一种融合关系选择和多尺度分布的小样本图像分类方法
本发明涉及小样本学习领域,特别是涉及一种融合关系选择和多尺度分布的小样本图像分类方法。
背景技术:
1、随着大数据时代的到来,深度学习模型已经在图像分类、文本分类等任务中取得了先进成果。但深度学习模型的成功,很大程度上依赖于大量训练数据。而在现实世界的真实场景下,某些类别只有少量数据或少量标注数据,而对无标签数据进行标注将会消耗大量时间和人力。与此相反,人类非常擅长通过极少量的样本识别一个新物体,比如小孩子只需要书中的一些图片就可以认识什么是“老虎”,什么是“大象”。在人类的快速学习能力的启发下,研究人员希望机器学习模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是few-shot learning要解决的问题。
2、目前小样本学习主要分为三大类别:基于迁移学习、基于度量学习和基于元学习。基于迁移学习已被广泛应用于许多领域,其是在一个经过预训练的基础网络上通过一定量的已标注数据进行微调。基于度量学习的方法主要是对样本间距离进行建模,使得在度量空间中同类样本紧凑异类样本远离。基于元学习方法旨在创建一个模型使得其可以适应多任务学习的场景,而对于小样本学习任务,由于每次的训练输入类别不一样,因此可以将每次的训练任务当成不同的学习任务,因此可以使用元学习的方法进行模型训练。
3、基于度量的小样本图像分类的核心思想是直接度量查询图像与支持图像之间的关系,从而学习可转移的特征嵌入。最近的一些工作表明,基于局部特征进行度量学习比基于图像级度量具有更加丰富的表示。例如li等人提出联合查询特征和支持特征的局部特征度量和全局特征分布度量进行度量学习,并且相比较实例级度量能更丰富的表示查询图像和支持样本之间的相似度信息。然而这种基于局部特征的度量学习存在关系重要程度一致的问题,并没有凸显众多局部特征中重要区域的相似度,抑制不重要区域的相似度。另外,在全局分布度量分支上也只是在原始特征上得到特征分布信息,这种单一尺度特征分布信息不能有效表示类的分布统计信息。
4、本发明提出新的模型结构,可以实现局部特征关系选择和更具代表性的全局特征分布。
技术实现思路
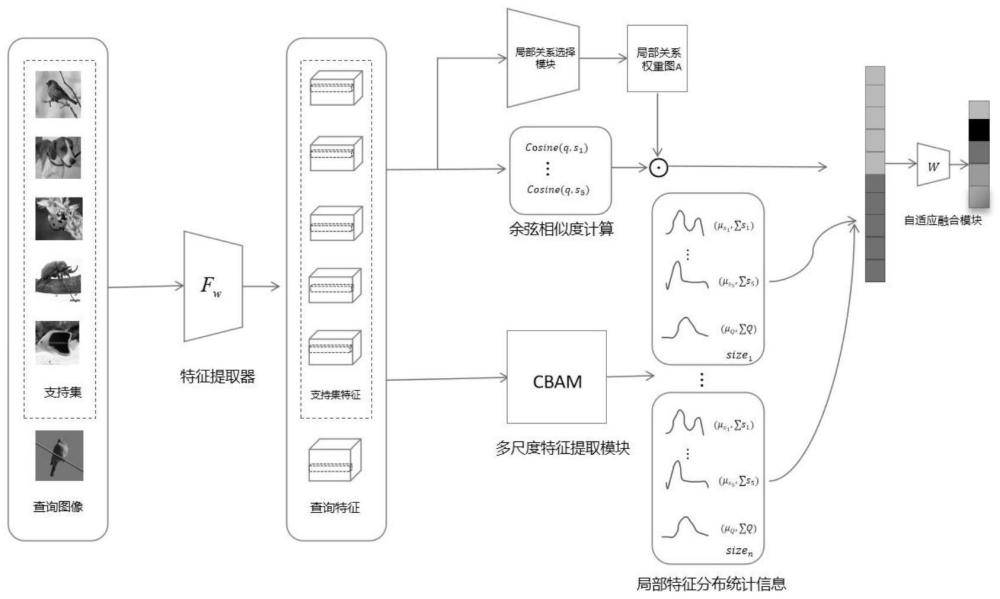
1、本发明提供一种融合关系选择和多尺度分布的小样本图像分类方法。该方法主要分为两大部分,第一部分围绕局部特征关系选择设计了一个全新模块用于关系筛选,自适应地对重要关系进行加权,抑制平凡关系。第二部分就是基于原始特征生成多尺度特征分布来衡量类的特征分布,融合不同尺度特征的分布信息来缓解单一尺度特征分布不具代表性的问题。实验结果表明,该方法比基准具有更高的准确率。
2、一种融合关系选择和多尺度分布的小样本图像分类方法,其步骤如下:
3、步骤(1)、数据集获取和建立,采用公共数据集miniimagenet。在小样本学习场景下,将数据集分为三个集合,训练阶段的支持集、查询集,以及测试阶段的辅助集。
4、步骤(2)、采用conv-64f作为特征提取器,将rgb图像输入该特征提取器得到初始特征对fq,fs。
5、步骤(3)、将初始特征对fq,fs分别输入到局部关系选择度量分支和全局特征分布度量分支。局部关系选择度量分支通过关系选择模块自主加权求和查询图像与支持类的局部关系,得到查询图像初步预测分数ⅰ;全局特征分布度量分支基于局部特征的统计信息来衡量查询图像与支持类之间分布的差异性,得到查询图像初步预测分数ⅱ;
6、步骤(4)、将步骤(3)两种策略下分别得到的查询图像初步预测分数ⅰ、ⅱ进行合并,再输入到自适应融合层,得到查询图像属于各个类别的最终分数。
7、步骤(5)、最大分数对应的类别即为预测类别,与查询图像对应真实样本图像类别计算交叉熵损失函数并进行梯度回传更新模型参数。
8、进一步的,步骤(1)中支持集和查询集共享相同的标签空间,与一般分类任务不同的是支持集和查询集都用于训练阶段。如果支持集s包含n类,每个类别包含k(例如1或5)个样本,则称这个小样本分类任务为n-way k-shot。需要说明的是,支持集在每个类中只有少量样本,对于一般分类任务是无法训练一个有效的深度学习网络。因此,通常引入辅助集作为测试阶段使用来学习可转移知识。与一般分类任务最大不同的是,一般辅助集比支持集拥有更多的类别且与支持集的标签空间不重叠。
9、步骤(2)、特征提取网络采用的是conv-64f,该结构包含4个卷积块,每个卷积块包含conv2d、batchnorm2d、relu、maxpool2d处理过程。该特征提取网络为rgb图像提取丰富的局部特征fω,具体公式表达如下:
10、
11、其中,fω是一个三维特征矩阵,ω表示网络参数。将fω(x)看成c×n个局部特征组成的特征矩阵,xi表示特征矩阵中第i个局部特征,c表示特征通道数,n表示局部特征数目,也就是n=w×h,w、h分别表示特征矩阵的宽和高。对于每一个支持类,该类中所有图像都映射到空间中用来表示该类的原始特征分布情况,对于每个查询图像,n个局部特征用来估计该查询图像在空间中的分布。
12、步骤(3)中对于局部关系选择度量分支,本发明设计了一个局部关系选择模块。局部关系就是查询图像在空间中每个特征向量与查询集某一类在空间中所有局部特征之间的余弦相似度,取最大值即为该局部特征与该支持类的余弦相似度。更进一步说,对查询图像的所有局部特征进行类似操作,得到该查询图像属于该类的原始余弦相似度分数ⅰ,具体公式表达如下:
13、
14、其中,s表示支持集某一类所有样本,k1表示该类样本数量,q表示待预测的查询图像。topk(.)表示从某一类所有样本s中选择k个最高相似度分数作为q在某一处局部特征与该类的相似度,local表示局部关系选择度量分支。预测的查询图像q中n个局部特征计算的相似度分数之和,即就是该待预测的查询图像q属于s类别的分数值。
15、待预测的查询图像q的n个局部特征并不能完全代表图像前景特征,可能有背景特征干扰。因此,该发明设计了一个局部特征关系选择模块用于对这n个局部特征相似度进行加权求和,自适应选择前景特征对应的重要关系,抑制背景特征对应的平凡关系,而不是公式2中的简单求和。
16、局部特征关系选择模块的输入是特征提取模块得到的特征对fq,fs,输出的是待预测的查询图像q对应的相似度权重图aq。首先使用1*1卷积核对特征对fq,fs进行降维,即通道数c转为c',降维后特征对变为接着计算降维后特征对的余弦相似度公式如下:
17、
18、其中,x表示特征图的局部特征,xq表示查询图像的局部特征,xs表示支持集某一类图像的局部特征;sim(.,.)表示两个局部特征之间的余弦相似度。然后将余弦相似度输入到由两层四维卷积的模块得到优化后的相似度张量目的是消除不可靠的相似度,将优化后的相似度张量计算相似度权重图aq。aq揭示了查询图像各个局部特征在衡量查询图像属于某一类可能性的权重,具体公式表达如下:
19、
20、其中,xq表示查询图像的局部特征,γ表示温度系数,表示查询图像的各个局部特征在与支持集某一类样本图像的局部特征xs计算相似度时重要程度,即相似度权重图。接着,对查询图像和支持集某一类样本图像计算的原始余弦相似度分数ⅰ(公式2)进行加权求和,具体公式表达如下:
21、
22、其中,公式5中simlocal表示基于局部关系选择得到查询图像属于某一个类别的分数。
23、下面,在详细介绍下步骤(3)所述的全局特征分布度量分支。
24、全局特征分布度量分支主要功能是基于局部特征统计信息得到查询图像和支持集的特征分布统计信息,来衡量查询图像与某一支持类特征分布差异。本发明采用卷积注意力机制模块在输入特征图上串行执行通道级注意力、空间级注意力。具体来说,给定特征提取器提取的特征对fq,fs,通道级注意力模块得到各个通道的权重关系。通道注意力模块首先通过全局平均池化和全局最大池化进行空间压缩得到两个权重张量接着将两个权重张量合并通过多层感知器(mlp)得到通道注意力权值wc,具体公式表达如下:
25、
26、其中,公式6中ωc表示多层感知器mlp参数,δ表示sigmoid激活函数,进一步得到通道级注意力图表示元素级乘法,f表示输入的特征fq,fs。空间注意力模块(swa)利用最大池化和平均池化对通道进行压缩得到两张权值图然后通过1*1层卷积将两张权值图融合得到空间注意力权重图ws,具体公式表达如下:
27、
28、其中,c表示1*1卷积层,ωs表示卷积层参数,cat表示连接操作。接着,得到最终细化的特征图即
29、将特征提取器提取的特征对fq,fs,即将查询图像对应的特征fq,支持集对应的某一类特征fs输入到卷积注意力机制模块提取不同尺度特征,本发明采用21*21,15*15,10*10,7*7作为输出特征尺度集l。对于某一种尺度,分别计算出查询图像特征fq和支持集某一类特征fs的分布统计信息。假设服从高斯分布,查询图像特征分布服从支持集某一类的特征分布服从其中分别表示均值向量和协方差矩阵。利用kl散度计算查询图像与支持集某一类在某一尺度下特征分布的相似程度,将所有尺度下的特征分布相似度进行求和得到基于多尺度特征分布度量结果,具体公式表达如下:
30、
31、
32、其中,公式8中表示在尺度i下fq与fs的kl散度,i∈l。simglobal表示所有尺度下查询图像与支持集某一类之间分布相似度之和。
33、对于步骤(4),基于以上两种策略得到的相似度分数,本发明设计一个自适应融合模块将这两种策略得到的分数进行自适应加权求和。该融合模块采用一个可学习的二维权值向量[ω1,ω2],来实现自主加权两种分数,具体公式表达如下:
34、sim=ω1.simlocal+ω2.simglobal (公式9)
35、公式9中ω1、ω2是可学习参数,sim表示自适应融合两种策略预测结果得到查询图像最终的预测结果。
36、本发明有益效果如下:
37、本发明提出了一种全新的小样本度量学习方法,使用局部特征进行度量学习。相较于之前基于实例级度量,局部特征度量具备更丰富的表示。在此基础上,本发明设计了两种具体度量方式,即特征关系选择度量和特征分布度量。特征关系选择度量利用余弦相似度计算所有查询局部特征与支持集某一类局部特征之间最优相似度之和来衡量查询图像与支持类之间的相似程度。查询特征并不是每个位置的相似度分数都重要,对于前景特征需要加强,背景特征需要弱化。鉴于此,本发明设计了一个局部关系选择模块用来增强前景特征对应的分数,抑制背景特征对应的分数。局部关系选择策略关注的是局部信息,而特征分布度量策略关注的是查询图像和支持类的全局特征分布信息。特征分布度量方式通过计算查询特征和支持类特征的分布统计信息,利用kl散度来衡量查询图像和某一支持类图像之间分布差异性进而得出查询图像的预测分数。单一尺度分布并不能有效衡量特征分布情况,因此本发明基于特征分布度量策略融合了卷积注意力机制模块(cbam)。目的是为了对原始特征提取多尺度特征,增强原始特征空间语义信息并且使得特征分布更具代表性。为了自适应融合两种度量分数,本发明设计一个自适应融合模块对以上两种策略结果进行自适应加权融合得到最终相似度分数。本发明在公共数据集上的实验结果比现有方法效果更好。
- 还没有人留言评论。精彩留言会获得点赞!