LAMOST文献天体标识信息提取方法、装置、设备及介质
本公开涉及数据处理,尤其涉及一种基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质。
背景技术:
1、lamost(large sky area multi-object fiber spectroscopic telescope)是一座位于中国的大型多目标纤维光谱望远镜,以其大规模光谱观测和高效的目标选择系统而闻名,为天文学研究提供了宝贵的观测数据。lamost的巡天能力和科学贡献使其成为国际天文学领域的一项重要设施,这也吸引了众多学者加入到其数据的研究当中,从而促进了其论文数量的大幅增长。天体物理数据系统(ads)和arxiv等平台收录了其丰富的文献资源,这些文献包含了宝贵的已被研究的数据,包括天体标识符、坐标信息、质量、大小、亮度等。全面了解某些数据的研究基础,并在这些研究基础上进行深入推演,是获得重大突破的关键之一。因此,帮助研究人员高效地完成lamost文献与观测数据的关联和互检索是一项必要的工作。实现这一目标,最重要的任务就是从大量文献中提取lamost天体标识符、赤经(ra)和赤纬(dec)和obsid(三者能标定唯一天体,虽然obsid是天体光谱的唯一编号,但是研究人员常用其代表对应天体)三种实体信息。
2、从文本中提取实体信息的任务叫做命名实体识别(named entity recognition,ner),很多工作者在天文领域也针对ner进行了研究与应用。
3、早期的ner方法主要基于规则和字典的方法,通过人工定义的规则来识别命名实体。lesteven等人开发出了djin系统,系统利用天体命名词典等资源来匹配文献中的天体名称和标识符,并且可以跟踪每个天体名称在文献中的出现位置、频率等,从而评估文献与特定天体的相关程度。基于这套系统,最成功的应用是cds将其与文献检索服务和星表检索服务相结合,让读者通过天体标识符即可获取该天体相关文献,相反读者在浏览文献时也可以直接获取该文献所包含的所有天体标识符,点击天体标识符即可链接到simbad中获取该天体的相关信息。这种文献与观测数据的关联和互检索服务极大地方便了天文学家的文献阅读和科研工作,也展示了实体信息提取在连接异构天文学信息资源方面的重要作用。
4、随着机器学习的兴起,基于统计模型的ner方法逐渐流行起来,如最大熵模型、隐马尔可夫模型等。murphy等人利用最大熵模型训练了一个专门针对天文学文献的ner系统,旨在识别文献中具有重要的科研价值的命名实体,如源类型、源名称、设备名称等。基于这些方法能够从大规模语料库中学习实体的上下文信息和分布特点,实现更准确的实体识别,但是过于依赖人工参与,泛化能力和迁移性较差,无法适应天文学领域越来越多样化的ner需求,并且也很难及时高效地完成大规模ner任务。
5、为了进一步解决大量天文文献中命名实体数据难以被及时有效地提取和利用的问题,grezes等人尝试引入大规模的预训练语言模型。他们通过在395499篇天文文献上预训练bert语言模型,获得了一个性能更优的天文领域语言模型astrobert。利用astrobert,他们尝试从文献中提取机构名称等信息。在2022年第一次科学出版物信息提取研讨会上,detecting entities in the astrophysics literature(deal)被提出。deal是一个共享任务,期望参与者构建能够自动提取天文命名实体的系统。其中mt5、bert等大规模预训练语言模型被参与者们认为是有效的工具。但是,这些模型需要大量训练数据,容易过拟合,并且它们的解释性和健壮性较差。
技术实现思路
1、(一)要解决的技术问题
2、针对目前存在的技术问题,本公开提出一种基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,以实现在海量天文文献中自动化批量提取lamost三种天体标识信息。
3、(二)技术方案
4、本公开提供了一种基于大语言模型claude2的lamost文献天体标识信息提取方法,包括:
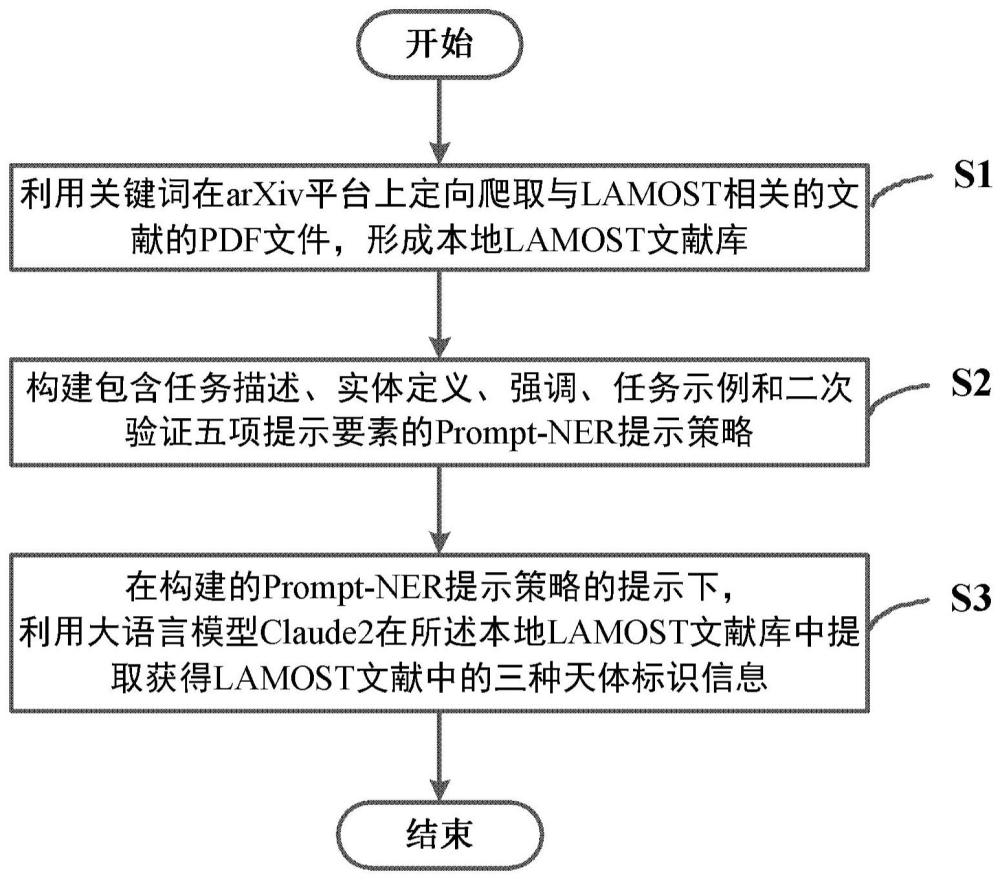
5、利用关键词在arxiv平台上定向爬取与lamost相关文献的pdf文件,形成本地lamost文献库;
6、构建包含任务描述(task descriptions)、实体定义(entity definitions)、强调(emphases)、任务示例(task examples)和二次验证(second conversation)五项提示要素的prompt-ner提示策略;
7、在构建的prompt-ner提示策略的提示下,利用大语言模型claude2在所述本地lamost文献库中提取获得lamost文献中的三种天体标识信息。
8、上述方案中,所述利用关键词在arxiv平台上定向爬取与lamost相关文献的pdf文件,形成本地lamost文献库,包括:以“large sky area multi-object fiberspectroscopic telescope”或“lamost”作为关键词,利用文献爬取工具在arxiv平台上检索全文范围内包含“large sky area multi-object fiber spectroscopic telescope”或“lamost”字符串的文献;如果能够检索到,则下载这些文献的pdf文件,形成本地lamost文献库。
9、上述方案中,所述利用关键词在arxiv平台上定向爬取与lamost相关文献的pdf文件,形成本地lamost文献库,还包括:定期执行爬取操作,获取最新的与lamost相关的文献,确保数据持续更新。
10、上述方案中,所述构建包含任务描述(task descriptions)、实体定义(entitydefinitions)、强调(emphases)、任务示例(task examples)和二次验证(secondconversation)五项提示要素的prompt-ner提示策略的步骤中,所述任务描述(taskdescriptions)包括角色、任务和基本要求,针对任务描述(task descriptions)这一提示要素构建prompt-ner提示策略具体包括:
11、为了充分唤起大语言模型claude2天文学的知识,赋予大语言模型claude2扮演资深天文学家的角色,并告知大语言模型claude2需要掌握的技能;
12、明确大语言模型claude2需要完成天文ner任务;
13、输出结果被要求以json格式输出,并且给出了json示例,以方便后续处理;
14、文献中的三种天体标识信息既会在非结构化的文本中出现,也会在结构化的表格中出现,为了保证大语言模型claude2的注意力集中,两种任务被要求独立执行。
15、上述方案中,所述构建包含任务描述(task descriptions)、实体定义(entitydefinitions)、强调(emphases)、任务示例(task examples)和二次验证(secondconversation)五项提示要素的prompt-ner提示策略的步骤中,针对实体定义(entitydefinitions)这一提示要素构建prompt-ner提示策略具体包括:实体定义(entitydefinitions)这一部分对需要提取的三种天体标识实体进行定义,包括天体标识符、赤经(ra)和赤纬(dec)及obsid。
16、上述方案中,所述构建包含任务描述(task descriptions)、实体定义(entitydefinitions)、强调(emphases)、任务示例(task examples)和二次验证(secondconversation)五项提示要素的prompt-ner提示策略的步骤中,为了使大语言模型claude2输出的结果更符合要求,在所述强调(emphases)这一提示要素中对任务细节进行强调,针对所述强调(emphases)这一提示要素构建prompt-ner提示策略具体包括:
17、介绍多种大概率出现的形式以帮助大语言模型claude2识别和提取,大语言模型claude2是通过语义推理来识别这些命名实体;
18、要求大语言模型claude2对识别结果进行自检,能够在一定程度上提升识别的效果;
19、要求大语言模型claude2解释提取天体信息实体的原因,这种自我引导策略也能提高准确率。
20、上述方案中,所述构建包含任务描述(task descriptions)、实体定义(entitydefinitions)、强调(emphases)、任务示例(task examples)和二次验证(secondconversation)五项提示要素的prompt-ner提示策略的步骤中,针对所述任务示例(taskexamples)这一提示要素构建prompt-ner提示策略具体包括:依靠专业知识构建出3个高质量的输入和输出示例对,以帮助大语言模型claude2学习输入和输出之间的模式,从而更好地理解任务,并努力生成与示例输出相似的响应。
21、上述方案中,所述构建包含任务描述(task descriptions)、实体定义(entitydefinitions)、强调(emphases)、任务示例(task examples)和二次验证(secondconversation)五项提示要素的prompt-ner提示策略的步骤中,所述二次验证(secondconversation)是采用二次对话作为自我验证策略,针对二次验证(second conversation)这一提示要素构建prompt-ner提示策略具体包括:
22、假设第一次对话提取的命名实体不够齐全和准确;
23、再次给出重要的提示;
24、要求大语言模型claude2自我验证第一次对话的提取结果并重新提取一次。
25、上述方案中,所述在构建的prompt-ner提示策略的提示下,利用大语言模型claude2在所述本地lamost文献库中提取获得lamost文献中的三种天体标识信息,包括:
26、假设第一次对话提取的命名实体不够齐全和准确;
27、先输入prompt-ner提示策略中任务描述(task descriptions)、实体定义(entitydefinitions)、强调(emphases)和任务示例(task examples)这四项提示元素;
28、加载需要提取信息的文献pdf文件;
29、大语言模型claude2执行提取三种天体标识信息任务;
30、通过正则方法在返回结果中匹配json格式信息;
31、获得第一次返回的非结构化文本和结构化表格中的三种天体标识信息;
32、再输入prompt-ner提示策略的二次验证(second conversation)提示元素。
33、通过正则方法在返回结果中匹配json格式信息;
34、获得第二次返回的非结构化文本和结构化表格中的三种天体标识信息。
35、上述方案中,所述利用大语言模型claude2在所述本地lamost文献库中提取获得lamost文献中的三种天体标识信息之后,还包括:在lamost观测星表中对获得的lamost文献中的三种天体标识信息进行验证,判断获得的lamost文献中的三种天体标识信息是否有效,过滤出无效或错误数据,确保后续使用准确可靠信息。
36、本公开另一方面提供了一种基于大语言模型claude2的lamost文献天体标识信息提取装置,包括:
37、lamost文献爬取模块,用于利用关键词在arxiv平台上定向爬取与lamost相关文献的pdf文件,形成本地lamost文献库;
38、prompt-ner提示策略构建模块,用于构建包含任务描述(task descriptions)、实体定义(entity definitions)、强调(emphases)、任务示例(task examples)和二次验证(second conversation)五项提示要素的prompt-ner提示策略;
39、天体标识信息提取模块,用于在构建的prompt-ner提示策略的提示下,利用大语言模型claude2在所述本地lamost文献库中提取获得lamost文献中的三种天体标识信息。
40、上述方案中,该装置还包括:天体标识信息验证模块,用于在lamost观测星表中对获得的lamost文献中的三种天体标识信息进行验证,判断获得的lamost文献中的三种天体标识信息是否有效,过滤出无效或错误数据,确保后续使用准确可靠信息。
41、本公开另一方面还提供了一种电子设备,包括:处理器;存储器,其存储有计算机可执行程序,该程序在被所述处理器执行时,使得所述处理器执行所述的基于大语言模型claude2的lamost文献天体标识信息提取方法。
42、本公开另一方面还提供了一种包含计算机可执行指令的计算机可读介质,所述计算机可执行指令被执行时实现所述的基于大语言模型claude2的lamost文献天体标识信息提取方法。
43、本公开另一方面还提供了一种计算机程序产品,其特征在于,包括:计算机可执行指令,所述指令被执行时用于实现所述的基于大语言模型claude2的lamost文献天体标识信息提取方法。
44、(三)有益效果
45、从上述技术方案可以看出,本公开提供的基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,具有以下有益效果:
46、1、本公开提供的基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,通过设计prompt-ner策略进行提示工程,借助文本爬取工具,并利用大语言模型零样本学习的能力,实现了实现在海量天文文献中自动化批量提取lamost三种天体标识信息,极大地减轻了人工标注的工作量,并能够持续地从新增文献中获取信息。
47、2、本公开提供的基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,通过设计prompt-ner策略进行提示工程,能够有效地引导模型识别并提取目标信息,无需额外训练,同时这展示了提示工程在提高模型精确度和可控性方面的重要作用。
48、3、本公开提供的基于大语言模型c1aude2的lamost文献天体标识信息提取方法、装置、设备及介质,借助文本爬取工具和天体信息验证工具,实现了从海量文献中筛选出目标文献、批量提取信息、并自动验证信息的完整流程,这为相关文献与数据的深度关联提供了支持。
49、4、本公开提供的基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,能够持续应用于新出现的文献,并可迁移到其他类似信息提取任务,具有很强的可扩展性。
50、5、本公开提供的基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,提高了文献内容的数据信息可挖掘程度,有助于文献内容的管理、搜索和知识发现。
51、6、本公开提供的基于大语言模型claude2的lamost文献天体标识信息提取方法、装置、设备及介质,为天文数据科学提供了信息支撑,促进多源异构天文数据的关联与应用。
- 还没有人留言评论。精彩留言会获得点赞!