基于决策注意力机制的多智能体在线学习方法与流程
本发明涉及人工智能领域,更具体地说,本发明涉及基于决策注意力机制的多智能体在线学习方法。
背景技术:
1、多智能体强化学习(multi-agent reinforcement learning,marl)是强化学习的一个分支,它涉及到多个智能体在一个共享环境中进行学习和决策。在传统的强化学习中,通常只有一个智能体与环境进行交互,它能够观察环境的状态,执行动作,并从环境中获得奖励信号以指导其行为,而在多智能体强化学习中,有多个智能体共同存在于同一个环境中,并且它们相互影响彼此的决策和行为。多智能体强化学习在许多领域都有广泛的应用,如多智能体博弈、机器人协作、自动驾驶、资源分配等,通过在多智能体环境中进行训练,使智能体学会在复杂的社交互动环境中做出有效的决策。多智能体系统能够具有不同的目标,有些情况下它们需要合作以实现共同的目标,而在其他情况下它们可能是竞争对手,追求不同的奖励。在多智能体系统中,每个智能体的策略需要考虑到其他智能体的行为,这使得策略设计更为复杂。
2、知识蒸馏(knowledge distillation)是一种深度学习模型训练的技术,它旨在通过将一个复杂的模型(通常称为“教师模型”)的知识传递给一个简化的模型(通常称为“学生模型”)来实现模型压缩和推理过程,通常离线知识蒸馏的核心是训练两个模型,一个是复杂的教师模型,另一个是简化的学生模型,教师模型通常是一个在大型数据集上训练的深度神经网络,具有高准确度但计算资源密集;学生模型相对较小且简单,旨在在计算上更加高效。知识蒸馏的优点在于它能够在不牺牲性能的情况下,将复杂模型的知识转移到一个更加轻量级的模型中,从而提高了模型的推理速度和在资源受限环境下的可用性,这对于在移动设备、嵌入式系统等有限资源的环境中部署深度学习模型非常有用。相比于离线知识蒸馏,在线知识蒸馏,不需要训练好的复杂教师模型,可以直接让不同学生网络之间互相学习,同时提升不同学生网络模型的性能表现。而传统的在线知识蒸馏技术,使用相同的权重,对来自其他学生模型的知识进行加权,无法突出来自不学生模型的知识之间的差异性。因此,直接在多智能体系统中使用在线知识蒸馏无法突出不同决策之间的差异性,为了解决上述问题,现提供一种技术方案。
技术实现思路
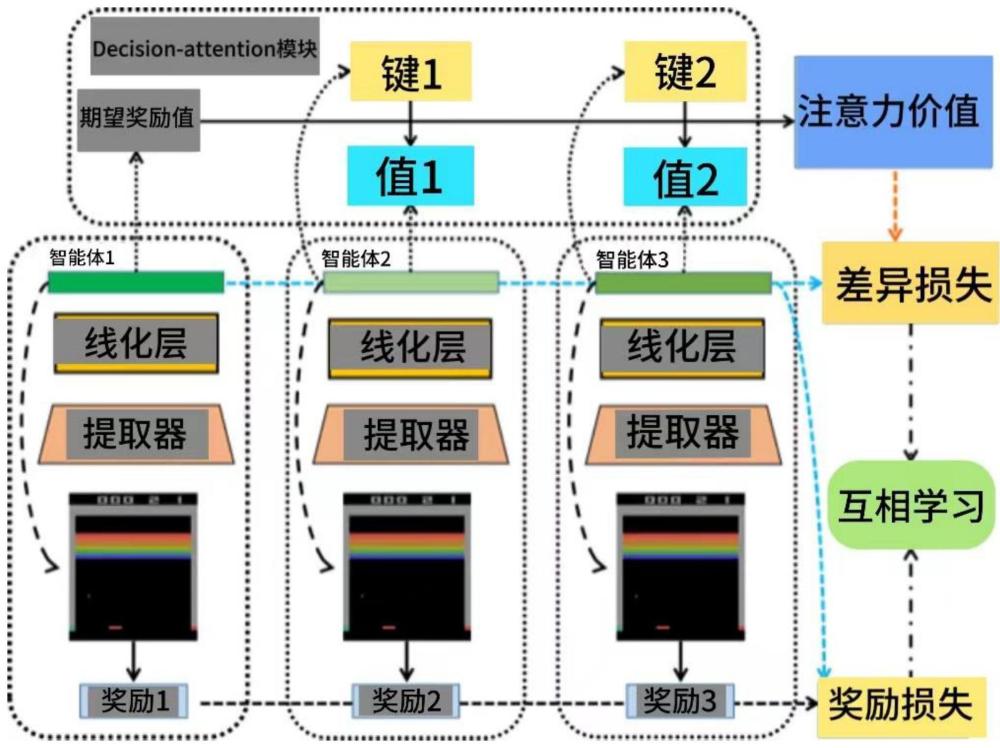
1、为了克服现有技术的上述缺陷,本发明提供基于决策注意力机制的多智能体在线学习方法,利用在线知识蒸馏设计多智能体在线学习方法框架,让多智能体之间互相学习,从而提升每个智能体的性能表现,同时引入decision-attention模块,该模块使用attention机制突出不同智能体决策之间的差异性,从而更好的混合不同智能体的决策形成监督信号,有助于提高多智能体系统的学习效率和性能表现,使其更好地适应复杂和动态的环境,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、基于决策注意力机制的多智能体在线学习方法,包括如下步骤:
4、步骤一,决策混合:将多个智能体中的每个智能体在相同的状态下产生决策,通过decision-attention模块为每个智能体的决策分配权重,并对决策进行加权处理;
5、步骤二,互学习:搭建多智能体系统在线学习框架,使用目标智能体决策权重混合剩余智能体的决策构造监督信号,并引入损失函数使多智能体进行互相学习。
6、作为本发明进一步的方案,通过decision-attention模块为每个智能体的决策分配权重,decision-attention模块通过attention机制捕捉每个智能体决策之间的差异性以及相对重要程度,decision-attention模块通过将目标智能体的期望奖励值作为查询query,剩余智能体的期望奖励值作为键key和值value,计算每个智能体决策的权重,通过decision-attention模块计算每个智能体决策权重的公式为:
7、
8、式中:w为智能体决策权重,softmax为softmax函数,qa为目标智能体的期望奖励值,为作为键key的剩余智能体的期望奖励值,为作为值value的剩余智能体的期望奖励值,dk为键key的维度,为剩余智能体。
9、作为本发明进一步的方案,目标智能体的期望奖励值通过深度强化学习网络输出获得,期望奖励值的获得步骤为:
10、步骤q1,动作选择:在每个时间步,根据目标状态使用ε-greedy策略选择动作,ε-greedy策略以ε的概率选择动作,以1-ε的概率选择当前奖励值最高的动作;
11、步骤q2,经验回放:将每个时间步的经验存储在经验回放缓冲区中,包括目标状态、动作以及奖励,经验回放缓冲区用于随机抽样以训练深度强化学习网络;
12、步骤q3,更新qa值:从经验回放缓冲区中抽样经验样本,通过最小化深度强化学习网络的损失函数更新深度强化学习网络的参数,损失函数采用均方误差损失,其目标为使深度强化学习网络的输出接近目标qa值;
13、步骤q4,qa值的计算:使用目标网络计算qa值,目标网络与深度强化学习网络结构相同,使用计算出的qa值与深度强化学习网络的预测qa值之间的损失更新深度强化学习网络的参数,直到达到停止条件。
14、作为本发明进一步的方案,使用目标网络计算qa值的具体步骤为:
15、步骤r1,使用目标网络估计下一个目标状态的最大qa值,即q(s′,a′),其s′为下一个目标状态,a′为下一个目标状态的最佳动作;
16、步骤r2,目标qa值的计算公式为:
17、qa=r+γ*q(s′,a′);
18、式中:r为目标智能体的奖励,γ为折扣因子。
19、作为本发明进一步的方案,通过decision-attention模块为每个智能体的决策分配权重,并对决策进行加权处理,对决策进行加权处理的公式为:
20、
21、式中:为对决策进行加权后的输出,为时间步i的智能体决策权重,为时间步i的深度强化学习网络输出,t为时间步个数。
22、作为本发明进一步的方案,步骤二互学习,搭建多智能体系统在线学习框架,使用目标智能体决策权重混合剩余智能体的决策构造监督信号,并引入损失函数使多智能体进行互相学习,以比较智能体决策之间的差异,智能体决策之间的差异通过kl散度进行计算,使用kl散度计算智能体决策之间的差异的公式为:
23、
24、式中:lkl为kl散度损失,p为动作数量,为使用decision-attention模块得到的加权输出在时间步tea下,动作a在状态s下的概率,oi,p(a|s)为深度强化学习网络在时间步i下,动作a在状态s下的概率。
25、本发明基于决策注意力机制的多智能体在线学习方法的技术效果和优点:
26、1、本发明通过在线知识蒸馏设计多智能体在线学习方法框架,让多智能体之间互相学习,从而提升每个智能体的性能表现,同时引入decision-attention模块,该模块使用attention机制突出不同智能体决策之间的差异性,从而更好的混合不同智能体的决策形成监督信号;
27、2、本发明通过让智能体与环境不断交互来获取尽可能多的奖励值,多智能体系统学习的目标是通过让每个智能体互相学习,交互不同智能体学到的知识,以达到每个智能体在不同任务上都能获得尽可能多奖励值的目标,有助于消除决策中的不必要的冲突,并提高合作性能。
- 还没有人留言评论。精彩留言会获得点赞!