一种基于Mosaic融合的长尾学习数据增强方法
本发明涉及长尾数据识别的,尤其是指一种基于mosaic融合的长尾学习数据增强方法。
背景技术:
1、机器学习是一门研究利用计算机通过数据和算法进行学习并自动提高性能的学科。近年来随着信息技术的高速发展,互联网、工业等领域产生并存储了大量数据,机器学习技术也得以广泛的发展并应用于各个领域。然而在机器学习的实际应用中,我们通常会面临数据集中的长尾现象,即数据集中某些类别的样本数量较少,而其它类别的样本数量较多。这种不平衡的数据分布可能导致训练的深度神经网络模型对于少数类别的样本分类效果较差,影响了模型的性能。长尾数据问题广泛出现在各个不同的领域,例如图像识别、自然语言处理、医学诊断和网络安全等领域。因此,针对长尾数据问题的研究已经成为了机器学习领域中的热门研究方向。
2、传统的机器学习方法在训练长尾图片数据集时很容易出现性能下降的问题。对于少数类别的样本,由于数量较少,分类器无法充分地学习到这些类别的特征和规律,从而导致分类器对这些类别的判别能力较差,同时多数类的样本拥有大量数据,在训练分类器被赋予了更高的权重,而少数类别的数据则被赋予更低的权重,如果分类器没有考虑到少数类别数据的重要性,那么就会导致分类器的性能下降。这种不平衡的分布最终导致在分类时,分类器会更倾向于将样本归类为出现频率更高的类别,而忽略少数类别。这样的结果往往是对少数类别的分类效果较差,使得分类器的准确率和泛化能力受到限制。
3、为了解决长尾问题,在过去的几十年中,如过采样、欠采样和代价敏感等方法被陆续用于长尾数据集。欠采样方法通过减少高频次出现的类别样本数量从而平衡数据集,但这种方法可能会导致数据信息的损失和过拟合问题。过采样方法则通过增加低频次出现的类别样本数量,但这种方法可能会导致数据重复和过拟合问题。另一些学者提出了一些基于加权的方法,其中最常见的加权方法是通过样本数量进行加权,但是类别加权方法需要手动设置权重,不够灵活,也无法解决少数类特征仍然不够丰富的问题。而数据增强通过增加少数类别样本的数量和多样性,可以帮助模型更好地学习到少数类别的特征,从而改善分类性能。在目前的数据增强方法中,其中两种常用的方法mixup和cutmix虽然对少数类数据不足问题有一定效果但并没有针对长尾数据的特征进行改进,remix方法对mixup方法进行了改进,在混合两个样本时分配的标签会倾向于两个样本中数量较少的类别,但容易生成噪声并且对少数类样本的扩充效果仍然不足。
技术实现思路
1、本发明的目的在于改善传统方法中少数类样本多样性不足的问题以及长尾数据集中因为样本数量不均衡导致的模型训练不充分的问题,提出了一种基于mosaic融合的长尾学习数据增强方法,该方法利用多数类别样本的信息,提高模型在少数类别样本上的分类能力,从而提升深度神经网络模型在长尾数据集上的性能。
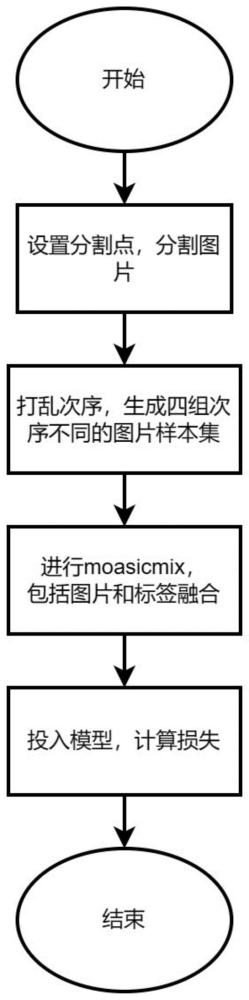
2、为实现上述目的,本发明所提供的技术方案为:一种基于mosaic融合的长尾学习数据增强方法,包括以下步骤:
3、步骤1:获取长尾数据图片,设定图片中心分割点的范围,按照分割点的水平竖直方向将每张图片分割为四块区域;打乱训练批次内图片样本的标号顺序,获得四组不同顺序的图片样本集用于后续的mosaic融合;
4、步骤2:根据不同类别的图片样本数量将图片样本类别分为多数类和少数类,对批次内的每个样本进行数据增强,如果样本属于多数类样本,将该样本与步骤1中获得的其它图片样本集的样本进行mosaic融合,填充在图片的分割区域中,如果样本属于少数类样本,则保持原图不变不进行融合;
5、步骤3:为了反映融合过程中每张图片的贡献,根据每张图片进行mosaic融合的情况,调整图片的标签信息,通过利用多数类样本丰富的信息提升少数类样本的识别效果的方式进行数据增强,最后,将图片和标签投入深度神经网络模型中计算损失函数,即可完成长尾学习数据增强。
6、进一步,在步骤1,首先设置一个图片中心分割点范围,沿中心分割点的水平竖直方向将每张图片分为a,b,c,d四个部分,图片的中心分割点在设定范围内随机选取;然后获取一个训练批次内的图片样本集x1,随机打乱该批次内图片样本顺序三次,获得三组不同顺序的图片样本集x2,x3,x4用于后续的mosaic融合。
7、进一步,在步骤2,选择一个判断图片样本类别数量多少的超参数,根据图片样本类别所包含的样本数量将图片样本类别分为多数类和少数类,样本类别数量大于超参数的类为多数类,小于超参数的类为少数类;对于批次内的图片样本进行循环遍历,多数类样本和少数类样本分别使用不同的策略,如果图片样本属于多数类样本,样本将会有p的概率与步骤1中获得的三组图片样本集中的随机图片样本进行mosaic融合,另外以1-p的概率与其中一组图片样本集中的随机图片样本进行mosaic融合;mosaic融合用于利用多数类丰富的样本信息提升少数类样本的识别效果,同时为模型添加正则化;如果是少数类,则保持少数类的样本信息完整不变;其中,图片融合公式如下:
8、
9、式中,ma,mb,mc,md分别表示在步骤1中划分的a,b,c,d四块区域的相应位置的图片掩码;mrand表示在a,b,c,d四块区域中随机选择的一块区域的相应位置的图片掩码;表示合成的图片样本;x1,x2,x3,x4分别表示在步骤1中获取的图片样本集x1,x2,x3,x4中的随机图片样本;⊙代表逐个元素乘法;n代表图片样本x1的类别数量,τ代表判断类别种类多少的超参数,r为(0,1)范围内的随机数,p为(0,1)范围内的超参数。
10、进一步,在步骤3,在完成图片样本的mosaic融合后,调整图片样本的标签值,根据每张图片的融合情况,调整图片的标签信息,计算损失函数;其中,标签融合公式如下:
11、
12、式中,sa,sb,sc,sd分别表示在步骤1中图片划分的a,b,c,d区域的面积在整张图片中的面积占比,srand表示在a,b,c,d四块区域中随机选择的一块区域的面积在整张图片中的面积占比,表示合成的图片样本的标签信息,y1,y2,y3,y4分别表示图片样本x1,x2,x3,x4的标签信息。
13、本发明与现有技术相比,具有如下优点与有益效果:
14、1、本发明能够有效提高少数类样本的多样性,并进一步提高分类精度。传统的分类方法在面对长尾分布的图片数据时,往往难以有效地对少数类图片数据进行分类。本发明方法采用mosaic融合技术对长尾数据进行增强,将多数类别样本与其它样本进行多种方式的mosaic融合生成新的样本,丰富少数类样本的特征多样性,同时提高样本空间的线性化程度。
15、2、本发明方法简单易实现,不增加额外成本。本发明方法只需要在训练数据集上进行融合数据增强,借助多数类样本的信息丰富少数类样本信息,不需要额外的数据采样过程。这使得本发明方法在实际数据集中更具可行性和经济性。
16、3、本发明方法能够灵活适应不同的长尾数据集。本发明方法采用mosaic融合技术进行数据增强,该技术可以灵活适应不同类型的长尾数据集。通过调整融合数据增强的方式和比例,可以针对不同长尾数据集的特点进行优化,使得本发明方法具有较强的适用性和泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!