本发明属于辐射源识别,涉及到一种未知雷达波形识别的方法,尤其涉及一种基于蜣螂优化-开集差分分布对齐的未知雷达波形识别方法。
背景技术:
1、雷达信号波形识别,是对信号调制方式进行识别,提取其工作参数和特征参数,从而为进一步完成威胁判定并做出相应的反制措施创造条件。然而,随着现代战争的发展,战场电磁环境日益复杂,战场中不断出现各种新的未知型号的雷达,雷达波形识别面临的挑战越来越大,按照传统的雷达波形识别方法进行处理,识别精准度将急剧下降。与传统雷达波形识别相似,未知雷达波形识别本质是模式分类问题。随着深度学习理论的应用拓展,近年来涌现出了众多基于深度学习的辐射源信号波形识别新算法,展现了优异的性能。目前,基于深度学习的雷达波形识别,用于深度学习网络测试的雷达波形样本,与训练深度学习网络的样本相比,往往采集于同一时间段与空间位置,即两者的波形种类完全相同,数据的特征分布也几乎相同。然而,在真实的战场环境下,一旦测试数据集与训练数据集的特征分布出现较大差异,特别是新型雷达的出现,必将导致深度学习模型的识别效果大幅下降。
2、根据已有的文献发现,当测试数据集与训练数据集的波形特征分布出现较大差异,可采用领域自适应方法进行处理,按照所采用的迁移学习方法,可概括为样本权重迁移方法、特征变换迁移方法、预训练-微调迁移方法和深度对抗网络迁移方法。feng y等在《information(basel)》(2019,11(1):15)上发表的“radar emitter identificationunder transfer learning and online learning”,对于目标域只包含少量标记样本的情况,使用tradaboost方法作为基本学习框架来训练svm,使其可以从源域获得有用的知识,以帮助识别目标域。然而,一旦分布存在较大差异,大量的源域样本将会被降低权重,可能会导致有用信息的丢失。刘剑锋硕士的学位论文《基于深度学习的通信辐射源个体识别关键技术研究》(战略支援部队信息工程大学)中,使用域内可聚类约束和类间紧密性约束,通过对不同信噪比下信号的特征对齐,提取出不同信噪比下“不变”的指纹特征,实现了缺少特定信噪比条件下有标签信号样本场景中的通信辐射源个体识别。基于几何特征的方法,考虑到数据可能具有的空间几何结构,常常能获得简洁有效的表达与效果,可以作为多种方法的特征处理过程。wang g m等在《computer science and application》(2019,9(9),18)发表“radar signal sorting and recognition based on transferred deeplearning”,选用在大规模数据集imagenet上预训练好的卷积神经网络,保存部分预训练的参数,仅需要在雷达信号时频图像的小数据集上微调就可实现迁移。该方法虽然可以取得良好的性能,然而,固定多少层、微调多少层仍然是一个开放的问题。huang k等人在《bulletin of the polish academy of sciences》(technical sciences,2021,69(2))发表“deep adversarial neural network for specific emitter identification undervarying frequency”,提出了一种基于连续小波变换和领域对抗神经网络的方法,当训练数据的载波频率与测试数据的载波频率不同时,该方法具有较好的性能,却需要较长的训练时间。
3、当测试数据集中出现了未知的雷达波形时,可采用开集识别方法进行处理,具体分为基于判别模型和基于生成模型两类。xuhaifeng等人在《7th internationalconference on computer and communications(iccc)》(2021:1420-1425)上发表“atransformer based approach for open set specific emitter identification”,结合改进的transformer和改进的类内分割方法,可以在保持已知类的高精度的同时识别未知类信号。zhao yurui等人在《remote.sensing》(2022.14:22~26)发表文章“multi-classifier fusion for open-set specific emitter identification”,考虑到特征重合会导致对未知设备的错误识别,提出在决策层融合多分类器来提高准确率和召回率,该方法可以避免特征空间的重合,达到较高的准确率和查全率。从判别模型的角度来看,几乎所有现有的开集识别方法都采用基于阈值的分类机制,其选择通常取决于己知类别的知识,由于缺乏来自未知类的可用信息,这不可避免地会招致风险。tan kaiwen等人在《ietradar,sonar&navigation》(2023.17(3):813-829)上发表“dynamic open set specificemitter identification via multi-channel reconstructive discriminantnetwork”,提出了一种基于生成式对抗网络的方法,在通用软件无线电外设近距离通信场景下的真实数据集上进行实验,证明了所提出框架的优越性。然而,对于生成式对抗网络的训练,往往是通过不断迭代的过程,逐步提升识别效率,必然要耗费大量的训练时间,给算法改进以及网络训练带来了诸多压力。
4、上述方法在解决为未知雷达波形识别问题上虽然都能得到相应结果,当测试集的雷达波形种类多于训练集,且提取特征分布不同时,单纯采用领域自适应或者开集识别算法进行处理,将会出现较大误差。对于开集领域自适应问题,fang zhen等人在《ieeetransactions on neural networks and learning systems》(2021.32(10):4309-4322)发表“open set domain adaptation:theoretical bound and algorithm”,对开集领域自适应学习边界进行理论推导,提出了较为新颖的开集差分分布对齐(distributionalignment with open set difference,以下简称daod)算法,多个公开数据集的试验表明,可以较好地处理开集领域自适应的问题。然而,对于daod算法而言,多个超参数的选择,往往依靠先验知识或者试探选取,采用智能算法进行寻优无疑是更为科学、高效的办法。xuejiankai等人在《the journal of supercomputing》(2022.27(10):7305-7336)上发表“dung beetle optimizer:a new meta-heuristic algorithm for globaloptimization”,提出了蜣螂优化算法(dung beetle optimizer,以下简称dbo)其灵感来源于蜣螂的生物行为过程,具有寻优能力强、收敛速度快的特点。
5、因此,需要设计一种新的未知雷达波形识别方法,能够同时兼顾领域自适应和开集两种情形,对于提高未知雷达波形的识别精度具有重要意义。
技术实现思路
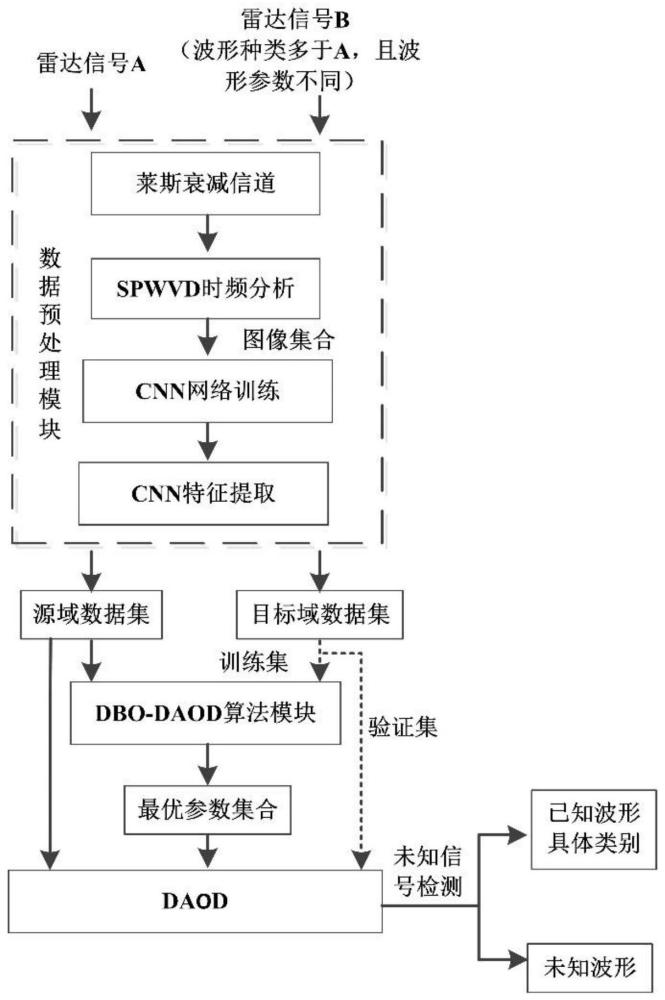
1、针对上述现有技术,本发明要解决的技术问题是,当测试集的雷达波形种类多于训练集,且提取特征分布不同时,如何来提升未知雷达波形的识别精度。为解决上述难题,本发明提出一种基于dbo-daod的未知雷达波形识别方法,将daod算法引入到雷达辐射源识别领域,并使用dbo算法来优化daod开集领域自适应算法,以解决雷达未知波形识别的问题,dbo-daod在未知雷达波形识别领域的实际应用过程如附图1所示。
2、为了实现上述目的,本发明采用的技术方案如下:
3、一种基于蜣螂优化-开集差分分布对齐的未知雷达波形识别方法,包含以下步骤:
4、步骤一:生成源域和目标域对应的雷达时域波形数据集合。目标域雷达信号的种类多于源域,目标域雷达信号的合成方式与源域相同,区别在于两者的波形参数(例如载频、带宽)存在不同。
5、步骤二:搭建莱斯衰落信道模拟信号传输过程。在建立数据集时,为更好地贴近真实环境,以搭建莱斯衰落信道模拟信号传输过程。目标域所采用的莱斯衰落信道模拟方法与源域相同,区别在于所采用的信道参数(例如k-factor)等存在不同。
6、步骤三:获取源域和目标域信号的时频图像集合。利用步骤一至二所获取的源域和目标域时域波形数据集合,通过平滑伪魏格纳-维利分布(smoothed pseudo wigner-ville distribution,spwvd)变换,将其从时域变换到时频域,可获取源域和目标域信号的时频图像集合。
7、步骤四:利用搭建的卷积神经网络(convolutional neural networks,cnn)进行特征提取。分别利用源域和目标域数据对卷积神经网络进行训练,待训练完成后,利用matlab内置的特征提取与激活函数activations,分别对源域时频图像集和目标域时频图像集进行处理,将全连接层进行输出,获取源域数据集和目标域数据集;之后,针对各波形类别,分别选取一定数量的数据构建开集领域自适应的源域数据集、目标域数据集,并且将目标域数据集分为训练集和验证集;其中,源域和训练集数据用于dbo-daod超参数的寻优,源域和验证集数据用于对结果进行检验。
8、步骤五:初始化蜣螂种群,具体为:蜣螂种群规模n,利用daod算法所要使用的最近邻域点数p和λ、σ、ρ、α、γ、阈值t诸多超参数,p和λ、σ、ρ、α、θ、阈值t的最小值、最大值分别合并为数组lb=[αmin,θmin,λmin,σmin,pmin,ρmin,tmin]和ub=[αmax,θmax,λmax,σmax,pmax,ρmax,tmax],种群初始化的公式为:
9、x=lb+(ub-lb)*rand(1,n) (1)
10、步骤六:计算初始化蜣螂种群的目标函数,作为评价daod算法的指标,具体过程为:
11、根据fang zhen等人的理论推导,开集域自适应目标域上的泛化误差,由源域上的经验误差、源域和目标域之间的分布差异以及开集差异所界定,并将开集领域自适应转化为优化问题,其形式如式(2)所示:
12、
13、式中,h*为分类误差最小时的概率函数,h被定义为该函数空间的集合{h=[h1,…,hc+1]t:hc∈hk},为源域上的经验误差项,和分别为源域和目标域之间的边缘分布差异和条件分布差异,为开集差异,mh(sx,tx)为流型正则项,为hk中h函数的平方形式,目的是避免过拟合。λ、γ、α、γ、ρ、σ为超参数,sx代表有标签的源域样本,tx代表无标签的目标域样本,为未知目标分类的先验概率。
14、鉴于目标域样本没有标签,目标域和源域分布差异无法被直接计算,需要借助于伪谱方法来计算。此处,采用开集最近邻方法(open set nearest neighbor for classverification-t,osnncv-t)来获取伪谱。假设s为测试样本,其距离最近的两个点分别为v和u,若v和u的标签皆为yc,则s的伪谱标签为yc;否则,假设||v-s||2≤||u-s||2,计算比率||v-s||2/||u-s||2,如果该值小于一个预先定义的阈值t,0<t<1,则s的伪谱标签与v相同,否则,s被视为未知采样。
15、目标域与源域的分布差异,由式(3)进行计算:
16、tr(βtkmkβ) (3)式中,k是(ns+nt)×(ns+nt)核函数矩阵[k(xi,xj)],xi,xj∈sx∪tx,为mmd矩阵。k选择高斯核函数,具体形式为:
17、
18、式中,核函数宽度r是||a-b||2的中间值,m矩阵中,m0和mc分别为:
19、
20、式中,ns:=|sx|,自适应因子μ,代表边缘分布和条件分布的相对重要性,采用如下方法来估计μ:
21、
22、式中,所预测的目标条件分布是不断变化的,因此,在daod中的每一次迭代中都要重新估算一次μ。
23、假设双向关联矩阵的定义为:
24、
25、式中,sim(xi,xj)为相似性函数(如余弦函数);np(xi)代表相对于xi点的p个近邻点,并且p为超参数。则流型正则化项为:
26、
27、式中,xi,xj∈sx∪tx;l是拉普拉斯矩阵,可以表示为d-w,d为对角阵,并且则mh(sx,tx)可以改写为:
28、tr(βtklkβ) (6)
29、利用矩阵形式对损失函数和开集差分进行表示,标签矩阵为即:
30、
31、
32、标签矩阵表示为
33、当且仅当i=c+1并且xj∈sx,否则
34、则
35、
36、式中,a是一个(ns+nt)×(ns+nt)对角矩阵,如果xj∈sx,则如果xi∈tx,则是一个(ns+nt)×(ns+nt)对角矩阵,如果xi∈sx,则如果xi∈tx,则aii=0,并且|| ||f是frobenius范数。
37、综合公式(3)、(6)、(10),则开集领域自适应的优化问题,可以转化为:
38、
39、
40、由于l(β)中存在负项,不能通过求解方程来直接计算最优解。不过,如果的系数γ<<1,那么,l(β)存在唯一的极小值,即:
41、
42、之后,可求得标签矩阵的预测值为:
43、
44、将代入式(3)、(6)、(10),重复进行迭代计算,直至到达迭代次数tdoad,之后,输出对目标域的预测值
45、为便于后续同闭集算法、领域自适应算法进行结果对比,采用f-measure和accuracy作为评价指标,其定义为:
46、
47、
48、式中,recall和precision分别为:
49、
50、
51、式中,tp、fn、fp、tn分别代表真正、假负、假正和真负;accuracy和f-measure在0~1之间,其值越高,则意味着目标识别系统的性能越好。将预测值与真实的标签进行对比,从而计算出f-measure作为目标函数输出。
52、步骤七:根据步骤六计算得到的初始化蜣螂种群目标函数,求取最大值fbest,并获取对应的种群,作为全局最佳位置xbest。
53、步骤八:利用dbo算法来更新蜣螂种群,具体过程为:
54、在dbo算法中,每个蜣螂种群由滚球蜣螂、繁殖蜣螂、小蜣螂和盗窃蜣螂四个不同的代表组成,各自在算法寻优过程中发挥不同的作用。各类蜣螂的分布比例可以根据实际应用问题来设定,其总数之和与整个种群总数相同。
55、(1)滚球蜣螂
56、滚球蜣螂以太阳为导航以保证粪球在直线路径上滚动,光源强度、风等自然因素会影响滚球蜣螂的行进路线,滚球蜣螂的位置更新可以表示为:
57、xi(t+1)=xi(t)+a×k×xi(t-1)+b×|xi(t)-xw| (14)
58、式中,t代表当前迭代次数;xi(t)表示第t次迭代时第i只蜣螂的位置信息;a是一个自然系数,表示是否偏离原来方向,根据概率法分配为-1或1;k∈(0,0.2)表示偏转系数,b∈(0,1)表示常数,k和b分别设定为0.1和0.3;xw表示全局最差位置,xi(t)-xw用于模拟光强变化。
59、当蜣螂遇到障碍物而不能前进时,它需要通过跳舞来调整自己的方向,从而获得一条新的路线。滚球蜣螂跳舞更新位置的公式定义如下:
60、xi(t+1)=xi(t)+tan(θ)|xi(t)-xi(t-1)| (15)
61、式中,θ∈[0,p]表示偏转角,在θ等于0、p/2或p时,蜣螂的位置不会更新。
62、(2)繁殖蜣螂
63、繁殖蜣螂采用边界选择策略模拟雌性蜣螂产卵区域,产卵区域的定义为:
64、
65、式中,x*表示当前的局部最佳位置;lb*和ub*分别表示产卵区的下限和上限;r=1-t/tmax,tmax表示最大迭代数;lb和ub分别代表优化问题的下限和上限。
66、由式(16)可知产卵区域是动态变化的,因此迭代过程中,繁殖蜣螂的位置也是动态变化的,繁殖蜣螂的位置定义为:
67、bi(t+1)=x*+b1×(bi(t)-lb*)+b2×(bi(t)-ub*) (17)
68、式中,bi(t)是第t次迭代时,第i个繁殖蜣螂的位置信息;b1和b2代表两个大小为1×d的独立随机向量,d表示待优化超参数的个数。
69、(3)小蜣螂
70、小蜣螂出生后在最佳觅食区寻找食物,最佳觅食区的定义为:
71、
72、式中,xb表示当前的局部最佳位置,lbb和ubb分别表示最佳觅食区的下限和上限,其他参数在式(16)中定义。
73、因此,小蜣螂的位置被更新如下:
74、xi(t+1)=xi(t)+c1×(xi(t)-lbb)+c2×(xi(t)-ubb) (19)
75、式中,xi(t)是第t次迭代时,第i只小蜣螂的位置信息;c1表示遵循正态分布的随机数;c2∈(0,1)表示随机向量。
76、(4)盗窃蜣螂
77、盗窃蜣螂会从其他蜣螂那里偷取粪球,从式(18)可以看出,xb是竞争食物的最佳地点,盗窃蜣螂的位置信息更新如下:
78、xi(t+1)=xb+s×g×(|xi(t)-x*|+|xi(t)-xb|) (20)
79、式中,xi(t)第i只盗窃蜣螂在第t次迭代的位置信息,g表示一个遵循正态分布的大小为1×d的随机向量,s表示一个常数值。
80、步骤九:利用doad算法计算更新之后的蜣螂种群的目标函数(方法同步骤六),并计算其局部最大值fbest和局部最佳位置xbest,并且更新全局最大值和全局最佳位置,具体方法为:
81、
82、
83、步骤十:重复步骤八~九,直至到达迭代次数tdbo;之后,输出xbest,即p和λ、σ、ρ、α、θ、阈值t的最优组合。
84、步骤十一:将xbest以及源域数据集、验证集,输入doad算法,求取其预测标签,具体过程同步骤六。
85、与现有技术相比,本发明的有益效果:
86、(1)对于未知雷达波形识别而言,能够同时兼顾开集和领域自适应两种情形,具有较高的识别精度;
87、(2)利用dbo算法对daod算法进行优化,可以输出最优的相关超参数组合,避免依赖于人的经验或者试探获取;
88、(3)可扩展性强,能够适应于多种未知辐射源识别场景。