云和图像数据;点云经特征提取网络转换为鸟瞰图特征;图像数据提取多尺度特征;鸟瞰图特征送入检测模块得初步目标检测;点云和图像特征与初步检测结果输入交错融合模块,自适应融合特征并微调目标检测。
8、但是,上述现有技术方案所用于特征提取训练的模型对数据集的依赖性较高,若外界条件不存在与训练集中,则检测能力较弱,不适应复杂环境。
9、专利cn114782787a提出一种点云与图像数据特征融合方法和装置,该技术方案以点云和图像作为输入,基于鸟瞰提取特征生成特征张量,再与像素级语义识别处理生成的特征张量进行融合,得到融合特征张量。该技术方案再提取特征过程中其点柱分辨率较低,无法提供更多空间特征,进而使用检测精度大打折扣。
技术实现思路
1、发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于多模态融合鸟瞰图的复杂道路目标检测方法,对齐不同传感器收集的异构型特征,并且能够有效利用多模态特征使各个传感器在检测任务中彼此互补,提高在复杂路况中的检测精度与鲁棒性。
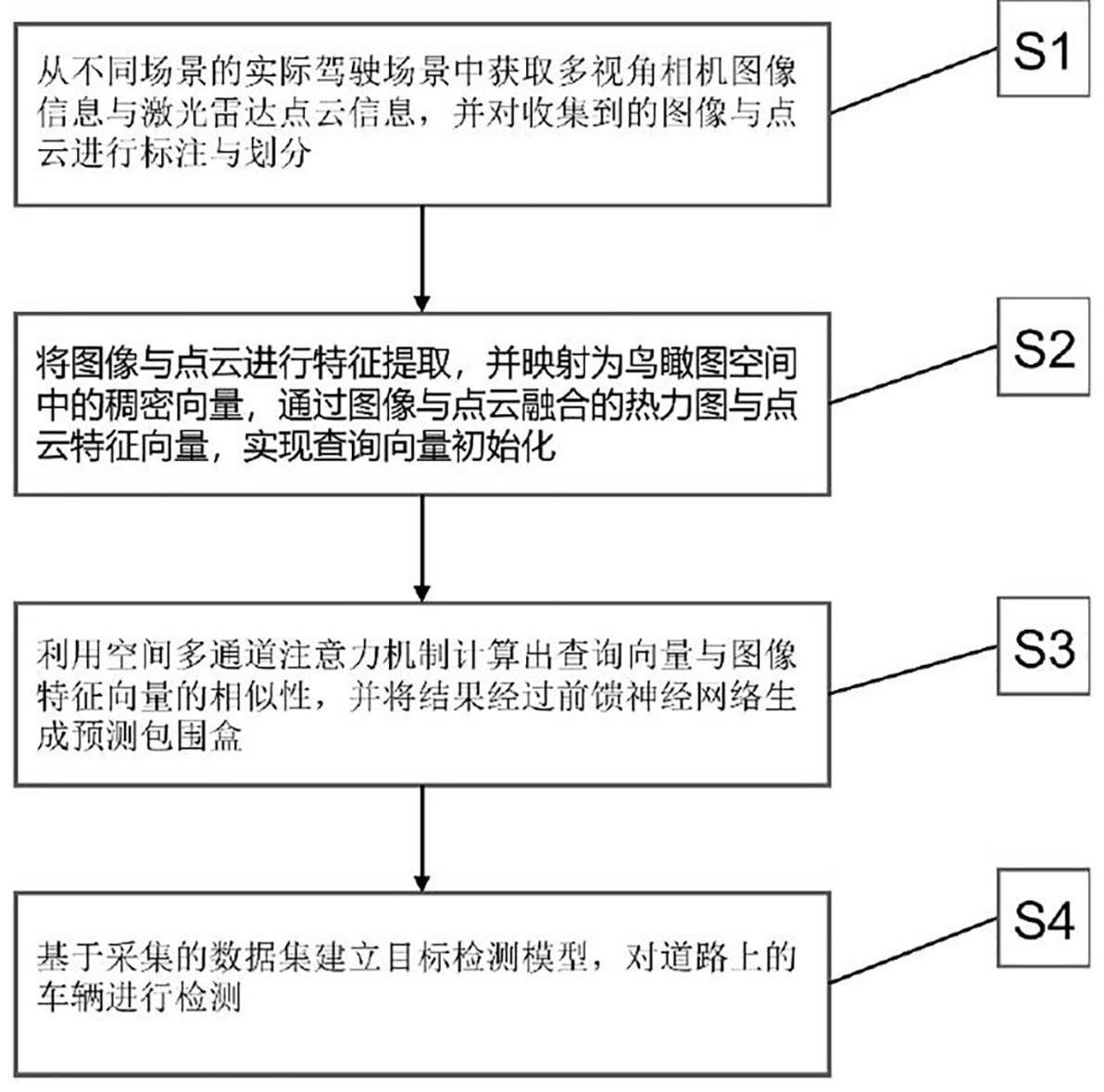
2、技术方案:本发明的一种基于多模态融合鸟瞰图的复杂道路目标检测方法,包括以下步骤:
3、步骤s1,从不同场景的实际驾驶场景中获取多视角相机图像与激光雷达点云,并对收集到的图像与点云进行标注与划分;
4、步骤s2,对图像与点云进行特征提取,并映射为鸟瞰图空间中的稠密向量,获取图像与点云融合的热力图与点云特征向量,实现查询向量初始化,具体方法为;
5、步骤s2.1、利用voxelnet网络对点云进行特征提取,得到点云鸟瞰图稠密向量;利用swin transformer模块对图像进行特征提取,并通过lift and splat操作得到图像鸟瞰图稠密向量;
6、步骤s2.2、通过将点云鸟瞰图稠密向量与图像鸟瞰图稠密向量用sigmoid函数激活并进行concat操作,得到基于鸟瞰图的融合特征稠密向量,再将其输入神经网络层得到融合特征热力图;
7、步骤s2.3、根据融合特征热力图中每个像素点的置信度,排序出预选框类别索引与位置索引,根据位置索引匹配点云特征,并将其存储为查询向量,实现查询向量初始化;
8、步骤s3、利用空间多通道注意力机制计算出查询向量与图像特征向量的相似性,并将相关性最强的位置的查询向量输入前馈神经网络,对目标的中心坐标、三维尺寸与偏航角进行预测形成包围盒;
9、步骤s4、基于采集的数据集建立目标检测模型,对道路上的车辆进行检测。
10、进一步地,所述步骤s1包括以下具体步骤:
11、从车辆的正前方、左前方、右前方、左后方、正后方与右后方的相机获取多视角相机图像信息,从车辆顶部的激光雷达中获取点云信息。
12、通过标签工具labelimg对部分的图像与点云中的目标进行框选与定义,划分为训练集与验证集,剩余的图像与点云划分为测试集。
13、进一步地,所述步骤s2.1中voxelnet网络提取点云特征的具体方法为:
14、步骤a)、将点云数据覆盖的三维空间范围剪裁为[x,y,z],设每个体素的大小分别为dx、dy和dz,基于这些参数构建出尺寸为h0=x/dx,w0=y/dy,d0=z/dz的体素网格;
15、步骤b)、在每个体素中随机采样n个点,体素中点的个数超过n则取n,不足则用0补全,使用随机采样可以减少计算量与采样偏差;
16、步骤c)、采样完成后对点云信息进行处理:由于每一个点云蕴含的信息为坐标x,y,z以及激光反射强度r,信息较为匮乏,先在体素特征编码层第一层拓展初始点云信息,通过对一个体素内采样的点云进行单元最大池化并且求差得到每个点云的偏差特征,然后用点云坐标与体素中心坐标求差得到距离特征,初始特征维度被拓展至10,但是依然无法满足检测需求,接着利用多层感知机(multilayer perceptron,mlp)将每个点的特征拓展至64维,通过单元最大池化获取体素的全局特征与每个点的局部特征进行拼接,每个点的特征被拓展至128维,最后通过最大池化得到体素特征,将n个非空体素堆叠在一起得到,最后的整体体素特征;
17、步骤d)、将特征进行你卷积与下采样操作得到稠密向量,点云数据的鸟瞰图稠密向量特征。
18、进一步地,所述步骤s2.2通过swin transformer模块获取图像鸟瞰图稠密向量以及融合特征热力图的具体方法为:
19、首先,将图像输入补丁分区层划分成16个补丁,每个补丁的宽高减少为原来图像的1/4,堆叠补丁使维度由3变为48;
20、然后,将堆叠后的补丁送入线性嵌入层,后续再经过四个阶段的补丁合并与swintransformer区块(对图像进行下采样,用于缩小分辨率,调整通道数进而形成层次化的设计),在补丁合并的过程中逐步提高特征提取的感受野,在由窗口自注意力机制与滑动窗口自注意力机制组成的swin transformer区块中,可使窗口之间的特征产生交互,使需要被提取的特征,能够借助周围特征提升自身分类能力;
21、最后,形成经过堆叠的swin transformer区块,将提取后的多视角图像特征通过lift and splat操作,生成伪深度并映射至鸟瞰图,得到图像鸟瞰图稠密向量,将点云鸟瞰图稠密向量与图像鸟瞰图稠密向量用sigmoid函数激活并进行concat操作,得到基于鸟瞰图的融合特征稠密向量,再将其输入神经网络层得到融合特征热力图。
22、进一步地,所述步骤s3计算由步骤2.3中初始化后的查询向量与图像鸟瞰图稠密向量的相似性时,先将查询向量的位置与对应图像特征的位置进行匹配,再将查询向量与图像特征向量输入空间多通道多头注意力机制的解码层,根据查询向量与图像特征的相关性,不断迭代更新查询向量。
23、进一步地,所述步骤s3将相关性最强的位置的查询向量输入前馈神经网络后,由于初始化的预测边界框数量通常大于原始数据集中标注的真实边界框数量,那么真实边界框选择哪一个预测边界框进行损失计算成为一个问题;本发明通过匈牙利算法对预测边界框分配最优的真实边界框:
24、记一系列真实目标边界框的标签为,为n个预测边界框参数,这两个集合中的最低成本二部匹配的最优分配可以定义为:
25、 (1)
26、其中是真实值与预测值的匹配成本,匹配成本需要考虑到预测框与真实框的相似性,令真实框中的每一个框和所有预测框进行匹配成本计算,计算公式为:
27、 (2)
28、其中为目标类标签,的概率为,预测框为;
29、通过计算目标类是真实类的概率,与预测框距真实框的位置偏差与尺寸偏差,得出匹配成本最小的预测框为该真实框的最佳匹配框,当所有真实框遍历完毕后,得到所有最佳匹配框;匹配完所有的预测框与真实框后,需要计算所有配对的匈牙利损失,与常规目标检测算法损失的定义类似,为分类损失、回归损失与iou损失的线性组合,公式为:
30、 (3)
31、其中用focalloss计算分类损失,用l1损失计算回归损失,用广义的iou损失计算iou损失;λ1、λ2、λ3是单个损失项的系数。
32、进一步地,步骤s4建立目标检测模型包括以下具体步骤:
33、步骤s4.1、对训练数据集进行mosaic数据增强、随机翻转、遮挡处理
34、步骤s4.2、选定深度学习预训练模型,采用随机梯度下降法进行训练,学习率为0.00005,指数衰减因子为0.8,epoch设为10,batch-size设为4,完成模型训练得到检测模型。
35、有益效果:与现有技术不同,本发明具有优点:
36、(1)本发明充分融合了图像和点云数据的信息,克服了传统单模态检测方法在复杂路况下特征利用的局限性,不需要人工设置锚框尺寸与iou阈值等参数辅助模型进行回归计算,免去人工先验知识的介入,更接近于端到端的检测。
37、(2)本发明通过利用swin transformer作为图像特征提取骨干网络,有效提高了对高分辨率大图像的特征利用,并且基于swin-transfomer进行特征提取使得训练完成的模型迁移能力较强,其次在提取的特征方面,通过切片补丁操作能有效提取长距离特征,不同于卷积核的滑动窗口仅能建立相邻区块的特征关联,因此使用该网络有助于使模型适应复杂环境。
38、(3)、本发明通过利用voxelnet作为点云特征提取骨干网络,有效提高了对于点云局部与全局特征的提取,将点云特征提取网络由pillarnet换为voxelnet,基于体素的特征提取方式相较于点柱分辨率更高,能有效提供更多空间特征提高检测精度
39、(4)本发明引入的注意力机制使得车辆检测方法更具鲁棒性,能够有效应对遮挡、光照等干扰因素。
40、(5)本发明还提出一种特殊的基于图像引导的查询向量初始化方式,实现了自适应特征融合,根据具体情况动态调整图像和点云的权重,提升了车辆检测的灵活性和精确性。
- 还没有人留言评论。精彩留言会获得点赞!