人工智能芯片的加速单元调度方法及系统与流程
本发明涉及边缘计算,具体地说是人工智能芯片的加速单元调度方法及系统。
背景技术:
1、作为目前人工智能中深度学习算法的代表之一,卷积神经网络在很多研究领域取得了巨大的成功,例如语音识别、图像识别、图像分割和自然语音处理等。
2、在边缘计算领域,由于卷积神经网络模型尺寸和相应的计算复杂度太大,很难直接移植到边缘端的嵌入式芯片中进行实时推理计算。近些年来针对于边缘端的深度学习需求,一般的技术解决方案是微控制器与ai加速单元相结合的方式,但是目前的多数方案普遍将ai加速单元设计为一个黑盒,加速单元从微控制器的获得输入数据,经过加速单元处理后,返回处理结果给微控制器,中间的执行过程无法监控。并且采用一组状态寄存器来标识ai加速单元当前的状态,微控制器在程序执行期间,必须时刻监测该状态寄存器的状态,来判断ai加速单元是否已经完成了推理任务并处于空闲状态,以此来判断是否将下一组数据传输给ai加速单元进行处理,造成了微控制器的轮训空转,极大地浪费微控制器资源。
3、如何提高微控制器对ai加速单元的调度效率、减少微控制器空转带来的资源浪费,是需要解决的技术问题。
技术实现思路
1、本发明的技术任务是针对以上不足,提供人工智能芯片的加速单元调度方法及系统,来解决如何提高微控制器对ai加速单元的调度效率、减少微控制器空转带来的资源浪费的技术问题。
2、第一方面,本发明一种人工智能芯片的加速单元调度方法,对于ai加速单元,每个算子执行完毕后能够通过中断实时向微处理器返回处理结果,所述方法包括如下步骤:
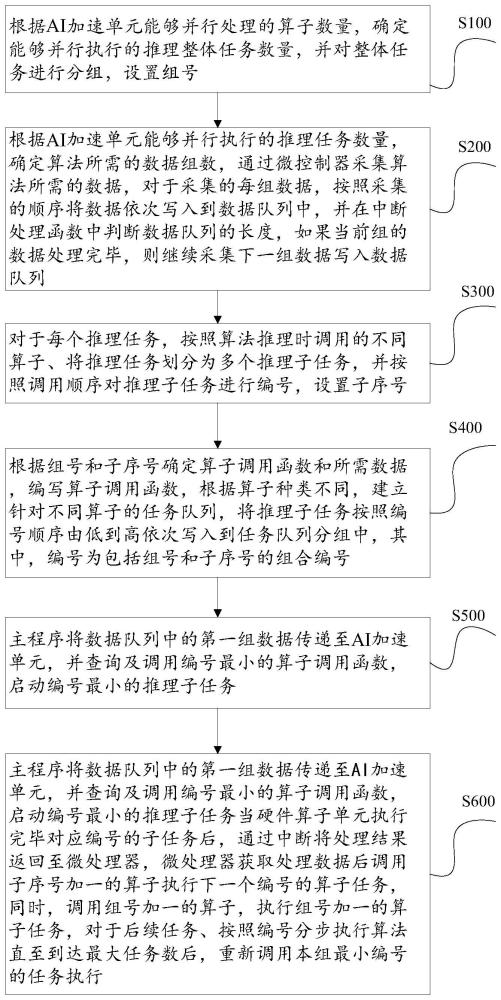
3、s100、根据ai加速单元能够并行处理的算子数量,确定能够并行执行的推理整体任务数量,并对整体任务进行分组,设置组号;
4、s200、根据ai加速单元能够并行执行的推理任务数量,确定算法所需的数据组数,通过微控制器采集算法所需的数据,对于采集的每组数据,按照采集的顺序将数据依次写入到数据队列中,并在中断处理函数中判断数据队列的长度,如果当前组的数据处理完毕,则继续采集下一组数据写入数据队列;
5、s300、对于每个推理任务,按照算法推理时调用的不同算子、将推理任务划分为多个推理子任务,并按照调用顺序对推理子任务进行编号,设置子序号;
6、s400、根据组号和子序号确定算子调用函数和所需数据,编写算子调用函数,根据算子种类不同,建立针对不同算子的任务队列,将推理子任务按照编号顺序由低到高依次写入到任务队列分组中,其中,编号为包括组号和子序号的组合编号;
7、s500、主程序将数据队列中的第一组数据传递至ai加速单元,并查询及调用编号最小的算子调用函数,启动编号最小的推理子任务;
8、s600、当硬件算子单元执行完毕对应编号的子任务后,通过中断将处理结果返回至微处理器,微处理器获取处理数据后调用子序号加一的算子执行下一个编号的算子任务,同时,调用组号加一的算子,执行组号加一的算子任务,对于后续任务、按照编号分步执行算法推理,直至到达最大任务数后,重新调用本组最小编号的任务执行。
9、作为优选,对于ai加速单元,按照ai加速单元能够处理的算子功能不同,将ai加速单元划分为多个处理模块,并将每个处理模块按照中断控制器的接口规范设计一组接口,接口通过ai加速单元的通用控制器与微控制器的中断控制器相连接。
10、作为优选,将子任务按照编号顺序由低到高依次写入到任务队列分组中时,将对应的函数指针放入任务队列中。
11、作为优选,步骤s600中,后续任务由中断处理函数通过查询遍历队列的形式,按照编号分步执行算法推理。
12、第二方面,本发明一种人工智能芯片的加速单元调度系统,对于ai加速单元,每个算子执行完毕后能够通过中断实时向微处理器返回处理结果,所述系统用于执行如第一方面任一项所述的一种人工智能芯片的加速单元调度方法,包括:
13、任务分组模块,所述任务分组模块用于执行如下:根据ai加速单元能够并行处理的算子数量,确定能够并行执行的推理整体任务数量,并对整体任务进行分组,设置组号;
14、数据采集模块,所述数据采集模块用于执行如下:根据ai加速单元能够并行执行的推理任务数量,确定算法所需的数据组数,通过微控制器采集算法所需的数据,对于采集的每组数据,按照采集的顺序将数据依次写入到数据队列中,并在中断处理函数中判断数据队列的长度,如果当前组的数据处理完毕,则继续采集下一组数据写入数据队列;
15、任务细分模块,所述任务细分模块用于执行如下:对于每个推理任务,按照算法推理时调用的不同算子、将推理任务划分为多个推理子任务,并按照调用顺序对推理子任务进行编号,设置子序号;
16、任务队列构建模块,所述任务队列构建模块用于执行如下:根据组号和子序号确定算子调用函数和所需数据,编写算子调用函数,根据算子种类不同,建立针对不同算子的任务队列,将推理子任务按照编号顺序由低到高依次写入到任务队列分组中,其中,编号为包括组号和子序号的组合编号;
17、任务执行模块,所述任务执行模块调用主程序,用于执行如下:
18、主程序将数据队列中的第一组数据传递至ai加速单元,并查询及调用编号最小的算子调用函数,启动编号最小的推理子任务;
19、当硬件算子单元执行完毕对应编号的子任务后,通过中断将处理结果返回至微处理器,微处理器获取处理数据后调用子序号加一的算子执行下一个编号的算子任务,同时,调用组号加一的算子,执行组号加一的算子任务,对于后续任务、按照编号分步执行算法推理,直至到达最大任务数后,重新调用本组最小编号的任务执行。
20、作为优选,所述系统还包括硬件处理模块,所述硬件处理模块用于执行如下:对于ai加速单元,按照ai加速单元能够处理的算子功能不同,将ai加速单元划分为多个处理模块,并将每个处理模块按照中断控制器的接口规范设计一组接口,接口通过ai加速单元的通用控制器与微控制器的中断控制器相连接。
21、作为优选,将子任务按照编号顺序由低到高依次写入到任务队列分组中时,所述任务队列构建模块用于将对应的函数指针放入任务队列中。
22、作为优选,对于所述任务执行模块,执行如下:后续任务由中断处理函数通过查询遍历队列的形式,按照编号分步执行算法推理。
23、本发明的人工智能芯片的加速单元调度方法及系统具有以下优点:
24、1、能够做到流水式执行算子,提高了加速单元的各算子处理单元的并行性;
25、2、硬件方面,将ai加速单元按照处理的算子功能不同,划分为多个处理模块,并将每个模块按照中断控制器的接口规范设计一组接口,通过ai加速单元的通用控制器与微控制器的中断控制器相连接。以保证每个算子执行完毕后能够通过中断实时向微处理返回处理结果,以此来监控整个算法推理的过程进度。对每个算子的状态进行了独立监控,并且此过程完全由硬件中断触发,并无需cpu执行轮训检测函数,判断ai加速单元的状态。cpu可以执行同时其他处理任务,提高了cpu的处理效率,并降低了cpu的功耗。
- 还没有人留言评论。精彩留言会获得点赞!