一种基于对比学习和方面增强的多模态情感分类方法
本发明提供一种基于对比学习和方面增强的多模态情感分类方法,通过捕捉方面增强的多模态信息来促进面向方面的多模态情感分类性能,属于自然语言处理。
背景技术:
1、基于多模态方面的情感分析(mabsa)的目标是整合文本和图像信息,以准确识别句子中特定方面的情感极性。这项技术在社交媒体、医疗保健和教育等各个领域都有巨大的应用潜力。这项任务的关键挑战之一是有效地融合两种截然不同的模式——文本和图像——来分析各方面的情绪。在mabsa的许多下游应用中,精确匹配的图像-文本数据对通常很少。这是由于图像文本数据的互补性,这在两种模式之间存在显著的语义差距。因此,准确对齐文本和图像可能具有挑战性方面是缩小多模态语义差距、提高多模态表示能力的重要支点之一。基于方面的多模态融合旨在通过将方面表示作为跨模态语义支点来促进文本和图像之间的整体语义融合。如何促进网络学习更好的面向方面的多模态表示是mabsa最关键的问题之一。
2、最近的许多研究都试图通过采用几种面向方面的多模态融合策略来应对mabsa中视觉文本对齐的挑战,然而,这些工作大多倾向于通过直接将视觉、文本和方面表示作为输入来集中于面向方面的特征级融合,通常忽略不同模态之间的表示差距。在不同是多模态特征空间中两种模态之间存在显著的表示差距。因此,直接融合两种不同类型的非对齐模态表示必然会出现模态表示偏误问题。
3、模态对齐和特征级融合是多模态融合过程中必须考虑的两个耦合问题。通过在模态空间中适当地对齐图像和文本的表示,可以更容易地在多模态特征空间中融合它们的表示。对齐和融合是两个相互依存的子任务,对成功的多模态融合都至关重要。此外,方面表示通常是图像和文本的重叠语义信息,是改进跨模态对齐和特征融合的合适支点。为了解决mabsa中出现的面向方面的跨模态融合问题,本发明提出了一种基于对比学习和方面增强多模态情感分类方法,以促进多模态融合,这可以显著提高面向方面情感极性识别的准确性。
技术实现思路
1、本发明提出了一种基于对比学习和方面增强的多模态情感分类方法来解决上述技术中的技术问题,通过弥补模态鸿沟,改进跨模态对齐和特征融合,获取方面增强的多模态表示来提高多模态情感分类的性能。本发明提出的方法在多模态方面级情感分析、模态对齐和特征融合等应用提供了有力支撑。
2、本发明的技术方案是:一种基于对比学习和方面增强的多模态情感分类方法,所述基于对比学习和方面增强的多模态情感分类方法的具体步骤如下:
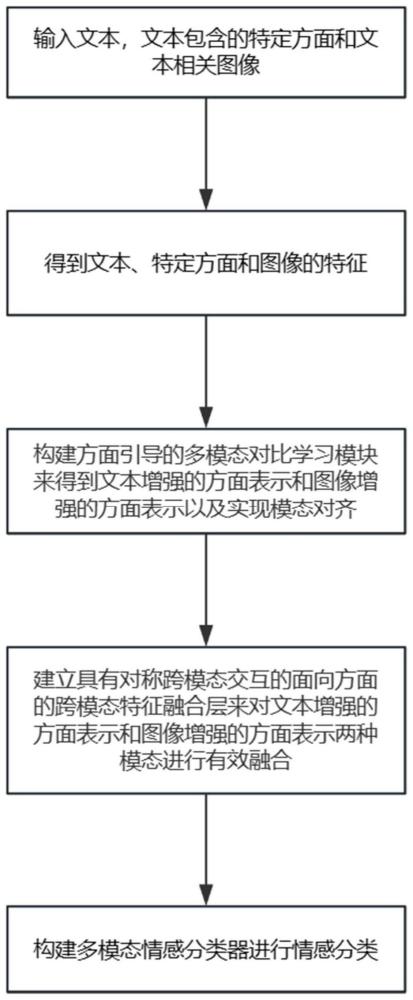
3、step1、输入文本,文本包含特定方面和文本相关图像;
4、step2、得到文本、特定方面和图像的特征;
5、step3、构建方面引导的多模态对比学习模块来得到文本增强的方面表示和图像增强的方面表示以及实现模态对齐;
6、step4、建立具有对称跨模态交互的面向方面的跨模态特征融合层来对文本增强的方面表示和图像增强的方面表示两种模态进行有效融合;
7、step5、构建多模态情感分类器进行情感分类。
8、进一步地,所述step2的具体步骤如下:
9、step2.1、使用vit-base-patch16-2预训练模型对图像进行编码得到对应的图像特征;
10、step2.2、使用bert-base-uncased预训练模型来对文本和特定方面进行编码得到文本表征,文本表征中包括文本特征、方面特征。
11、进一步地,所述step3的具体步骤如下:
12、step3.1、将文本特征、方面特征和图像特征送入到多模态对比学习模块中,通过以方面为枢轴的方面-文本的交互和方面-图像的交互得到文本增强的方面表示和图像增强的方面表示;
13、step3.2、采用方面指导的三重对比学习来实现模态对齐。
14、进一步地,所述step4的具体步骤如下:
15、step4.1、将step3.1得到的文本增强的方面表示和图像增强的方面表示进行跨模态的特征融合;
16、step4.2、将融合后的图文多模态特征进行多模态对比学习促进特征融合。
17、进一步地,所述step5的具体步骤如下:
18、step5.1、将step4.2进行多模态对比学习后得到的多模态表征输入给一个传统transformer encoder模块;
19、step5.2、利用softmax层进行最终情感分类。
20、进一步地,所述step3.1的具体步骤如下:
21、step3.1.1、使用两个堆叠的传统交叉注意力模块,通过分别将方面和文本表示et、es作为query和key/valua来捕捉方面-文本的交互:
22、hts=ln(et+crossatt(et,es,es))
23、其中,是文本增强的方面表示,crossatt和ln表示交叉注意力模块和层的归一化操作;n和d表示文本增强的方面表示矩阵的维度;
24、step3.1.2、使用两个堆叠的传统交叉注意力模块,通过分别将方面和图像表示作为query和key/valua来捕捉方面-图像的交互:
25、htv=ln(et+crossatt(et,ev,ev))
26、其中,是图像增强的方面表示,crossatt和ln表示交叉注意力模块和层的归一化操作。
27、进一步地,所述step3.2的具体步骤如下:
28、step3.2.1、对文本增强的方面表示hts和图像增强的方面表示htv进行平均来获得中间表示:
29、
30、其中表示平均的方面表示;
31、step3.2.2、将文本增强的方面表示、图像增强的方面表示和平均的方面表示进行模态对齐的三重对比学习操作:
32、
33、其中表示三重对比损失,表示α和β之间的对比损失,并且α,β∈{hta,htv,hts},代表如下操作:
34、
35、其中和代表如下操作:
36、
37、
38、其中,αi和βj分别是α中第i个特征和β中第j个特征的归一化表示,n是批量大小,τ是温度参数。
39、进一步地,所述step4.1的具体步骤如下:
40、step4.1.1:将得到文本增强的方面表示hts和图像增强的方面表示htv表示进行mixup操作:
41、hs2v=w1hts+(1-w1)htv
42、hv2s=w2htv+(1-w2)hts
43、其中,表示浅层的方面表示,w1和w2是混合超参数;
44、step4.1.2接着,将浅层的方面表示hs2v,hv2s馈送具有多头自注意机制和交叉注意层的双层注意模块当中,进行如下操作:
45、
46、
47、其中selfatt(·)和crossatt(·)表示多头自注意机制和交叉注意机制;表示视觉-文本的增强方面表示和文本-视觉的增强方面表示,ln表示层的归一化操作。
48、进一步地,所述step4.2的具体步骤如下:
49、step4.2.1、将视觉-文本的增强方面表示和文本到视觉的增强方面表示进行多模态对比学习操作:
50、
51、其中表示多模态对比损失,表示和之间的对比损失,其和代表如下操作:
52、
53、
54、其中α表示β表示αi和βj分别是α中第i个特征和β中第j个特征的归一化表示,n是批量大小,τ是温度参数。
55、进一步地,所述step5.1的具体步骤如下:
56、step5.1.1、将视觉-文本的增强方面表示和文本到视觉的增强方面表示在最后一个维度拼接起来并送到一个单层transformer编码器中,操作表示如下:
57、
58、其中transencc表示一层transformer编码器层,concat表示最后一个维度中的拼接操作;表示视觉和文本增强的方面表示;
59、所述step5.2的具体步骤如下:
60、step5.2.1然后,使用池化后的方面表示送入softmax层进行情感分类:
61、p(y|h)=softmax(pooling(ha)w′)
62、其中softmax表示在最后维度中的softmax操作;pooling表示长度维度中的平均池化操作;是可训练参数;将分类损失函数定义为:
63、
64、其中n代表批量大小;
65、最后,通过整合分类损失三重对比损失和多模态对比损失三种类型的损失来获得总损失函数,作为分类的差异度量,总损失表示为:
66、
67、其中超参数λ1和λ2用于平衡不同的训练损失。
68、本发明的有益效果及优点是:
69、1、本发明提出了一种基于对比学习和方面增强的多模态情感分类方法来解决多模态方面级情感分析中存在的模态对齐和特征融合的问题,本发明可以获取方面增强的多模态表示进而来提高多模态情感分类的性能;
70、2、本发明构建了具有三重对比学习的面向方面的模态对齐策略,有效的弥合图像和文本之间的语义差距;
71、3、本发明提出了具有对称跨模态交互的面向方面的跨模态特征融合层,通过利用对称双层跨模态交互和方面增强的多模态对比学习获取多模态方面表示,增强了多模态融合的能力;
72、4、本发明提出的方法在mabsa任务的两个基准数据集上均达到了sota的效果,可视化实验及案例分析均证明了本发明方法的有效性和优越性。
- 还没有人留言评论。精彩留言会获得点赞!