本发明涉及自然语言处理,具体涉及基于全局结构特征融合的篇章级文本分类方法,还涉及应用这种方法的篇章级文本分类系统。
背景技术:
1、随着互联网的普及和不断的发展,越来越多用于向公众展示信息的网站上线,职能部门倾向于在网站中披露一些重要信息,例如企业的处罚信息、招投标信息、排行榜信息、评级信息等。由于缺乏统一的相关披露规范,各级职能部门的信息披露格式也大有不同,表格、文本相互杂糅在一起。除了披露格式外,信息的披露形式也多种多样,包括各种附件,如pdf、excel、doc等等。甚至于,同种类别的信息,都可能披露在各级职能部门的不同栏目下,因为栏目也是各级职能部门自定义的。信息披露的不规范,极大的增加了用户获取目标信息的难度。特别是在数据爆炸式增长的时代,海量的数据混杂在一起,如何快速的获取目标信息,是亟待解决的问题所在。
2、传统的人工分类,需要对各级职能部门的不同栏目进行分类标记,工作量非常巨大,耗时耗力,一旦网站改版,则需要重新进行分类标记,并且也很难监控到网站是否改版。对于同一栏目下的不同类别的信息,则无法进行区分。另外,传统的正则分类,需要统计不同类别的相应关键词,容易出现错漏,相互冲突的情况,限制了正确率的提升。一般的深度学习分类方法,受限于预训练模型的长度限制,模型处理的文本信息较少,并且没有利用文本结构的特征信息,也会限制文本分类正确率的提升。
3、因此,亟待解决现有技术中文本分类的准确性较低的问题。
技术实现思路
1、为了避免和克服现有技术中存在的技术问题,本发明提供了基于全局结构特征融合的篇章级文本分类方法及系统。本发明通过在进行文本分类时,利用整个文本的篇章信息,基于全局结构特征融合,从而得到更加有效的篇章级文本特征表示,提高文本分类的准确性。
2、为实现上述目的,本发明提供如下技术方案:
3、本发明公开基于全局结构特征融合的篇章级文本分类方法,包括以下步骤,即s1~s4。
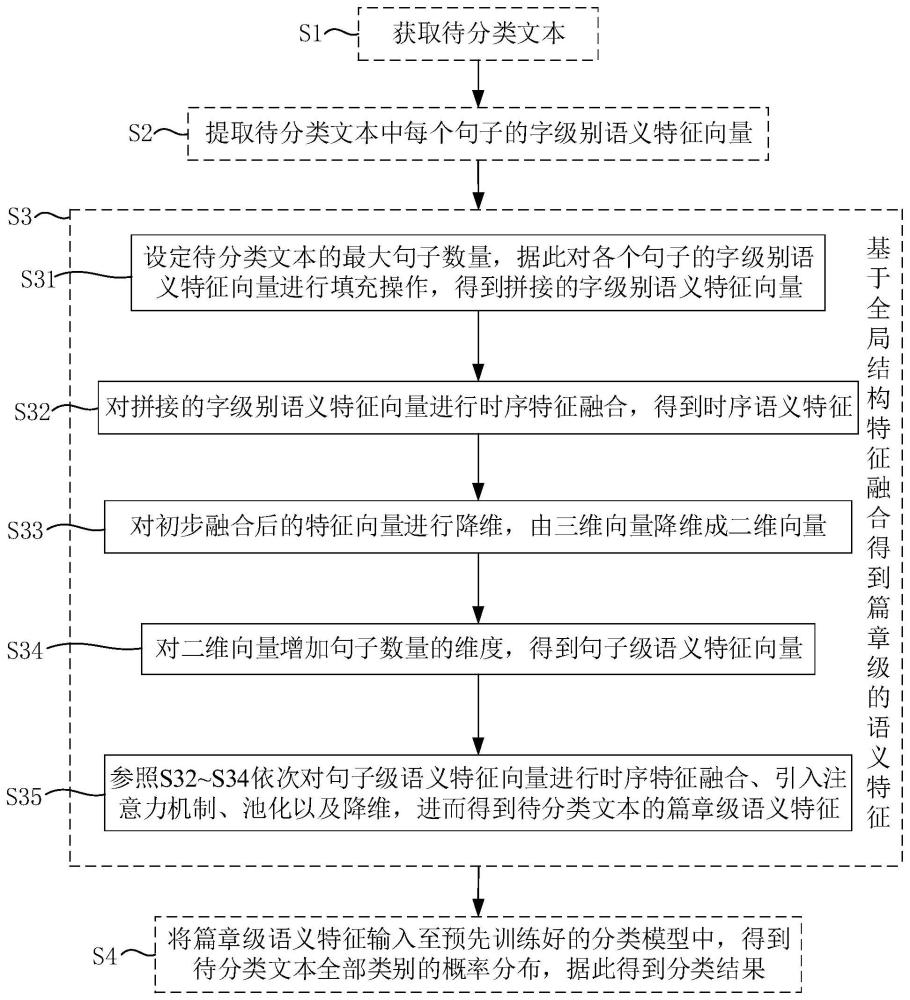
4、s1.获取待分类文本。
5、s2.提取待分类文本中每个句子的字级别语义特征向量。
6、s3.基于全局结构特征融合得到篇章级的语义特征:先对每个句子的字级别语义特征向量分别进行特征融合,得到每个句子的句子级语义特征向量;再对待分类文本中每个句子的句子级语义特征向量进行特征融合,得到待分类文本的篇章级语义特征。
7、s4.将篇章级语义特征输入至预先训练好的分类模型中,得到待分类文本全部类别的概率分布,据此得到分类结果。
8、作为上述方案的进一步改进,步骤s2包括以下具体步骤,即s21~s23。
9、s21.对待分类文本进行预处理,以将文本的处理粒度改为句子级。
10、s22.将预处理后的待分类文本分割成若干句子,构建句子级文本集合。
11、s23.设定句子级别的最大句子长度,并按照该长度对句子级文本集合中的每个句子的字/词进行语义特征提取,得到每个句子的字级别语义特征向量。
12、作为上述方案的进一步改进,s3包括以下具体步骤,即步骤s31~s36。
13、s31.设定待分类文本的最大句子数量,据此对各个句子的字级别语义特征向量进行填充操作,得到拼接的字级别语义特征向量。
14、s32.对拼接的字级别语义特征向量进行时序特征融合,得到时序语义特征。
15、s33.对时序语义特征添加注意力机制并进行一次池化操作,得到初步融合后的特征向量。
16、s34.对初步融合后的特征向量进行降维,由三维向量降维成二维向量。
17、s35.对二维向量进行维度变化,增加句子数量这个维度,得到句子级语义特征向量。
18、s36.参照步骤s32~s34的方式依次对句子级语义特征向量进行时序特征融合、引入注意力机制、池化以及降维,进而得到待分类文本的篇章级语义特征。
19、作为上述方案的进一步改进,步骤s32中,采用添加gru即门控循环单元的方法对拼接的字级别语义特征向量进行时序特征融合,得到时序语义特征。
20、作为上述方案的进一步改进,待分类文本的格式为html文本。步骤s21中,预处理包括:
21、将文本中附件形式的文本信息替换为该附件的文件名。
22、将文本中的大段文本间隔标签替换为句号,并将文本中剩余的其他html标签统一替换成空。
23、作为上述方案的进一步改进,步骤s23中,采用albert-base预训练模型对每个句子的字/词进行语义特征提取。预训练模型的权重在训练过程中为冻结状态,不参与微调迭代更新。
24、作为上述方案的进一步改进,步骤s4中,分类模型的训练方法包括以下步骤,即(1)~(4)。
25、(1).构建文本分类数据集h,并在将该数据集中的数据进行随机排序后按照预设比例划分为训练集、验证集和测试集。文本分类数据集h由篇章级文本的样本集合ω以及样本所对应实际类别的标签集合λ构成。
26、(2).参照步骤s2~s3的方式依次得到样本集合ω中的每个文本的篇章级语义特征。
27、(3).选用softmax作为计算文本类别概率分布的激活函数,并选用交叉熵函数作为损失函数,采用反向传播和梯度下降的方式实现训练,优化方向是使交叉熵函数的值变小。
28、(4).设置最大迭代次数,并将每个文本的篇章级语义特征作为输入以计算文本类别的概率分布,以此对分类模型进行训练。其中,在训练过程中,每一次迭代结束后计算一次micro-f1值,并与历史保存的最大micro-f1值比较,若比历史保存的大,则保存本次训练的参数文件以及micro-f1值,否则直接进行下一次迭代,直到最大迭代次数后停止训练。
29、作为上述方案的进一步改进,文本类别概率分布的计算公式为:
30、
31、式中,为文本类别概率分布。wp为概率分布的权重矩阵。bp为概率分布的偏置向量。表示每个文本的篇章级语义特征。
32、作为上述方案的进一步改进,交叉熵函数的表达公式为:
33、
34、式中,n表示在文本分类数据集h中划分为训练集的数据个数。表示训练集中第i条数据的实际类别标签所对应的概率值。
35、作为上述方案的进一步改进,步骤(3)中,通过adam优化算法实现梯度下降。
36、本发明还公开基于全局结构特征融合的篇章级文本分类系统,其应用上述基于全局结构特征融合的篇章级文本分类方法。分类系统包括:获取模块、语义特征提取模块、语义特征融合模块和计算模块。
37、获取模块用于获取待分类文本。
38、特征提取模块用于提取待分类文本中每个句子的字级别语义特征向量。
39、特征融合模块用于基于全局结构特征融合得到篇章级的语义特征。
40、计算模块用于将篇章级语义特征输入至预先训练好的分类模型中,得到待分类文本全部类别的概率分布,据此得到分类结果。
41、与现有技术相比,本发明的有益效果是:
42、1、本发明公开的基于全局结构特征融合的篇章级文本分类方法,通过字、句级别的分割策略,有效提取整篇文本的语义信息,不容易缺失关键的文本信息,从而减少文本分类出错,提高文本分类的准确性。
43、2、本发明通过提取每个句子的字级别语义特征,经过注意力层和池化层,先后降维和升维以得到句子级语义特征,重复此操作以得到篇章级语义特征,最后通过预训练好的分类模型计算篇章文本类别的概率分布,获取最终的分类结果。在此基础上,通过句子级特征的时序融合以及注意力机制,得到更加有效的篇章级文本特征表示,进一步提高文本分类的准确性。
44、3、本发明可采用预训练模型(如albert-base)来提取语义特征,预训练模型中的参数都是从大量数据中训练来的,涵盖多个预训练任务,蕴含丰富的语义信息。因此在本发明的特征提取中,具备较好的语义特征表示初始化,加快模型的收敛速度,提升文本分类的准确性。另外,预训练模型的权重在训练过程中是冻结的,并不参与之后的微调迭代更新;该策略可以减少模型微调的参数量,加快训练速度,同时也降低了模型在部署时的显存占用,节约资源
45、4、本发明可有效提取整篇文本的语义信息。具体的,普通的深度学习文本分类方法,受限于预训练模型的输入长度限制,如最大输入长度为512,使得模型很难获取到整篇文本的语义信息,容易缺失关键的文本信息,导致文本分类出错。本发明通过预处理中的句子分割策略,预训练模型只对句子级的文本进行语义特征提取,避免了预训练模型的输入长度限制。
46、5、本发明还针对传统分类过程中读取附件会有时间的损耗,并且可能存在附件损坏,格式不兼容,乱码等等潜在的问题,采用了简化策略,对附件形式的文本信息,则只保留该附件的文件名,并不需要保留附件内容。附件本身的文件名,基本包含了所属类别的语义信息,故可以在不损害分类精度的情况下,提升整个文本分类系统的高效性和可靠性。
47、6.本发明公开的基于全局结构特征融合的篇章级文本分类系统,通过应用上述分类方法,能够产生与该方法相同的有益效果,在此不再赘述。