一种应用于国产GPU环境下的智能识别模型适配方法与流程
本发明属于人工智能和国产化基础平台领域,更为具体地讲,涉及一种应用于国产gpu环境下的智能识别模型适配方法。
背景技术:
1、随着人工智能和大数据技术的发展,智能识别、辅助审核在各类平台、网站资源生产和发布中的应用越来越广泛。目前智能识别技术主要基于英伟达等国外gpu显卡实现,国产芯片、ai加速卡等硬件产品性能相对较低、兼容性较差、适配度较低,因此,虽然寒武纪等国产gpu已经支持主流深度学习框架,但是缺乏和主流ai框架的适配技术手段及对接的软件生态,需要进一步解决指令集支持等问题。
技术实现思路
1、本发明的目的在于将主流深度学习框架开发的人工智能模型适配到国产gpu平台,提供一种应用于国产gpu环境下的智能识别模型适配方法,本发明能够实现充分对国产硬件平台在实际业务需求中的适配性能和可靠性进行评估,确保国产硬件平台能够满足项目需求。结合潜在发展和优化需求,综合考察硬件设备的各方面能力是否能够形成良好支撑。
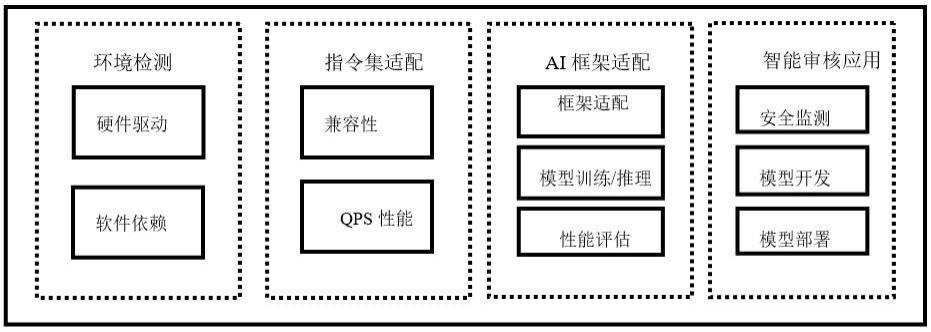
2、本发明提供如下技术方案:一种应用于国产gpu环境下的智能识别模型适配方法,包括以下步骤:
3、s1:硬件设备基础环境检测;
4、s2:指令集业务架构适配;
5、s3:深度学习框架适配;
6、s4:智能识别模型训练调优和推理;
7、s5:智能识别模型性能稳定性提升;
8、s6:智能识别应用验证。
9、所述步骤s1:硬件设备基础环境检测的具体步骤包括:
10、s1.1:适配所述硬件固件和驱动程序,具体方法包括以下步骤:
11、s1.1.a:安装固件和驱动,安装过程中若出现固件或驱动版本过低,下载安装高版本驱动程序;若出现“掉卡”等驱动安装失败问题,重新安装驱动程序;
12、s1.1.b:使用终端命令确认固件和驱动有效安装;
13、s1.2:适配依赖组件库,具体方法包括以下步骤:
14、s1.2.a:源代码获取;
15、s1.2.b:安装能够支持多种目标架构的交叉编译工具;
16、s1.2.c:配置编译选项,通过构建系统来管理编译过程;
17、s1.2.d:运行构建命令编译依赖库,生成目标架构编译的依赖库;
18、s1.2.e:安装编译后的依赖库,通过终端命令确认依赖库有效安装。
19、所述步骤s2:指令集业务架构适配的具体步骤包括:
20、s2.1:指令集业务架构兼容性测试,具体测试方法为:
21、针对业务场景的数据,安装相关分析处理的工具包;启动业务服务,进行测试,通过命令查看相关依赖是否安装成功;若成功安装则通过兼容性测试,去步骤s2.2;
22、否则,则进行相关工具包的适配步骤:1)源码获取;2)配置编译选项;3)生成目标架构的编译库;4)安装测试后去步骤s2.2;
23、s2.2:指令集业务qps性能测试,具体测试方法为:
24、在原平台和目标平台分别使用同一套业务逻辑代码和算法模型,进行业务模块部署;针对业务中的算法和数据,对硬件平台的响应速度和吞吐量进行测试;根据业务需求和测试结果裁定指令集业务qps性能测试结果。
25、所述步骤s3:深度学习框架适配的具体步骤包括:
26、s3.1:选择国产加速平台支持的深度学习框架;
27、s3.2:对主流深度学习框架进行源码编译构建安装;
28、s3.3:根据深度学习框架,运行官方示例demo代码,验证有效性。
29、所述步骤s4:智能识别模型训练调优和推理的具体步骤包括:
30、s4.1:安装智能模型的训练和推理所需的依赖环境;
31、s4.2:针对业务场景,准备数据集,划分好训练集和测试集,生成分类标签;
32、s4.3:在原平台和目标平台上分别进行算法模型实现,模型结构和参数保持一致;
33、s4.4:读入训练数据开始训练,训练完成后保存模型文件;
34、s4.5:加载训练好的智能模型文件,将模型格式转为国产平台支持的格式,封装模型推理接口,修改原平台预处理代码和后处理代码,使用封装的接口进行模型的推理和预测。
35、所述步骤s5:智能识别模型性能稳定性提升的具体步骤包括:
36、s5.1:智能模型性能评估,具体评估方法为:
37、s5.1a:针对业务场景,构建智能模型评估所需要的测试数据集,并上传到不同平台。在不同平台下,使用同一套测试数据、算法模型和评估标准,对需要识别的业务数据进行模型识别测试,统计识别结果。评估标准包含智能模型的精准率、召回率、f1以及map这4个评价指标。其中,精准率和召回率反映识别模型预测的精度和全面度,并通过f1反映综合指标;map则反映多类别预测场景下的识别模型的平均准确率。通过以上评估标准度量不同平台下的识别模型的性能;
38、s5.1b:对同一张图片推理10次,观察推理结果,出现模型输出性能不稳定,并且在测试集上的推理效果差的问题;
39、s5.2:模型输出性能提升,推理效果提升的具体方法有:
40、s5.2a:检查训练数据的质量,确保数据的准确性和充分性。可以通过数据清洗、数据增强等方式来提高数据质量;
41、s5.2b:调整模型的复杂度,避免过拟合。可以通过增加正则化项、减少模型参数等方式来控制模型的复杂度;
42、s5.2c:使用交叉验证等技术来评估模型的性能,避免过拟合。可以将数据集划分为多个训练集和验证集,通过验证集来评估模型的性能;
43、s5.2d:对模型进行调参,优化模型的性能。可以通过网格搜索、随机搜索等方式来寻找最优的超参数组合;
44、s5.2e:增加训练数据量,提高模型的泛化能力。可以通过数据增强、数据合成等方式来增加训练数据量;
45、s5.2f:使用迁移学习等技术来提高模型的泛化能力。可以使用预训练的模型作为基础模型,通过微调等方式来适应新的任务;
46、s5.2g:在测试集上进行模型调优,提高模型的泛化能力。可以使用验证集来评估模型的性能,然后在测试集上进行模型调优;
47、s5.3:性能提升验证:使用双向数据绑定方法对推理队列中的张量进行整合规范;
48、s5.4:重复s5.2和s5.3步骤,进行性能提升验证。
49、所述步骤s6:智能识别应用验证的具体步骤包括:
50、s6.1:源码安全监测,具体方法为:
51、首先针对国产gpu平台的ai计算加速卡,选择支持的深度学习框架版本,然后结合目标业务场景,对开源框架的源码进行安全风险检测,防止漏洞导致安全问题;
52、s6.2:智能模型开发,具体方法包括以下步骤:
53、s6.2.a:对主流的深度学习框架的接口进行封装,实现统一的开发接口;
54、s6.2.b:数据预处理,包括过滤、清洗、增广等;
55、s6.2.c:结合业务数据和需求,构建适合的深度神经网络模型;
56、s6.2.d:初始化模型训练,训练、验证完成后保存模型;
57、s6.3:智能模型部署,具体方法包括以下步骤:
58、s6.3.a:模型迁移:训练和验证后的模型转换为国产硬件平台环境的格式,生成离线模型;
59、s6.3.b:模型优化:根据部署环境的特性,进行模型剪枝,量化,蒸馏等操作以减小模型的大小和提高其在特定硬件上的性能;
60、s6.3.c:部署环境准备:包括安装必要的软件库,配置硬件设备,设置网络连接等;
61、s6.3.d:模型部署:将优化后的模型部署到目标环境中,并进行测试;
62、s6.3.e:模型监控和更新:在模型部署和运行过程中,持续监控其性能和功能,根据需要进行模型更新和优化;
63、s6.3.f:推理应用开发:根据审核业务需求和数据流,开发智能识别应用,调用离线模型自动审核业务中的实际样本,将识别结果传回业务处理流程,将识别结果显示到应用界面。
64、本发明具备以下有益效果:
65、本发明能够实现充分对国产硬件平台在实际应用需求中的适配性能和可靠性进行评估,确保国产硬件平台能够满足项目需求。结合潜在发展和优化需求,综合考察硬件设备的各方面能力是否能够形成良好支撑。
- 还没有人留言评论。精彩留言会获得点赞!