视频优化方法、装置、设备和存储介质与流程
本公开涉及人工智能和金融科技,尤其涉及视频优化方法、装置、设备和存储介质。
背景技术:
1、视频在金融科技领域的应用非常广泛,可以用于品牌推广、产品介绍、用户教育等方面。例如开发创新的金融产品或服务后,利用视频向用户介绍产品或服务的功能、优势和使用方法。通过生动、直观的视频演示,更好地展示产品的特点和实际应用场景,增强用户对产品的理解和兴趣。又比如金融产品通常涉及一些复杂的概念和操作流程,制作用户教育视频,包括操作指南、案例分析、解决问题的方法等,帮助用户更好地理解和使用金融科技产品。
2、相关技术中,为了提升视频的效果会对拍摄的视频进行优化,但是目前的神经网络模型多是针对视频本身给出优化建议,例如视频降噪、颜色校正等图像处理建议,这些模型更注中处理视频的视觉效果,而非基于视频内容来给出优化建议,导致视频优化效果不能满足实际需求。
技术实现思路
1、本技术实施例的主要目的在于提出视频优化方法、装置、设备和存储介质,针对视频内容提出优化建议,从而提升视频优化效果,满足优化需求。
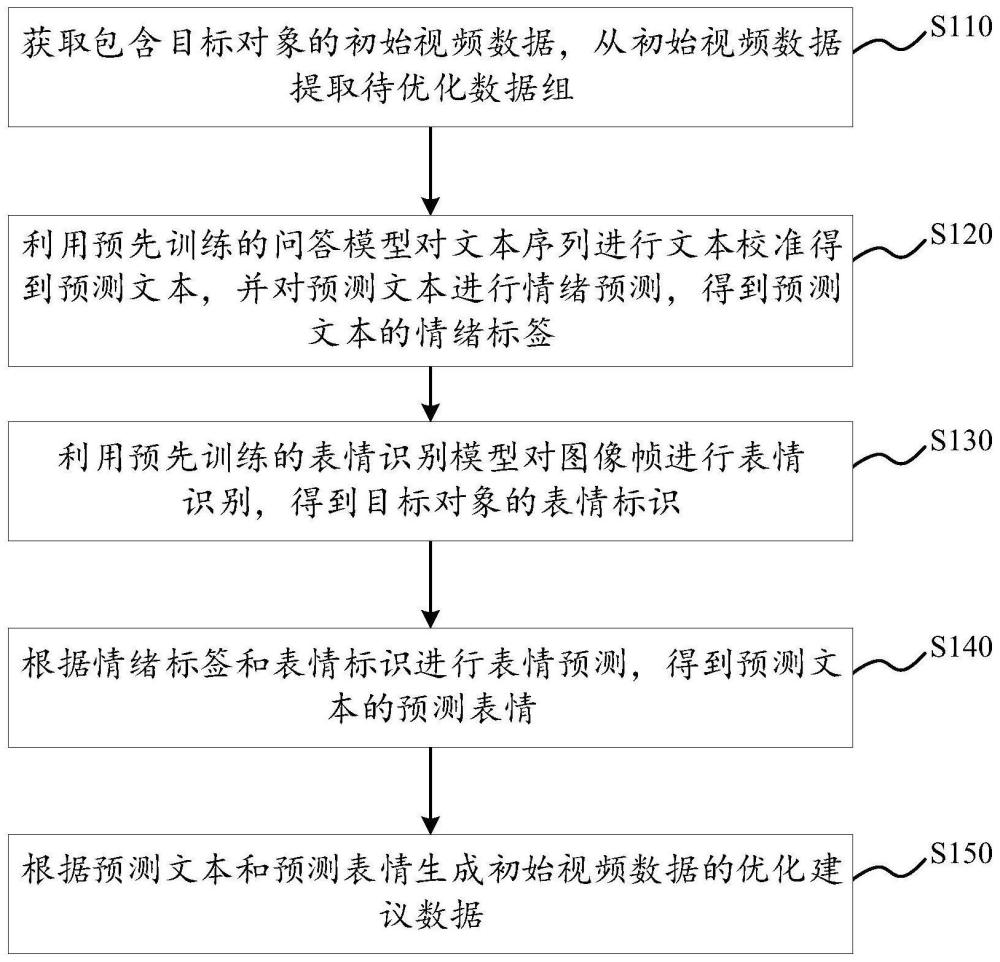
2、为实现上述目的,本技术实施例的第一方面提出了一种视频优化方法,包括:
3、获取包含目标对象的初始视频数据,从所述初始视频数据提取待优化数据组,所述待优化数据组包括:文本序列和图像帧;
4、利用预先训练的问答模型对所述文本序列进行文本校准得到预测文本,并对所述预测文本进行情绪预测,得到所述预测文本的情绪标签;
5、利用预先训练的表情识别模型对所述图像帧进行表情识别,得到所述目标对象的表情标识;
6、根据所述情绪标签和所述表情标识进行表情预测,得到所述预测文本的预测表情;
7、根据所述预测文本和所述预测表情生成所述初始视频数据的优化建议数据,其中,所述优化建议数据包括用于优化所述初始视频数据的建议方案。
8、在一些实施例,所述从所述初始视频数据提取待优化数据组,包括:
9、从所述初始视频数据提取出音频数据和图像数据;所述图像数据包括候选帧;
10、将所述音频数据转化为文本数据,并利用预先训练的文本分段模型将所述文本数据划分为文本序列;所述文本序列包含时序信息;
11、根据所述时序信息从所述候选帧中选取所述文本序列对应的所述图像帧。
12、在一些实施例,所述时序信息包括第一时序值和第二时序值,所述第一时序值小于所述第二时序值;所述根据所述时序信息从所述图像数据的多个所述候选帧中选取所述文本序列对应的所述图像帧,包括:
13、获取所述第一时序值与所述第二时序值之间的时间帧;
14、对所述时间帧进行平均计算,得到平均时间帧;
15、获取所述平均时间帧对应的所述候选帧作为所述图像帧。
16、在一些实施例,所述对所述预测文本进行情绪预测,得到所述预测文本的情绪标签,包括:
17、对所述预测文本进行分词,得到至少两个文本分词;
18、根据预设情绪词典获取每个文本分词对应的分词情绪,并对所述分词情绪进行统计得到情绪统计结果;
19、在所述情绪统计结果选取次数最多的所述分词情绪作为所述情绪标签。
20、在一些实施例,所述表情识别模型包括特征提取层、全连接层和输出层;所述利用表情识别模型对所述图像帧进行表情识别,得到所述图像帧中所述目标对象的表情标识,包括:
21、利用所述特征提取层对所述图像帧进行特征提取,得到图像表情特征;
22、利用所述全连接层对所述图像表情特征进行表情分类预测,得到每类表情的概率向量;
23、利用所述输出层对所述概率向量进行筛选,得到所述表情标识。
24、在一些实施例,所述根据所述情绪标签和所述表情标识进行表情预测,得到所述预测文本的预测表情,包括:
25、比较所述情绪标签和所述表情标识得到比较结果;
26、若所述比较结果表征所述情绪标签和所述表情标识一致,则将所述表情标识作为所述预测表情;
27、若所述比较结果表征所述情绪标签和所述表情标识不同,则根据情绪转移策略选取与所述表情标识对应的候选表情,并根据所述候选表情的关联信息选择目标表情作为所述预测表情;所述情绪转移策略包括候选表情以及不同所述候选表情之间的关联信息。
28、在一些实施例,所述若所述比较结果表征所述情绪标签和所述表情标识不同,则根据情绪转移策略选取与所述表情标识对应的候选表情,包括:
29、若所述比较结果表征所述情绪标签和所述表情标识不同,获取多个候选视频,每个所述候选视频包括至少一个表情帧,所述表情帧包括表情时序;
30、对所述表情帧进行表情识别,得到候选表情;
31、基于所述表情时序生成所述候选表情的转移信息,得到所述候选视频的情绪转移数据;
32、对所述情绪转移数据进行合并处理,得到情绪转移策略;
33、根据所述情绪转移策略选取与上一时序的所述表情标识对应的候选表情。
34、为实现上述目的,本技术实施例的第二方面提出了一种视频优化装置,包括:
35、初始视频数据模块:用于获取包含目标对象的初始视频数据,从所述初始视频数据提取待优化数据组,所述待优化数据组包括:文本序列和图像帧;
36、文本处理模块:用于利用预先训练的问答模型对所述文本序列进行文本校准得到预测文本,并对所述预测文本进行情绪预测,得到所述预测文本的情绪标签;
37、表情识别模块:用于利用预先训练的表情识别模型对所述图像帧进行表情识别,得到所述目标对象的表情标识;
38、表情预测模块:用于根据所述情绪标签和所述表情标识进行表情预测,得到所述预测文本的预测表情;
39、优化建议生成模块:用于根据所述预测文本和所述预测表情生成所述初始视频数据的优化建议数据,其中,所述优化建议数据包括用于优化所述初始视频数据的建议方案。
40、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的方法。
41、为实现上述目的,本技术实施例的第四方面提出了一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的方法。
42、本技术实施例提出的视频优化方法、装置、设备和存储介质,通过获取包含目标对象的初始视频数据,从初始视频数据提取文本序列和图像帧,利用预先训练的问答模型对文本序列进行文本校准得到预测文本,并对文本序列进行情绪预测,得到预测文本的情绪标签;利用预先训练的表情识别模型对图像帧进行表情识别,得到目标对象的表情标识;根据情绪标签和表情标识进行表情预测,得到预测文本的预测表情;再根据预测文本和预测表情生成用于优化初始视频数据的建议方案。本技术实施例对初始视频数据的文本序列和图像帧分别进行预测,得到预测文本和预测文本的预测表情,生成优化建议数据,这里的优化建议数据是根据视频内容中的文本和图像综合生成,用来提示目标对象进行视频优化,从而提升视频优化效果,满足优化需求。
- 还没有人留言评论。精彩留言会获得点赞!